
Shard-Query is an open source tool kit which helps improve the performance of queries against a MySQL database by distributing the work over multiple machines and/or multiple cores. This is similar to the divide and conquer approach that Hive takes in combination with Hadoop. Shard-Query applies a clever approach to parallelism which allows it to significantly improve the performance of queries by spreading the work over all available compute resources. In this test, Shard-Query averages a nearly 6x (max over 10x) improvement over the baseline, as shown in the following graph:
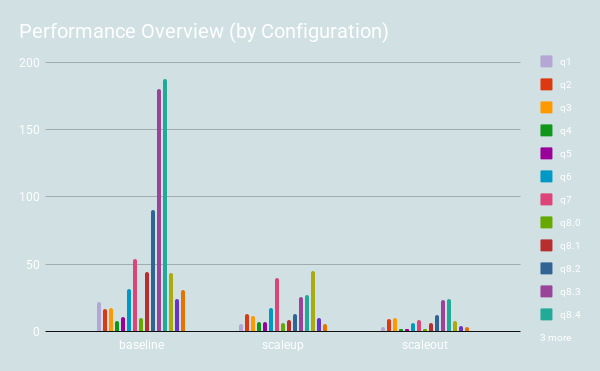
One significant advantage of Shard-Query over Hive is that it works with existing MySQL data sets and queries. Another advantage is that it works with all MySQL storage engines.
This set of benchmarks evaluates how well Infobright community edition (ICE) performs in combination with Shard-Query.
It was important to choose a data set that was large enough to create queries that would run for a decent amount of time, but not so large that it was difficult to work with. The ontime flight performance statistics data, available online from the United States Bureau of Transportation Statistics (BTS) made a good candidate for testing, as it had been tested before:
Another MPB post
Lucid DB testing
The raw data is a completely denormalized schema (single table). In order to demonstrate the power of Shard-Query it is important to test complex queries involving joins and aggregation. A star schema is the most common OLAP/DW data model, since it typically represents a data mart. See also: “Data mart or data warehouse?”. As it is the most common data model, it is desirable to benchmark using a star schema, even though it involves work to transform the data.
Transforming the data was straightforward. I should note that I did this preprocessing with the MyISAM storage engine, then I dumped the data to tab delimited flat files using mysqldump. I started by loading the raw data from the BTS into a single database table called ontime_stage.
Then, the airport information was extracted:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
create table dim_airport( airport_id int auto_increment primary key, unique key(airport_code) ) as select Origin as `airport_code`, OriginCityName as `CityName`, OriginState as `State`, OriginStateFips as `StateFips`, OriginStateName as `StateName` , OriginWac as `Wac` FROM ontime_stage UNION select Dest as `airport_code`, DestCityName as `CityName`, DestState as `State`, DestStateFips as `StateFips`, DestStateName as `StateName` , DestWac as `Wac` FROM ontime_stage; |
After extracting flight/airline and date information in a similar fashion, a final table ontime_fact is created by joining the newly constructed dimension table tables to the staging tables, omitting the dimension columns from the projection, instead replacing them with the dimension keys:
|
1 2 3 4 5 6 7 8 9 10 |
select dim_date.date_id, origin.airport_id as origin_airport_id, dest.airport_id as dest_airport_id, dim_flight.flight_id, ontime_stage.TailNum, ... from ontime_stage join dim_date using(FlightDate) join dim_airport origin on ontime_stage.Origin = origin.airport_code join dim_airport dest on ontime_stage.Dest = dest.airport_code join dim_flight using (UniqueCarrier,AirlineID,Carrier,FlightNum); |
The data set contains ontime flight information for 22 years, which can be confirmed by examining the contents of the date dimension:
|
1 2 3 4 5 6 7 8 9 |
mysql> select count(*), min(FlightDate), max(FlightDate) from dim_dateG *************************** 1. row *************************** count(*): 8401 min(FlightDate): 1988-01-01 max(FlightDate): 2010-12-31 1 row in set (0.00 sec) |
The airport dimension is a puppet dimension. It is called a puppet because it serves as both origin and destination dimensions, being referenced by origin_airport_id and destination_airport_id in the fact table, respectively. There are nearly 400 major airports included in the data set.
