
If you are a regular reader of this blog, you likely know I like the ZFS filesystem a lot. ZFS has many very interesting features, but I am a bit tired of hearing negative statements on ZFS performance. It feels a bit like people are telling me “Why do you use InnoDB? I have read that MyISAM is faster.” I found the comparison of InnoDB vs. MyISAM quite interesting, and I’ll use it in this post.
To have some data to support my post, I started an AWS i3.large instance with a 1000GB gp2 EBS volume. A gp2 volume of this size is interesting because it is above the burst IOPS level, so it offers a constant 3000 IOPS performance level.
I used sysbench to create a table of 10M rows and then, using export/import tablespace, I copied it 329 times. I ended up with 330 tables for a total size of about 850GB. The dataset generated by sysbench is not very compressible, so I used lz4 compression in ZFS. For the other ZFS settings, I used what can be found in my earlier ZFS posts but with the ARC size limited to 1GB. I then used that plain configuration for the first benchmarks. Here are the results with the sysbench point-select benchmark, a uniform distribution and eight threads. The InnoDB buffer pool was set to 2.5GB.
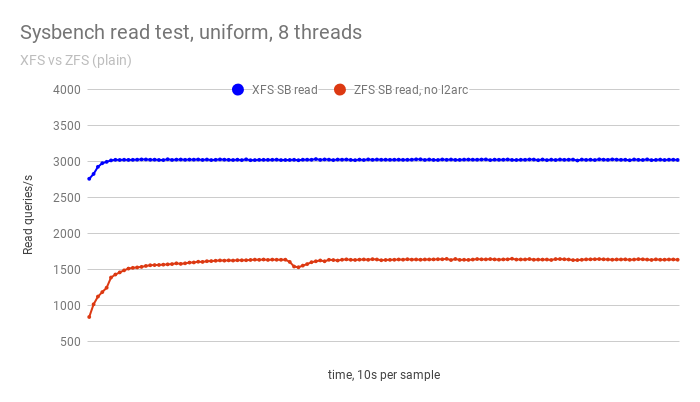
In both cases, the load is IO bound. The disk is doing exactly the allowed 3000 IOPS. The above graph appears to be a clear demonstration that XFS is much faster than ZFS, right? But is that really the case? The way the dataset has been created is extremely favorable to XFS since there is absolutely no file fragmentation. Once you have all the files opened, a read IOP is just a single fseek call to an offset and ZFS doesn’t need to access any intermediate inode. The above result is about as fair as saying MyISAM is faster than InnoDB based only on table scan performance results of unfragmented tables and default configuration. ZFS is much less affected by the file level fragmentation, especially for point access type.
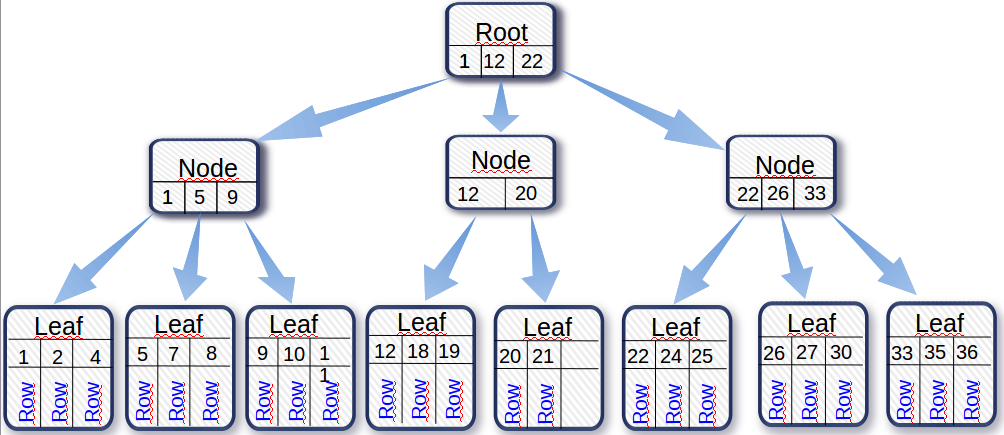
ZFS stores the files in B-trees in a very similar fashion as InnoDB stores data. To access a piece of data in a B-tree, you need to access the top level page (often called root node) and then one block per level down to a leaf-node containing the data. With no cache, to read something from a three levels B-tree thus requires 3 IOPS.
