
Disclaimer: The following blog post does not try to provide a solution for split-brain situations, and the example provided is for demonstrative purposes only. Inconsistencies resulting from a split-brain scenario might possibly be more complex than the one shown, so do not use the following example as a complete guide.
 What is Split-Brain?
What is Split-Brain?A split-brain scenario is the result of two data sets (which were originally synced) losing the ability to sync while potentially continuing to receive DMLs over the same rows and ids on both sides. This could have consequences such as data corruption or inconsistencies where each side has data that does not exist on the other side.
For example before split-brain:

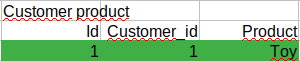
After split-brain:
Node1:


Node2:


It can be seen that after the split-brain scenario there are many differences between the nodes:
Trying to merge all the rows will result in id collision and inconsistencies.
The most typical reason why split-brain occurs is when an async cluster topology loses connectivity and each node continues to give service independently, but other example cases are:
Under the split-brain scenario, there are many inconsistencies that cannot be automatically merged. If restoring, information from one node to the other will lose the changes that occurred on the latter node, and if trying to merge, many issues arise, for instance, the above example:
Because of the above, fixing a split-brain scenario will depend on business rules to decide which rows to keep/discard and would result in a manual job to decide for every inconsistency.
When there is a network issue that results in a split-brain situation and as per the CAP theorem, it’s not possible to assure both Consistency and Availability, having to prioritize one over the other.
In the case of favoring Consistency, using Percona XtraDB Cluster allows the primary component (if there is one) to keep serving data, while the non-primary component refuses to operate. If using automatic failover solutions such as Orchestrator, it should be configured so that writes only go to one node, and the promotion of slave only occurs if the slave was up to date at the moment the network failed. If it’s not possible to guarantee data consistency, then nodes should refuse to work.
In case the service needs to be maintained under split-brain scenarios, inconsistencies will arise, but something which can be done to avoid having duplicate ids is using different auto_increment_increment and auto_increment_offset on each server so that, for example, server A ids are even numbers and server B ids are odd numbers.
Updates and deletes must be resolved case by case.
As previously shown, if writes occur in different nodes after a split-brain, merging the rows in a consistent way can be difficult. The procedure is manual and cumbersome as rows to be kept have to be checked one by one, and criteria for deciding inconsistencies should be based on business logic.
If only one of the nodes received writes (and provided all required variables are enabled beforehand and binary logs are available), there is a tool called MySQL rewind which can help in reverting the changes on the changed node compared to the original node. The tool has some limitations listed on the official documentation but it’s very useful provided the requirements are met.
In case two (or more) nodes have received writes after split-brain, the merge procedure will be more complex. A high-level procedure on how to fix inconsistencies would be as follows:
First, backup both databases. Then identify which rows are different on each cluster by comparing tables from both nodes. If you have tables with timestamps of creation/edition it might greatly help to identify which rows were updated/inserted after split-brain scenario started, otherwise the best would be to chose one of the databases as the source of truth, and work on the other to identify the differences, while merging the changes one by one and according to business rules.
After merging the data and in case of adding ids, there might be a gap in the ids resulting in a waste of ids, in which case dumping and reloading the table might be a good idea to remove the gaps.
Business logic must decide in advance how to react under split-brain scenarios – whether to favor consistency or availability – by comparing the consequences of losing service vs. the cost and difficulty of data merging after the split-brain is over.