|
1 2 3 4 5 6 7 |
mysql> select count(*) from dim_airport; +----------+ | count(*) | +----------+ | 396 | +----------+ 1 row in set (0.00 sec) |
The final dimension is the flight dimension, which contains the flight numbers and air carrier hierarchies. Only the largest air carriers must register and report ontime information with the FAA, so there are only 29 air carriers in the table:
|
1 2 3 4 5 6 7 |
mysql> select count(*), count(distinct UniqueCarrier) from dim_flightG *************************** 1. row *************************** count(*): 58625 count(distinct UniqueCarrier): 29 1 row in set (0.02 sec) |
Each year has tens of millions of flights:
|
1 2 3 4 5 6 7 |
mysql> select count(*) from ontime_one.ontime_fact; +-----------+ | count(*) | +-----------+ | 135125787 | +-----------+ 1 row in set (0.00 sec) |
For this benchmark, a test environment consisting of a single commodity database server with 6 cores (+6ht) and 24GB of memory was selected. The selected operating system was Fedora 14. Oracle VirtualBox OSE was used to create six virtual machines, each running Fedora 14. Each of the virtual machines was granted 4GB of memory. A SATA 7200rpm RAID10 battery backed RAID array was used as the underlying storage for the virtual machines.
Baseline:
The MySQL command line client was used to execute the a script file containing the 11 queries. This same SQL script was used in the Shard-Query tests. For the baseline, the results and response times were captured with the T command. The queries were executed on a single database schema containing all of the data. Before loading, there was approximately 23GB of data. After loading, ICE compressed this data to about 2GB. The test virtual machine was assigned 12 cores in this test.
Scale-up:
Shard-Query was given the following configuration file, which lists only one server. A single schema (ontime_one) contained all of the data. The test virtual machine was assigned 12 cores for this test. The same VM was used as the previous baseline test. This VM was rebooted between tests. A SQL script was fed to the run_query.php script and the output was captured with the ‘tee’ command.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ cat one.ini [default] user=mysql db=ontime_one password= port=5029 column=date_id mapper=hash gearman=127.0.0.1:7000 inlist=* between=* [shard1] host=192.168.56.102 |
Scale-out
In addition to adding parallelism via scale-up, Shard-Query can improve performance of almost all queries by spreading them over more than one physical server. This is called “scaling out” and it allows Shard-Query to vastly improve the performance of queries which have to examine a large amount of data. Shard-Query includes a loader (loader.php) which can be used to either split a data into multiple files (for each shard, for later loading) or it can load files directly, in parallel, to multiple hosts.
Shard-Query will execute queries in parallel over all of these machines. With enough machines, massive parallelism is possible and very large data sets may be processed. As each machine examines only a small subset of the data, performance can be improved significantly:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
$ cat shards.ini [default] user=mysql db=ontime password= port=5029 column=date_id mapper=hash gearman=127.0.0.1:7000 inlist=* between=* [shard1] host=192.168.56.101 db=ontime [shard2] host=192.168.56.102 db=ontime [shard3] host=192.168.56.103 db=ontime [shard4] host=192.168.56.105 db=ontime [shard5] host=192.168.56.106 db=ontime [shard6] host=192.168.56.104 db=ontime |
In this configuration, each shard has about 335MB-350MB of data (23GB raw data, compressed to about 2GB total data. then spread over six servers). Due to ICE limitations, the data was split before loading. The splitting/loading process will be described in another post.
Shard-Query was tested with the simple single table version of this data set in a previous blog post. Previous testing was limited to a subset of Vadim’s test queries (see that post). As this new test schema is normalized, Vadim’s test queries must be modified to reflect the more complex schema structure. For this benchmark each of the original queries has been rewritten to conform to the new schema, and additionally two new test queries have been added. To model real world complexity, each of the test queries feature at least one join, and many of the filter conditions are placed on attributes in the dimension tables. It will be very interesting to test these queries on various engines and databases.