The extra IOPS performed by ZFS are needed to access those internal blocks in the B-trees of the files. These internal blocks are labeled as metadata. Essentially, in the above benchmark, the ARC is too small to contain all the internal blocks of the table files’ B-trees. If we continue the comparison with InnoDB, it would be like running with a buffer pool too small to contain the non-leaf pages. The test dataset I used has about 600MB of non-leaf pages, about 0.1% of the total size, which was well cached by the 3GB buffer pool. So only one InnoDB page, a leaf page, needed to be read per point-select statement.
To correctly set the ARC size to cache the metadata, you have two choices. First, you can guess values for the ARC size and experiment. Second, you can try to evaluate it by looking at the ZFS internal data. Let’s review these two approaches.
You’ll read/hear often the ratio 1GB of ARC for 1TB of data, which is about the same 0.1% ratio as for InnoDB. I wrote about that ratio a few times, having nothing better to propose. Actually, I found it depends a lot on the recordsize used. The 0.1% ratio implies a ZFS recordsize of 128KB. A ZFS filesystem with a recordsize of 128KB will use much less metadata than another one using a recordsize of 16KB because it has 8x fewer leaf pages. Fewer leaf pages require less B-tree internal nodes, hence less metadata. A filesystem with a recordsize of 128KB is excellent for sequential access as it maximizes compression and reduces the IOPS but it is poor for small random access operations like the ones MySQL/InnoDB does.
To determine the correct ARC size, you can slowly increase the ARC size and monitor the number of metadata cache-misses with the arcstat tool. Here’s an example:
|
1 2 3 4 5 6 7 8 |
# echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_max # arcstat -f time,arcsz,mm%,mhit,mread,dread,pread 10 time arcsz mm% mhit mread dread pread 10:22:49 105M 0 0 0 0 0 10:22:59 113M 100 0 22 73 0 10:23:09 120M 100 0 20 68 0 10:23:19 127M 100 0 20 65 0 10:23:29 135M 100 0 22 74 0 |
You’ll want the ‘mm%’, the metadata missed percent, to reach 0. So when the ‘arcsz’ column is no longer growing and you still have high values for ‘mm%’, that means the ARC is too small. Increase the value of ‘zfs_arc_max’ and continue to monitor.
If the 1GB of ARC for 1TB of data ratio is good for large ZFS recordsize, it is likely too small for a recordsize of 16KB. Does 8x more leaf pages automatically require 8x more ARC space for the non-leaf pages? Although likely, let’s verify.
