
 I find myself discussing and explaining sychronous_commit with many PostgreSQL users, especially with novice users. So, I thought of noting down all the key points as a blog post which will be useful for more users. Recently I got an opportunity to talk about some related topics in our PostgreSQL Percona Tech Days.
I find myself discussing and explaining sychronous_commit with many PostgreSQL users, especially with novice users. So, I thought of noting down all the key points as a blog post which will be useful for more users. Recently I got an opportunity to talk about some related topics in our PostgreSQL Percona Tech Days.
This is the parameter by which we can decide when a transaction-commit can be acknowledged back to the client as successful.
So this parameter is not just about synchronous standbys, but it has a wider meaning and implication which is useful for standalone PostgreSQL instances as well. To better understand, we should look at the overall WAL record propagation and various stages from which a commit confirmation is acceptable. This allows us to opt for varying levels of durability for each transaction. The lesser the durability selection, the faster the acknowledgment, which improves the overall throughput and performance of the system.
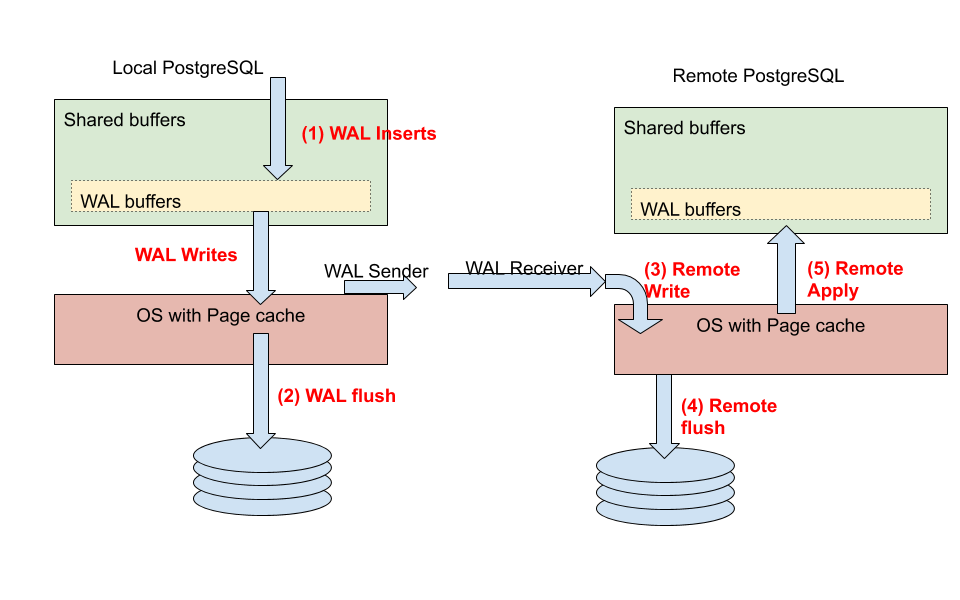
PostgreSQL WAL (Write Ahead Log) is the record of changes/activities on the Primary side and can be considered as a journal/ledger of the changes happening in the database. The following diagram shows the flow of WAL propagation in a local primary PostgreSQL instance and a remote hot standby instance.
[porto_content_box]PostgreSQL uses internal function pg_pwrite() to write into WAL segments, which internally uses write() system call which does not guarantee that that the data is flushed to disk. To complete the flush, another function issue_xlog_fsync() is called, which issues the appropriate kind of fsync based on the parameter (GUC): wal_sync_method .[/porto_content_box]
The above diagram shows all the 5 major stages.
Corresponding accepted values for synchronous_commit are as follows:
By selecting the appropriate values for the parameter, we can choose when the acknowledgment should come back. If there are no synchronous standbys ( synchronous_standby_names is empty) the settings of synchronous_commit to on, remote_apply, remote_write, and local all provide the same synchronization level: transaction commits only wait for local flush to disk.
One of the frequently asked questions in this area is:
“How much data we lose if we opt for full asynchronous commit (synchronous_commit = off)?”
The answer is slightly complex, and it depends on wal_writer_delay settings. By default it is 200ms. That means WALs will be flushed in every wal_writer_delay to disk. The WAL writer periodically wakes up and calls XLogBackgroundFlush(). This checks for completely filled WAL pages. If they are available, it writes all the buffers up to that point. So under good load condition, WAL writer writes whole buffers. On a low-load condition where full pages are not found, everything up to last asynchronous commit will be flushed.
If more than wal_writer_delay has passed, or more than wal_writer_flush_after blocks have been written since the last flush, WAL is flushed up to the current location. This arrangement guarantees that an async commit record reaches disk after at most two times wal_writer_delay after the transaction completes. However, PostgreSQL writes/flushes full buffers in a flexible way, and this is to reduce the number of writes issued under high load when multiple WAL pages are filled per WAL writer cycle. In concept, this makes the worst-case delay up to three wal_writer_delay cycles.
So the answer, in a simple format, is:
The loss will be less than two times the wal_writer_delay in most cases. But it can be up to three times in a worst-case.
When we discuss parameters and their values, many users think about setting sychronous_commit globally at the instance level. But the real power and usage come when it is scoped properly at different levels. Changing it at the instance level is not desirable.
PostgreSQL allows us to have this setting at varied scope in addition to various values.
|
1 |
SET LOCAL synchronous_commit = 'remote_write'; |
|
1 |
SET synchronous_commit = 'remote_write'; |
|
1 2 |
ALTER USER trans_user SET synchronous_commit= ON; ALTER USER report_user SET synchronous_commit=OFF; |
|
1 |
ALTER DATABASE reporting SET synchronous_commit=OFF; |
|
1 2 |
ALTER SYSTEM SET synchronous_commit=OFF; SHOW synchronous_commit; |
Migration: It is very common to see large data movement across systems when there are migrations happening, and the right selection of synchronous_commit or even turning it off will be of great value for reducing the overall migration time.
Data loading: In data warehouse systems/reporting systems, there could be large data load happening, and turning off the synchronous_commit will give a big boost by reducing the overhead of repeated flushes.
Audit and logging: Even in a critical system with critical transactions, only a certain portion of the transaction can be very critical – which a business wants to be available – on the standby side before acknowledging the commit. But there will be associated logging and auditing information recording. Very selective opt-in for synchronous standby commits can yield very high benefits.
Unlock PostgreSQL Expertise: Download the Percona Support for PostgreSQL datasheet to learn more!
A quick test using pgbench could help to verify the overhead of different levels of commit synchronization in a specific environment. Overall, we should expect a performance drop as we increase the level of synchronization requirement. Environmental factors like latency in fsync to local disk, network latency, load on the standby server, contention at the standby, overall replication volume, disk performance at standby server, etc., will be affecting the overhead and performance.
Even completely turning off the synchronous_commit won’t result in database corruption, unlike fsync.
Understanding the overall WAL propagation can help you to understand the replication delays and information from pg_stat_replication view.
The performance of a system is all about eliminating unwanted, avoidable overheads without sacrificing what is really important. I have seen a few power users of PostgreSQL who have a well-tuned system for the PostgreSQL database by making use of synchronous_commit features very effectively and selectively. I hope this article will help those who are still not using it and looking at fine-tuning opportunities for higher performance or durability
Our white paper “Why Choose PostgreSQL?” looks at the features and benefits of PostgreSQL and presents some practical usage examples. We also examine how PostgreSQL can be useful for companies looking to migrate from Oracle.