Following is a list of the queries, followed by a response time table recording the actual response times for each query. The queries should be self-explanatory.
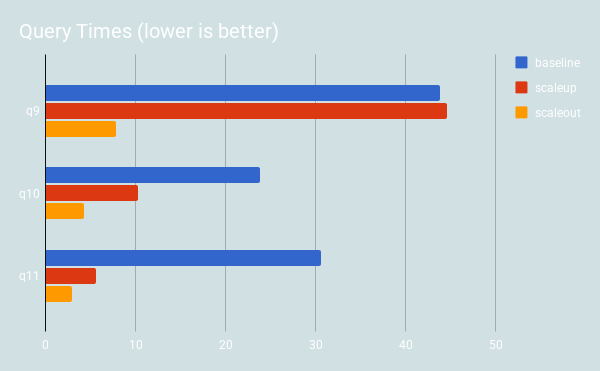
You will notice that Shard-Query is faster in nearly every case. The performance of the queries is improved significantly by scaling out, even more so than scaling up, because additional parallelism is added beyond what can be exploited by scale up. Scale up can improve query performance when there is enough resources to support the added parallelism, and when one of the the following are in used in the query: BETWEEN or IN clauses, subqueries in the FROM clause, UNION or UNION ALL clauses. If none of those features are used, then parallelism can’t be added. Q9 is an example of such a query.
.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Q1 SELECT DayOfWeek, count(*) AS c from ontime_fact JOIN dim_date using (date_id) WHERE Year BETWEEN 2000 AND 2008 GROUP BY DayOfWeek ORDER BY c DESC; -- Q2 SELECT DayOfWeek, count(*) AS c from ontime_fact JOIN dim_date using (date_id) WHERE DepDelay>10 AND Year BETWEEN 2000 AND 2008 GROUP BY DayOfWeek ORDER BY c DESC; -- Q3 SELECT CityName as Origin, count(*) AS c from ontime_fact JOIN dim_date using (date_id) JOIN dim_airport origin ON origin_airport_id = origin.airport_id WHERE DepDelay>10 AND Year BETWEEN 2000 AND 2008 GROUP BY 1 ORDER BY c LIMIT 10; |
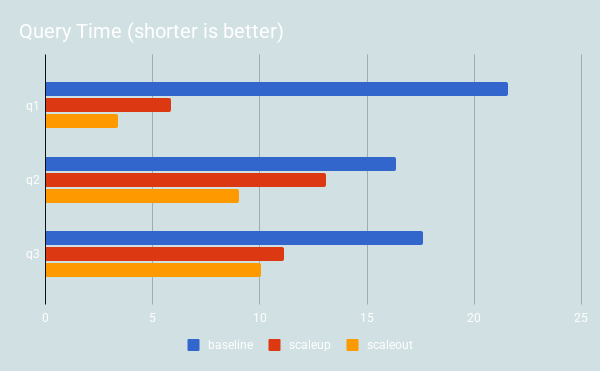

The next queries show how performance is improved when Shard-Query adds parallelism when “subqueries in the from clause” are used. There are benefits with both “scale-up” and “scale-out”, but once again, the “scale-out” results are the most striking.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
-- Q4 SELECT Carrier, count(*) as c from ontime_fact JOIN dim_date using (date_id) join dim_flight using(flight_id) WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier ORDER BY c DESC; -- Q5 SELECT t.Carrier, c, c2, c*1000/c2 as c3 FROM (SELECT Carrier, count(*) AS c from ontime_fact join dim_date using(date_id) join dim_flight using(flight_id) WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier) t JOIN (SELECT Carrier, count(*) AS c2 from ontime_fact join dim_date using(date_id) join dim_flight using(flight_id) WHERE Year=2007 GROUP BY Carrier) t2 ON (t.Carrier=t2.Carrier) ORDER BY c3 DESC; -- Q6 SELECT t.Year, c1 / c2 as ratio FROM (select Year, count(*)*1000 as c1 from ontime_fact join dim_date using (date_id) WHERE DepDelay>10 GROUP BY Year) t JOIN (select Year, count(*) as c2 from ontime_fact join dim_date using (date_id) WHERE DepDelay>10 GROUP BY Year) t2 ON (t.Year=t2.Year); -- Q7 SELECT t.Year, c1 / c2 as ratio FROM (select Year, count(Year)*1000 as c1 from ontime_fact join dim_date using (date_id) WHERE DepDelay>10 GROUP BY Year) t JOIN (select Year, count(*) as c2 from ontime_fact join dim_date using (date_id) GROUP BY Year) t2 ON (t.Year=t2.Year); |