The second option we have is the zdb utility that comes with ZFS, which allows us to view many internal structures including the B-tree list of pages for a given file. The tool needs the inode of a file and the ZFS filesystem as inputs. Here’s an invocation for one of the tables of my dataset:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
# cd /var/lib/mysql/data/sbtest # ls -li | grep sbtest1.ibd 36493 -rw-r----- 1 mysql mysql 2441084928 avr 15 15:28 sbtest1.ibd # zdb -ddddd mysqldata/data 36493 > zdb5d.out # more zdb5d.out Dataset mysqldata/data [ZPL], ID 90, cr_txg 168747, 4.45G, 26487 objects, rootbp DVA[0]=<0:1a50452800:200> DVA[1]=<0:5b289c1600:200> [L0 DMU objset] fletcher4 lz4 LE contiguous unique double size=800L/200P birth=3004977L/3004977P fill=26487 cksum=13723d4400:5d1f47fb738:fbfb87e6e278:1f30c12b7fa1d1 Object lvl iblk dblk dsize lsize %full type 36493 4 16K 16K 1.75G 2.27G 97.62 ZFS plain file 168 bonus System attributes dnode flags: USED_BYTES USERUSED_ACCOUNTED dnode maxblkid: 148991 path /var/lib/mysql/data/sbtest/sbtest1.ibd uid 103 gid 106 atime Sun Apr 15 15:04:13 2018 mtime Sun Apr 15 15:28:45 2018 ctime Sun Apr 15 15:28:45 2018 crtime Sun Apr 15 15:04:13 2018 gen 3004484 mode 100640 size 2441084928 parent 36480 links 1 pflags 40800000004 Indirect blocks: 0 L3 0:1a4ea58800:400 4000L/400P F=145446 B=3004774/3004774 0 L2 0:1c83454c00:1800 4000L/1800P F=16384 B=3004773/3004773 0 L1 0:1eaa626400:1600 4000L/1600P F=128 B=3004773/3004773 0 L0 0:1c6926ec00:c00 4000L/c00P F=1 B=3004773/3004773 4000 L0 EMBEDDED et=0 4000L/6bP B=3004484 8000 L0 0:1c69270c00:400 4000L/400P F=1 B=3004773/3004773 c000 L0 0:1c7fbae400:800 4000L/800P F=1 B=3004736/3004736 10000 L0 0:1ce3f53600:3200 4000L/3200P F=1 B=3004484/3004484 14000 L0 0:1ce3f56800:3200 4000L/3200P F=1 B=3004484/3004484 18000 L0 0:18176fa600:3200 4000L/3200P F=1 B=3004485/3004485 1c000 L0 0:18176fd800:3200 4000L/3200P F=1 B=3004485/3004485 ... [more than 140k lines truncated] |
The last section of the above output is very interesting as it shows the B-tree pages. The ZFSB-tree of the file sbtest1.ibd has four levels. L3 is the root page, L2 is the first level (from the top) pages, L1 are the second level pages, and L0 are the leaf pages. The metadata is essentially L3 + L2 + L1. When you change the recordsize property of a ZFS filesystem, you affect only the size of the leaf pages.
The non-leaf page size is always 16KB (4000L) and they are always compressed on disk with lzop (If I read correctly). In the ARC, these pages are stored uncompressed so they use 16KB of memory each. The fanout of a ZFS B-tree, the largest possible ratio of a number of pages between levels, is 128. With the above output, we can easily calculate the required size of metadata we would need to cache all the non-leaf pages in the ARC.
|
1 2 3 4 5 6 7 8 |
# grep -c L3 zdb5d.out 1 # grep -c L2 zdb5d.out 9 # grep -c L1 zdb5d.out 1150 # grep -c L0 zdb5d.out 145447 |
So, each of the 330 tables of the dataset has 1160 non-leaf pages and 145447 leaf pages; a ratio very close to the prediction of 0.8%. For the complete dataset of 749GB, we would need the ARC to be, at a minimum, 6GB to fully cache all the metadata pages. Of course, there is some overhead to add. In my experiments, I found I needed to add about 15% for ARC overhead in order to have no metadata reads at all. The real minimum for the ARC size I should have used is almost 7GB.
Of course, an ARC of 7GB on a server with 15GB of Ram is not small. Is there a way to do otherwise? The first option we have is to use a larger InnoDB page size, as allowed by MySQL 5.7. Instead of the regular Innodb page size of 16KB, if you use a page size of 32KB with a matching ZFS recordsize, you will cut the ARC size requirement by half, to 0.4% of the uncompressed size.
Similarly, an Innodb page size of 64KB with similar ZFS recordsize would further reduce the ARC size requirement to 0.2%. That approach works best when the dataset is highly compressible. I’ll blog more about the use of larger InnoDB pages with ZFS in a near future. If the use of larger InnoDB page sizes is not a viable option for you, you still have the option of using the ZFS L2ARC feature to save on the required memory.
