
 As some of you likely know, I have a favorable view of ZFS and especially of MySQL on ZFS. As I published a few years ago, the argument for ZFS was less about performance than its useful features like data compression and snapshots. At the time, ZFS was significantly slower than xfs and ext4 except when the L2ARC was used.
As some of you likely know, I have a favorable view of ZFS and especially of MySQL on ZFS. As I published a few years ago, the argument for ZFS was less about performance than its useful features like data compression and snapshots. At the time, ZFS was significantly slower than xfs and ext4 except when the L2ARC was used.
Since then, however, ZFS on Linux has progressed a lot and I also learned how to better tune it. Also, I found out the sysbench benchmark I used at the time was not a fair choice since the dataset it generates compresses much less than a realistic one. For all these reasons, I believe that it is time to revisit the performance aspect of MySQL on ZFS.
In 2018, I reported ZFS performance results based on version 0.6.5.6, the default version available in Ubuntu Xenial. The present post is using version 0.8.6-1 of ZFS, the default one available on Debian Buster. Between the two versions, there are in excess of 3600 commits adding a number of new features like support for trim operations and the addition of the efficient zstd compression algorithm.
ZFS 0.8.6-1 is not bleeding edge, there have been more than 1700 commits since and after 0.8.6, the ZFS release number jumped to 2.0. The big addition included in the 2.0 release is native encryption.
The classic sysbench MySQL database benchmarks have a dataset containing mostly random data. Such datasets don’t compress much, less than most real-world datasets I worked with. The compressibility of the dataset is important since ZFS caches, the ARC and L2ARC, store compressed data. A better compression ratio essentially means more data is cached and fewer IO operations will be needed.
A well-known tool to benchmark a transactional workload is TPCC. Furthermore, the dataset created by TPCC compresses rather well making it more realistic in the context of this post. The sysbench TPCC implementation was used.
Since I am already familiar with AWS and Google cloud, I decided to try Azure for this project. I launched these two virtual machines:
tpcc:
db:
By default and unless specified, the ZFS filesystems are created with:
|
1 2 3 4 5 |
zpool create bench /dev/sdc zfs set compression=lz4 atime=off logbias=throughput bench zfs create -o mountpoint=/var/lib/mysql/data -o recordsize=16k -o primarycache=metadata bench/data zfs create -o mountpoint=/var/lib/mysql/log bench/log |
There are two ZFS filesystems. bench/data is optimized for the InnoDB dataset while bench/log is tuned for the InnoDB log files. Both are compressed using lz4 and the logbias parameter is set to throughput which changes the way the ZIL is used. With ext4, the noatime option is used.
ZFS has also a number of kernel parameters, the ones set to non-default values are:
|
1 2 3 |
zfs_arc_max=2147483648 zfs_async_block_max_blocks=5000 zfs_delete_blocks=1000 |
Essentially, the above settings limit the ARC size to 2GB and they throttle down the aggressiveness of ZFS for deletes. Finally, the database configuration is slightly different between ZFS and ext4. There is a common section:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[mysqld] pid-file = /var/run/mysqld/mysqld.pid socket = /var/run/mysqld/mysqld.sock log-error = /var/log/mysql/error.log skip-log-bin datadir = /var/lib/mysql/data innodb_buffer_pool_size = 26G innodb_flush_log_at_trx_commit = 1 # TPCC reqs. innodb_log_file_size = 1G innodb_log_group_home_dir = /var/lib/mysql/log innodb_flush_neighbors = 0 innodb_fast_shutdown = 2 |
and when ext4 is used:
|
1 |
innodb_flush_method = O_DIRECT |
and when ZFS is used:
|
1 2 3 4 5 |
innodb_flush_method = fsync innodb_doublewrite = 0 # ZFS is transactional innodb_use_native_aio = 0 innodb_read_io_threads = 10 innodb_write_io_threads = 10 |
ZFS doesn’t support O_DIRECT but it is ignored with a message in the error log. I chose to explicitly set the flush method to fsync. The doublewrite buffer is not needed with ZFS and I was under the impression that the Linux native asynchronous IO implementation was not well supported by ZFS so I disabled it and increased the number of IO threads. We’ll revisit the asynchronous IO question in a future post.
I use the following command to create the dataset:
|
1 2 |
./tpcc.lua --mysql-host=10.3.0.6 --mysql-user=tpcc --mysql-password=tpcc --mysql-db=tpcc --threads=8 --tables=10 --scale=200 --db-driver=mysql prepare |
The resulting dataset has a size of approximately 200GB. The dataset is much larger than the buffer pool so the database performance is essentially IO-bound.
The execution of every benchmark was scripted and followed these steps:
For the benchmark, I used the following invocation:
|
1 2 |
./tpcc.lua --mysql-host=10.3.0.6 --mysql-user=tpcc --mysql-password=tpcc --mysql-db=tpcc --threads=16 --time=7200 --report-interval=10 --tables=10 --scale=200 --db-driver=mysql ru |
The TPCC benchmark uses 16 threads for a duration of 2 hours. The duration is sufficiently long to allow for a steady state and to exhaust the storage burst capacity. Sysbench returns the total number of TPCC transactions per second every 10s. This number includes not only the New Order transactions but also the other transaction types like payment, order status, etc. Be aware of that if you want to compare these results with other TPCC benchmarks.