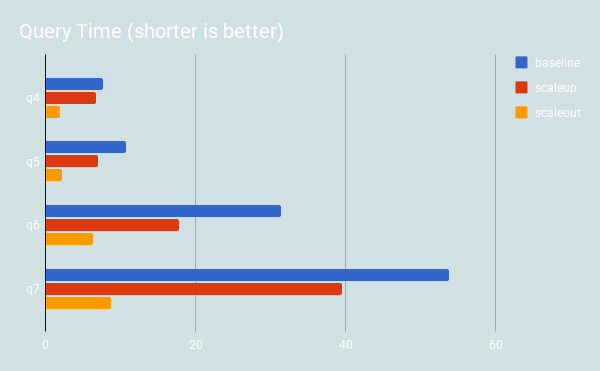

The performance of the following queries depends on the size of the date range:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
-- Q8.0 SELECT dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) WHERE Year BETWEEN 2001 and 2001 GROUP BY dest.CityName ORDER BY 2 DESC; -- Q8.1 SELECT dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) WHERE Year BETWEEN 2001 and 2005 GROUP BY dest.CityName ORDER BY 2 DESC; -- Q8.2 SELECT dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) WHERE Year BETWEEN 2001 and 2011 GROUP BY dest.CityName ORDER BY 2 DESC; -- Q8.3 SELECT dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) WHERE Year BETWEEN 1990 and 2011 GROUP BY dest.CityName ORDER BY 2 DESC; -- Q8.4 SELECT dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) WHERE Year BETWEEN 1980 and 2011 GROUP BY dest.CityName ORDER BY 2 DESC; |
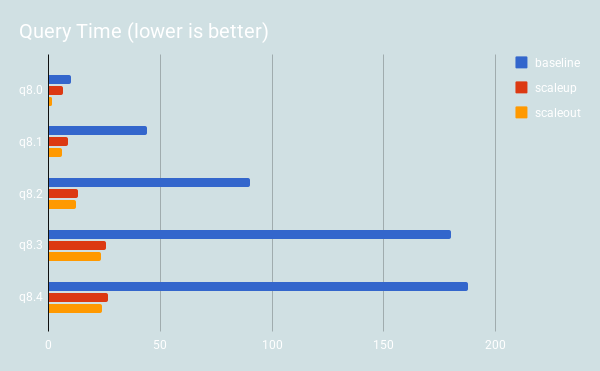

Finally, Shard-Query performance continues to improve when grouping and filtering is used. Again, notice Q9. It doesn’t use any features which Shard-Query can use to add parallelism. Thus, in the scale up configuration it does not perform any better than the baseline, and actually performed just a little worse. Since scale out splits the data between servers, it performs about 6x better as the degree of parallelism is controlled by the number of shards.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
-- Q9 select Year ,count(Year) as c1 from ontime_fact JOIN dim_date using (date_id) group by Year; -- Q10 SELECT Carrier, dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) JOIN dim_flight using (flight_id) WHERE Year BETWEEN 2009 and 2011 GROUP BY Carrier,dest.CityName ORDER BY 3 DESC; -- Q11 SELECT Year, Carrier, dest.CityName, COUNT( DISTINCT origin.CityName) from ontime_fact JOIN dim_airport dest on ( dest_airport_id = dest.airport_id) JOIN dim_airport origin on ( origin_airport_id = origin.airport_id) JOIN dim_date using (date_id) JOIN dim_flight using (flight_id) WHERE Year BETWEEN 2000 and 2003 AND Carrier = 'AA' GROUP BY Year, Carrier,dest.CityName ORDER BY 4 DESC; |

The divide and conquer approach is very useful when working with large quantities of data. Shard-Query can be used with existing data sets easily, improving the performance of queries significantly if they use common query features like BETWEEN or IN. It is also possible to spread your data over multiple machines, scaling out to improve query response times significantly.