So, let’s proposed a new rule of thumb for the required ARC/L2ARC size for a a given dataset:
In order to improve ZFS performance, I had 3 options:
I was reluctant to grow the ARC to 7GB, which was nearly half the overall system memory. At best, the ZFS performance would only match XFS. A larger InnoDB page size would increase the CPU load for decompression on an instance with only two vCPUs; not great either. The last option, the L2ARC, was the most promising.
The choice of an i3.large instance type is not accidental. The instance has a 475GB ephemeral NVMe storage device. Let’s try to use this storage for the ZFS L2ARC. The warming of an L2ARC device is not exactly trivial. In my case, with a 1GB ARC, I used:
|
1 2 3 4 5 6 7 8 9 10 |
echo 1073741824 > /sys/module/zfs/parameters/zfs_arc_max echo 838860800 > /sys/module/zfs/parameters/zfs_arc_meta_limit echo 67108864 > /sys/module/zfs/parameters/l2arc_write_max echo 134217728 > /sys/module/zfs/parameters/l2arc_write_boost echo 4 > /sys/module/zfs/parameters/l2arc_headroom echo 16 > /sys/module/zfs/parameters/l2arc_headroom_boost echo 0 > /sys/module/zfs/parameters/l2arc_norw echo 1 > /sys/module/zfs/parameters/l2arc_feed_again echo 5 > /sys/module/zfs/parameters/l2arc_feed_min_ms echo 0 > /sys/module/zfs/parameters/l2arc_noprefetch |
I then ran ‘cat /var/lib/mysql/data/sbtest/* > /dev/null’ to force filesystem reads and caches on all of the tables. A key setting here to allow the L2ARC to cache data is the zfs_arc_meta_limit. It needs to be slightly smaller than the zfs_arc_max in order to allow some data to be cache in the ARC. Remember that the L2ARC is fed by the LRU of the ARC. You need to cache data in the ARC in order to have data cached in the L2ARC. Using lz4 in ZFS on the sysbench dataset results in a compression ration of only 1.28x. A more realistic dataset would compress by more than 2x, if not 3x. Nevertheless, since the content of the L2ARC is compressed, the 475GB device caches nearly 600GB of the dataset. The figure below shows the sysbench results with the L2ARC enabled:
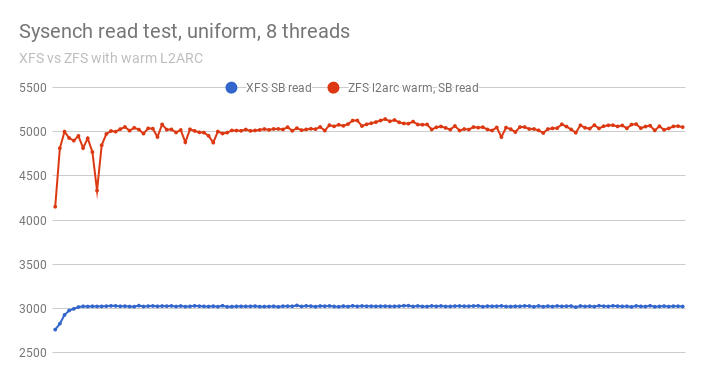
Now, the comparison is very different. ZFS completely outperforms XFS, 5000 qps for ZFS versus 3000 for XFS. The ZFS results could have been even higher but the two vCPUs of the instance were clearly the bottleneck. Properly configured, ZFS can be pretty fast. Of course, I could use flashcache or bcache with XFS and improve the XFS results but these technologies are way more exotic than the ZFS L2ARC. Also, only the L2ARC stores data in a compressed form, maximizing the use of the NVMe device. Compression also lowers the size requirement and cost for the gp2 disk.
ZFS is much more complex than XFS and EXT4 but, that also means it has more tunables/options. I used a simplistic setup and an unfair benchmark which initially led to poor ZFS results. With the same benchmark, very favorable to XFS, I added a ZFS L2ARC and that completely reversed the situation, more than tripling the ZFS results, now 66% above XFS.