In those conditions, the figure below presents the rates of TPCC transactions over time for ext4 and ZFS.
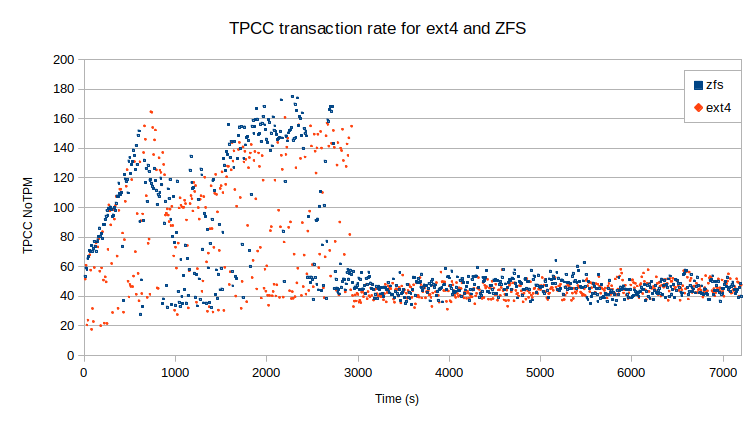
During the initial 15 minutes, the buffer pool warms up but at some point, the workload shifts between an IO read bound to an IO write and CPU bound. Then, at around 3000s the SSD Premium burst capacity is exhausted and the workload is only IO-bound. I have been a bit surprised by the results, enough to rerun the benchmarks to make sure. The results for both ext4 and ZFS are qualitatively similar. Any difference is within the margin of error. That essentially means if you configure ZFS properly, it can be as IO efficient as ext4.
What is interesting is the amount of storage used. While the dataset on ext4 consumed 191GB, the lz4 compression of ZFS yielded a dataset of only 69GB. That’s a huge difference, a factor of 2.8, which could save a decent amount of money over time for large datasets.
It appears that it was indeed a good time to revisit the performance of MySQL with ZFS. In a fairly realistic use case, ZFS is on par with ext4 regarding performance while still providing the extra benefits of data compression, snapshots, etc. In the next post, I examine the use of cloud ephemeral storage with ZFS and see how this can further improve performance.
Percona Distribution for MySQL is the most complete, stable, scalable, and secure, open-source MySQL solution available, delivering enterprise-grade database environments for your most critical business applications… and it’s free to use!
Resources
RELATED POSTS





Would you comment on using MySQL compression on ext4 vs uncompressed tables in ZFS. I was compressed tables on ext4 with LVM of four , 1 TB hard drives in EC2.
I can certainly compare ext4 with InnoDB compression with ZFS, I’ll add that to my todo list.
hey what about 5.11 btrfs ?
Is btrfs stable enough now? I had a rough ride the last time I tried it.
btrfs improved a lot and usually only most advance features like raid5/6 are still broken and others need more fine-tune, but unless you need some advance features, usage is stable and with good performance (usually a little slower, some times lot slower, other even faster than ext4)
check https://btrfs.wiki.kernel.org/index.php/Status#Overview
notice that nodatacow may be required to avoid over fragmentation of the DB.
i remember that some sqlite optimizations where made, dunno if also apply to mysql/mariadb
I’ll look into btrfs in a near future.
Here is a recent benchark with bttrfs, xfs, ext4 and f2fs. It also includes some basic mariadb benchmarks, but notice that this site is known to use default settings, they don’t do any finetuning, so probably btrfs have CoW enable for the mariadb tests.
https://www.phoronix.com/scan.php?page=news_item&px=Linux-5.14-File-Systems
Thanks for this comparison Yves. I have a very large database with very compressible text data. I had a great success with MyRocks, but for some internal tech debt I had to migrate this database to Group Replication. The InnoDB page compression + Percona compressible columns are 3x larger. I´m thinking about dropping Page compression and testing ZFS with compression. Page compression feels like a inefficient hack with holes in my disk. Do you think that this would work better (better compression and/or better performance) ?
ZFS compression performance is essentially limited by the underlying sector size used by the vdev (the zpool ashift parameter). If the sector size is 4KB, the best compression level you can hope for a 16KB InnoDB page is 0.25 (4/16). If the compressibility is really high, you’ll need to use a NVMe device which can support a sector size of 512 bytes. If you are stuck with vdevs having a 4KB sector, you can explore the possibility of using larger InnoDB page sizes like 32KB or 64KB.
Hi Yves
Very interesting blog post thank you
It would have been interesting to see the results with local nvme disks where the io perfs are much higher to see if zfs still compare to ext4
https://docs.microsoft.com/fr-fr/azure/virtual-machines/lsv2-series
What do you think?
Best regards
Camille
If the storage is very low, the compression/uncompression overhead of ZFS will likely become the bottleneck however, even if a bit slower, ZFS will store much more data. Another thing to add to the todo list.
Thanks for sharing!
It would be interesting to compare with ext4 and InnoDB compression.