These queries are a great test of Shard-Query features. It is currently approaching RC status. If you decide to test it and encounter issues, please file a bug on the bug tracker. You can get Shard-Query (currently in development release form as a checkout from SVN) here: Shard-Query Google code project
Justin Swanhart, the author of this article is also the creator and maintainer of Shard-Query. The author has previously worked in cooperation with Infobright, including on benchmarking. These particular tests were performed independently of Infobright, without their knowledge or approval. Infobright was, however, given the chance to review this document before publication, as a courtesy. All findings are represented truthfully, transparently, and without any intended bias.





input:
select a expr1, count(distinct b) expr2, count(*) expr3
from a
join b
where a.id = b.a_id
group by a;
rewrite (these results go into #tmp)
select a expr1, b expr2, count(*) expr3
from a
join b
where a.id=b.a_id
group by a,b;
final query:
select expr1, count(distinct expr3) expr2, sum(expr3) expr3
from #tmp
group by expr1;
Any COUNT(distinct), STDDEV,VARIANCE,SUM(DISTINCT), etc are handled this way.
I do not understand how do you handle count(distinct *) in your shard queries?
Hi Jeff,
I plan on testing the Wikipedia V2 data (>2TB data) across multiple nodes without normalizing the flat files. I want to point out the ICE performance is already VERY GOOD on this data set. I’m not trying to say ICE is slow here, in fact it is impressively fast, but single threaded. I just help an already fast tool operate faster.
My next posts will focus on ICE versus InnoDB on up to 20 nodes in EC2 on the BTS star schema data set.
I may integrate Vectorwise storage node support before I do the Wikistat V2 test. That way I can have an ICE versus Vectorwise shootout. This also gives me an opportunity to investigate ICE, Vectorwise and Shard-Query performance on large data sets.
Good to read. Should be interesting.
I didn’t miss your point. I’ve already loaded the data on InnoDB and I’ll post some results soon.
Justin, I think you missed my point. I was wondering how a well configured schema and plain InnoDB would do. That might give some indication of when it’s worthwhile considering tools like these.
This is just one benchmark. There are tons of possibilities. Most existing BI users will have a star schema, and this is a kind of worst case performance test given the schema. A fully denormalized table will be even faster.
Thanks, Justin, for posting your findings; I find them very interesting. I’m curious to see what happens if we denormalize the dataset and condense to just one or potentially two tables.
I know you mention Star Schema is the “proper benchmark,” but I would want to understand the boost in performance by just structuring the data in the best format for the datastore.Let me know if you’re interested in trying Shard on a denormalized set.
All the best, and thanks again for getting this info posted!
Jeff
Infobright Community Manager for ICE
I had wondered what it would be like to do something like this, but now you have written it. Thanks for your work!
Rick,
Because of the nature of the benchmark, the schema prevents easy partition elimination. A more realistic schema would use natural keys for the dates 19990101 and then the date_id (which is natural) could be added as predicates for partition elimination.
And thanks!
Some of those test cases are a good examples of why _not_ to normalize dates.
Anyway, bravo to your scaling technique.