We have seen in this post why the general perception is that ZFS under-performs compared to XFS or EXT4. The presence of B-trees for the files has a big impact on the amount of metadata ZFS needs to handle, especially when the recordsize is small. The metadata consists mostly of the non-leaf pages (or internal nodes) of the B-trees. When properly cached, the performance of ZFS is excellent. ZFS allows you to optimize the use of EBS volumes, both in term of IOPS and size when the instance has fast ephemeral storage devices. Using the ephemeral device of an i3.large instance for the ZFS L2ARC, ZFS outperformed XFS by 66%.
For insight on how ZFS affects MySQL performance when they are working together, see Senior Consultant Jervin Real’s blog on the topic, which includes a comparative test.





Why would you use a L2ARC if you could increase the innodb pool buffer size about the same size? This does not make any sense and you can not compare the cache results! The pool buffer should outperform the L2ARC if warmed up, too.
Great post Yves! Am I right by saying that you gave an additional advantage to XFS by not compressing the tables with the native InnoDB compression ? I recall someone choosing ZFS due several features, being one of those: compression on the filesystem performing better than on the tables.
Doing first a benchmark in favour of XFS and then doing the same for ZFS is not a plausible benchmark methology. You already stated thst you could use bcache for XFS, but it is exotic.
So in reality your last benchmark was good for ZFS because the system was able to use an extra device for performance tuning, that is no realistic result.
About all benchmarks done by percona to show ZFS are completely flawed by design. Its a pitty because many people would be really interested in COMPARABLE results for xfs/ext4 to zfs and this means trying to achieve the same, e.g. bcache for xfs.
This is not a comprehensive benchmark, this is just to highlight and explain why ZFS performance often appears to be lower.
This looks like a classic symptom of reads from a pool filled with logbias=throughout writes. Every one of them has its data and metadata fragmented, so of course read performance will be poor. It’s a parameter only worth using at relatively large record sizes, or with a dedicated SLOG that you want to keep things out of.
primarycache=metadata is a warning sign that something is very wrong. A normal pool (direct sync or async writes) should combine data block and metadata writes almost all the time, making it a single sequential read to access. If zpool iostat -r is showing lots of 4K reads, you have too much data going through indirect writes. Change logbias to latency, raise zfs_immediate_write_size if you don’t have a SLOG, and raise your average block size to preserve what locality you can. And let data blocks into the ARC. Really.
Integrating ZFS with databases since 2005.
Of course it would be faster to have half a TB of buffer pool but that would be way more expansive. A r4.16xlarge has the RAM but it costs about 27 times more than an I3.large instance, that could be a bummer…
That’s a good point Daniel, InnoDB would hit XFS performance. Since the load was IO bound, I wonder if the CPU load would rise enough with InnoDB compression to move the bottleneck to the CPU.
Although done for a very special use case, a general comparison of xfs/ext4/zfs can be found here: http://ebert.homelinux.org/publication1.html
(the conference contribution about it: http://ebert.homelinux.org/pdf2.html)
However, it doesn’t not test random read/writes since that was not a use case of the system in question.
That’s the problem with doing this with MySQL right there. The ARC, page cache and buffer pool will compete for memory, worst case is having the same page buffered thrice.
Thanks for pointing that out Nils. A pool buffer is EXACTLY the same as the L2ARC of ZFS. This is absolutly nonse what you benchmarked.
@Yves Trudeau: Compare the same size of memories on both variants.
16 GB RAM VM.
Bench 1: 12 GB pool buffer
vs
Bench 2: 6 GB pool buffer + 6 gb zfs cache
vs
Bench 3: 6 GB pool buffer
I expect in a production env:
Bench 1 > Bench 2 > Bench 3
In you test:
Bench 2 > Bench 3 > Bench 1
Because: You have a warmed up cache vs. a cold cache.
Sorry, I have to disagree, the buffer pool is stored in RAM, the L2ARC is stored on disk. So, that is not the same at all.