Also, I don’t see benchmarks with the lazytime option, is it negligible?
ext4 was mounted with the noatime option, which is commonly used with MySQL.
But what happens with files modification times?
Isn’t lazytime useful for that?
Thanks!
People are using ext4 for databases? weird!
Why is that weird? In most common cases, ext4 and xfs behave similarly, especially in a cloud based environment where the iops are limited to a few 1000s.
Thank you, great article. Just curious, did you ever tried to repeat same test on FreeBSD? They now sharing OpenZFS code, so kernel will be only difference. I can try to reproduce that…
Hi Yves, I repeated your test on local hardware and compared the results to Ext4 with InnoDB table compression. See the following graph.
https://www.dropbox.com/s/e6si0fm9i5a9d5o/zfs-vs-ext4.png?dl=0
I believe I followed your steps exactly. The test system is a Dell PowerEdge R640 with 48 cores, 1 TB RAM, and 6 x Dell 3.2 TB Enterprise NVME drives. On the ZFS test, all 6 drives are in one zpool but I created separate zfs filesystems for data and logs, per your instructions. For the Ext4 test, I created a single LVM RAID array with 6 stripes (4K block size), but the the data and logs are on the same LV. Even so, Ext4 dramatically outperformed ZFS.
The compression ratio on ZFS was much better. The test database, which is 189 GB uncompressed, ended up being 92 GB with InnoDB table compression, but only 59 GB on ZFS.
Something to note is that IOWAIT averaged about 2% during the Ext4 test, but was around 0-0.5% on the ZFS test.
Another interesting finding is that performance was only slightly impacted when I used a much smaller buffer pool. With an 8 GB pool (versus 26 GB), average performance on ZFS only dropped by about 100 TPS. I have not tried that with Ext4 yet.
These results are disappointing because I really want to use ZFS, but now I am not sure I can justify it. It is possible that I missed something. You’re welcome to examine the test system if you are interested.
If the link does not work when clicking it, try pasting it into a browser manually. That worked for me.
That is very interesting, Given the 1TB of RAM, and the 189GB of uncompressed data, all the dataset fits in memory, either in the buffer pool or in the file cache. In such a case, I am not surprised ext4 outperforms ZFS. The dataset is quickly cached so the amount of reads drops leaving only the writes as a limiting factor. Writes are more expensive in ZFS because of compression. ZFS would start to show its value with a dataset size greater than the memory size. Were you using an ACID configuration? What size have you used for the ARC with 1TB of RAM?
I performed a default install of percona-server-server.x86_64 8.0.26-16.1.el8 and made no changes beyond the ones in your procedure. Regarding the ARC stats, I see..
c 4 125549541504
cached_only_in_progress 4 0
c_max 4 540636465152
c_min 4 33789779072
size 124531475032
> ZFS would start to show its value with a dataset size greater than the memory size.
Ultimately, that describes the situation I will have. The server will be home to 100+ separate instances of MySQL with customized configurations, none of which will enjoy the benefit of the server’s full resources. The databases will range in size from 10 GB to 400 GB, most around 20-25. GB. All instances will run with buffer pools that are as small as is feasible.
100+ instances with an average size of above 20GB will certainly fits within the sweet spot of ZFS. If you want to validate the configuration you should retry the benchmark with a size of 2000 or maybe even 2500 (instead of 200). That will give you a better idea.
You mean the sysbench –scale parameter?
Clearly the glitch was was with me, not the forum. 🙂
yes
Hi Yves, I ran the sysbench test on ZFS at 2500 scale. Resulting graph is here:
https://www.dropbox.com/s/2mblcsk0hg6f0bb/zfs-at-scale.png?dl=0
The numbers are not terribly different from the test at 200 scale, about 70 TPS less on average, but I’m not sure what that means. By the way, did you catch my original statement that there will be 100+ separate instances of MySQL on the server, not just 100+ databases? Only a portion of the server’s total resources will be allocated to each instance. Obviously the conventional wisdom of 70% server RAM for the buffer pool is off the table.
Yves, here’s a question for you. We’re using ZFS zvols as the backing devices for DRBD volumes, The filesystems we create on top of DRBD could be either ZFS, EXT4, or XFS. I’m thinking ZFS on top of DRBD is not the best idea because ZFS normally wants to talk directly to the drives, so I guess DRBD would defeat that. That leaves EXT4 or XFS.If we go with one of those, which of your sample my.cnf configs would we use for testing?
Thank you for publishing your results.
I think that to be more fair you should reduce innodb buffer by 8GB in case of ZFS (to use same amount of RAM).
I have performed similar tests with 36GB database:
1GB innodb buffer + 4GB ARC on ZFS (about 5GB RAM total)5GB innodb buffer for ext4 (about 5GB RAM total)I removed skip-log-bin in my configurations, because I need it, and my server has 8k recordsize set in ZFS on whole ZFS pool (I don’t remember why).
Resuts for ZFS are still much better than EXT4 (zfs is faster by 50%) and I have no issues with latency on ZFS at all, actually it has lower latency than setup with ext4.
And the compression on ZFS is outstanding. My database uses only ~50% of space on ZFS.