Justin,
Thanks for flagging this. I assumed infinidb community edition does not have scale out features but is available under GPL instance. Now checking out “Calpont Open Source Licence Agreement” I see calling it Open Source is a joke. This is a lot more close to Microsoft’s Shared Source where you could look at the code but not do any useful stuff with it.
Peter,
I didn’t test InfiniDB because the license is not compatible with typical Shard-Query usage. It requires binding InfiniDB to a single processor:
“The Program may be used in development and test deployments with a maximum number of one instance per server utilizing the full computing capacity of the server. However, if you wish to use the Program in a production deployment, you may use the Program for your own internal business purposes only (and not for distribution or redistribution to others) with a maximum number of one instance of the Program per server, and you may only utilize the processing capacity of one physical CPU present within that server. If your server has more than one physical CPU, the Program may be used in production under this License only on one CPU of the server. If you make use of virtualization, resources available to the Program must not exceed the proportional resources available through one CPU. For example and purposes of illustration only, if your server has four (4) physical CPUs, a maximum of 25% of available computing resources may be allocated to the Program. If your intended use of the Program differs from the terms of this License, or you wish to distribute the Program for production use by others, contact Calpont regarding our InfiniDB enterprise licensing program.”
Use of InfiniDB in EC2 at all seems to violate the license, since the end user can not ensure that a single EC2 physical host does not dedicated more than 25% of CPU usage to InfiniDB users.
I can test it on small instances if you think it is a good idea. Any larger instances feature more than one core, so their compute units are wasted.
Also, in a column store, columns that are not projected are not read from disk. It does not matter how big each row is, if you only access a subset of the columns.
Hi James,
1>
For the storage engine, BRIGHTHOUSE was used. This is the Infobright Community Edition storage engine.
2>
The data compression is automatic. Infobright is a column store which spreads data into packs, and these packs are RLE compressed. It includes a data dictionary of sorts and it uses “rough set” (http://www.infobright.org/forums/viewthread/113/) theory to eliminate data packs to examine.
3>
ICE does not support indexes, so there were no indexes on the table. I did not do any tuning. I simply installed the ICE RPM and loaded my data.
4>
The configuration you suggest is indeed possible, and I’ll fully investigate this in my next blog post, where I show how flexible Shard-Query is in its configuration options. The virtual machines have little overhead, because I have a processor (i970) which supports native virtualization.
5> The airport dimension contains only 400 or so rows. I should add the ‘Lookup’ comment to these varchar columns, but ICE will handle them just fine. After compression each node contains only a few hundred MEGABYTES of data.
I have no problem testing other storage engines. I’m currently working on building an EC2 VM based on the ICE EC2 VM (http://www.infobright.org/Blog/Entry/ice_3.5.2_p1_on_the_amazon_ec2_cloud) , but containing the raw data if you want to load on another storage engine, or test your own queries over the data.
What I wonder about are these things:
1. Which storage engine was used. Looks like InnoDB from past tests, and using partitioning. Makes me wonder how much of the InfoBright size reduction was effectively easy normalisation.
Makes me wonder how much of the InfoBright size reduction was effectively easy normalisation.
2. What part of the benefit came from compressing the data to one tenth of its original size and how InnoDB’s compression would have compared.
3. Which indexes were present on the table, because the queries look like natural ones for very effective covering indexes. Not always possible but it would be interesting to see how some general tuning work did in comparison because many applications have only a few queries to tune, rather than being truly any column at any time queries.
4. Why virtual servers were used instead of multiple instances of MySQL on one, which generally has lower overhead.
5. What the benefit would have been from splitting the data further into shorter rows to improve cache hit rates. I tend to grimace when I see 100 character varchars in frequently queried tables without covering indexes. StateName VARCHAR(100) in a commonly queried table? A bad joke for anyone who cares about performance of queries.
To some extent these questions are missing the point about generic star schema queries that you’re really looking at but it’s interesting to see what can be done without having to move data around, just by normal tuning.
Maybe someone else at Percona would have some fun using those alternative approaches so it’s a friendly bit of internal competition between different ways of optimising things?