The dataset size is 850GB, that makes the buffer pool size almost irrelevant since a very tiny fraction of the dataset will be cache in it anyway. A buffer pool of 12GB represents 1.4% of the dataset while a buffer pool of 6GB, 0.7%. In both cases, around 99% of the queries will require a read from the EBS volume. Now, the L2ARC in on disk, on the NVMe ephemeral drive and it can store about 600GB of the dataset with compression. That’s quite different. Now, 70% of the dataset is cached so only 30% of the queries will require a read from the EBS volume.
If you compare a server with hdd vs a server with ssd (NVMe) … that is like comparing a gasoline vs a diesel.
You can also create a read-cache with Devicemapper and ext4. What would be a “fair” fight 😉 I’ve used this on a Xen Infrastructure and was quite nice.
https://rwmj.wordpress.com/2014/05/22/using-lvms-new-cache-feature/
A point worth considering – let’s say primary storage is spinning disk and you can allocate an L2ARC in a faster storage tier (but you can’t afford enough of it for the entire datadir). What Yves illustrates here pretty well is that you can speed up MySQL performance using ZFS over and above what spinning disk + bufferpool can do alone. All you need is a little fast storage for an appropriately sized L2ARC and you can speed up performance significantly. I think that’s a key point, and in some instances, that double caching others may be worried about can be worth it.
Certainly not an apples to apples comparison,
Of course, I just wanted to highlight here the fact that ZFS is not necessarily slower.
Whoops, posted in the wrong place. Anyways, you are trying to treat a badly fragmented pool. Don’t fragment it in the first place (logbias, immed size) and you won’t run into this problem in the first place. send/receive it and your read iops should double due to metadata fragmentation.
Actually, logbias was set to “latency”.
If you have logbias=latency but no SLOG, writes larger than zfs_immediate_write_size will be committed via indirect sync and produce fragmented metadata as well. Your zdb output shows results consistent with indirect sync writes:
0 L2 0:1c83454c00:1800 4000L/1800P F=16384 B=3004773/3004773
0 L1 0:1eaa626400:1600 4000L/1600P F=128 B=3004773/3004773
0 L0 0:1c6926ec00:c00 4000L/c00P F=1 B=3004773/3004773
4000 L0 EMBEDDED et=0 4000L/6bP B=3004484
8000 L0 0:1c69270c00:400 4000L/400P F=1 B=3004773/3004773
c000 L0 0:1c7fbae400:800 4000L/800P F=1 B=3004736/3004736
10000 L0 0:1ce3f53600:3200 4000L/3200P F=1 B=3004484/3004484
14000 L0 0:1ce3f56800:3200 4000L/3200P F=1 B=3004484/3004484
You may want to be sure what is happening with your blocks before you troubleshoot more. send/receive the datasets to defrag them and either raise zfs_immediate_write_size very high or add an SLOG. You should see many fewer problems with metadata fragmentation.
That’s interesting, I’d like to understand better. The b-tree shown by zdd was what I was about expecting especially since I am using a recordsize of 16kb. Normally InnoDB will write in 16kb chunks unless innodb_flush_neighbors is set (which may have been set since it is the default). If I understand correctly, the first column is your concern right?
Honestly, the best way to test for indirect sync fragmentation is just to do a “zfs send pool/dataset >/dev/null” while you watch with “zpool iostat -r 1”. If you see large numbers of 4K reads that refuse to merge with any other IO, you have fragmented metadata from indirect sync writes. Random read IOPs basically drop in half.
If you then zfs send | zfs receive it to a different name, clear your caches, and repeat the test – metadata should all be in its correct place and you will see very few isolated reads and much better performance.
We are beating XFS by 20% on read/select tests with MongoDB thanks to aggressive readbetween, and breaking even with XFS on journal write times. I feel pretty good about that!
Thanks for sharing this valuable experience. Very inspiring to understand the zfs tuning!