I’ll have to test with 20 machines. This is the maximum I can spin up at once in EC2.
I’ve started the splitter on my machine to spread the data over 50 shards. The data, compressed by gzip, is about 3.2GB, so it is easy to move into the cloud. I’ll only need a few hours for the test. I’ll post another blog post as a followup afterwards.
Justin,
These are great performance gains. I’m wondering how far this can scale can we get say 50 EC2 instances and scale the data against them ?
I’m also wondering how it compares in terms of performance with things like InfiniDB and Hive
‘@Justin
This looks very interesting, but one question. How much latency/overhead does Gearman add? In the case of a query that takes 20 seconds (or minutes or hours), I could see how parallelizing it in this way in coordination with Gearman would be awesome for the BI space where something that’s slow would then become almost instant.
But what about a 2 second query you want to speed up to 0.2s? That would be more akin to the retail space where some sort of query just can’t be solved in a single-threaded space and you need to throw hardware at it? So why not just spawn N queries and block until they all return?
Is this reduced form of Shard-Query possible?
Hi Jaimie,
You can run Gearman on the local host which reduces latency. That being said, Shard-Query has to do query parsing so there is a lower limit on the performance of a single query of a few milliseconds regardless of the query. Shard-Query is really designed for a sharded architecture or a shared-nothing BI environment. The Gearman queue also provides a kind of connection pool via gearman workers which prevent Shard-Query from overloading the servers with too many parallel queries at once.
hello Swanhart
i successfully have written data using write.php
but i can not read data using read.php
i print ‘php read.php’ in command line
output show program is blocked
why?
output:
PHP Notice: Undefined property: ShardQuery::$broadcast_query in /home/libo/shard-query-read-only/include/shard-query.php on line 145
Notice: Undefined property: ShardQuery::$broadcast_query in /home/libo/shard-query-read-only/include/shard-query.php on line 145
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 169
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 169
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 173
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 173
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 247
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 247
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 169
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 169
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 173
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 173
PHP Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 247
Strict Standards: Resource ID#28 used as offset, casting to integer (28) in /usr/local/lib/php/Net/Gearman/Client.php on line 247
write.php script’s content:
array(
‘host’=>’192.168.1.211’,
‘user’=>’root’,
‘password’=>”,
‘db’=>’test’,
‘port’=>3306
),
‘shard2’ => array(
‘host’=>’192.168.1.101’,
‘user’=>’root’,
‘password’=>”,
‘db’=>’test’,
‘port’=>3306
)
);
$params = array(‘gearman’=>’localhost:4730’);
$mapper = new HashShardKeyMapper($shards);
$mapper->add_column(‘col1’);
$shard_query = new ShardQuery($shards,$params);
$shard_query->set_partition_info(‘col1′, array($mapper,’map’));
$sql = “INSERT INTO t1 VALUES(1,2),(2,3),(3,4),(4,5),(5,6),(6,7),(7,8),(8,9)”;
$shard_query->query($sql);
?>
read.php script’s content:
array(
‘host’=>’192.168.1.211’,
‘user’=>’root’,
‘password’=>”,
‘db’=>’test’,
‘port’=>3306
),
‘shard2’ => array(
‘host’=>’192.168.1.101’,
‘user’=>’root’,
‘password’=>”,
‘db’=>’test’,
‘port’=>3306
)
);
$params = array(‘gearman’=>’localhost:4730’);
$mapper = new HashShardKeyMapper($shards);
$mapper->add_column(‘col1’);
$shard_query = new ShardQuery($shards,$params);
$shard_query->set_partition_info(‘col1′, array($mapper,’map’));
$sql = “select col1,col2 from t1 where col1 in (1,2)”;
$stmt = $shard_query->query($sql);
if(!$stmt || $shard_query->error) {
print_r($shard_query->error);
}
if($stmt) {
while($row = $shard_query->my_fetch_assoc($stmt)) {
print_r($row);
}
}
?>