
I’ve recently worked with customers using replication rings with 4+ servers; several servers accepting writes. The idea behind this design is always the same: by having multiple servers, you get high availability and by having multiple writer nodes, you get write scalability. Alas, this is simply not true. Here is why.
Having several servers is a necessary condition to have high availability, but it’s far from sufficient. What happens if for instance C suddenly disappears?
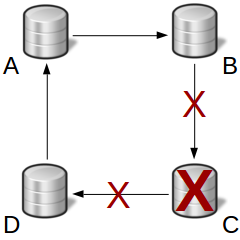
Conclusion: each time a server goes down, the whole system goes down. In other words, availability is poorer than with a single server.
You can think that if you are able to run 1000 writes/s on a single server, writing on 4 servers in parallel will allow you to run 4000 writes/s over the whole cluster. However reality is quite different.
Don’t forget that ALL writes will be executed on ALL servers. So we have 2 separate scenarios:
Conclusion: As all writes are run on all servers, writing on multiple nodes doesn’t magically create extra write capacity. You’re still bound by the capacity of a single server.
Another concern when allowing multiple writers is write conflicts. MySQL doesn’t have any mechanism to detect or solve write conflicts.
So lots of “funny” things can happen when writes are conflicting:
setting auto_increment_increment and auto_increment_offset cannot resolve all possible situations when duplicate key errors can happen.
If you’re interested in learning more on the risk of writing on multiple nodes while using regular MySQL replication, you can check out this webinar.
A ring is one the worst MySQL replication topologies as it dramatically increases the complexity of all operations on the ring while providing no benefit.
If you need an HA solution, it is not an easy choice as there are many of them and all have tradeoffs, but a ring is definitely not the right option. This post can help you find the right candidate(s).
If you need write scalability, the options are limited, but again, MySQL ring replication is not a good fit. The main question to answer is how many writes do you want to be able to run? For instance, if you want 10x write scalability but your current workload is 100 writes/s, that’s easy: just make sure you have a decent schema, decent indexes and decent hardware. If you want 10x write scalability but you’re already running 5000 writes/s, it’s probably time to explore sharding.





Good application planning and failover preparation resolve all of these. Bad and uninformed practice result in the issues ypu’re concerned about; good practice is resolves them.
Israel,
I’m only working on cases where there are issues, so I’m necessarily biased. However I don’t really see how good planning and preparation can help you handle the write conflicts.
What about the GTIDs of 5.6 can that help the servers connect back immediately into a ring?
e.g. a server C disappeared in your example, can server D immediate connect to server B?
With multisource in 5.7 (labs) a server is allowed to slave from multiple masters. Then in a ring of 4 a server can be slave of all other 3 servers. But this still doesn’t make this a good setup.
There are better options if you have 4 servers:
master with 3 slaves
master-master with 2 slaves
3 node galera with one slave
3 node group replication (5.7) with one slave
ndb cluster with 2 api nodes and 2 data nodes.
what alternative to 2-server ring would you propose for bringing data ‘closer to the users’ to provide better performance?
i’m quite happy with the current setup using ring replication between mysql’s/application servers located in Europe and North America. in my case both read and write traffic are very low and unlikely to grow exponentially. users are redirected to the closer site based on geoip and require both read and write access to the data.
Hi Stephane,
Great post on the disadvantages of using ring replication. It is indeed not a solution we recommend, but there are cases where there are no alternatives, such as the case that Pawel raises above: you need to have a “branch server” to handle updates for a specific branch of the business and still be able to propagate the changes to the other “branch servers”. There are several such deployments in productions and they are working fine.
It is hard to do anything about the (lack of) write scalability in ring replication, you just have to be careful about not overloading the system, but there are means to ensure that events do not circulate infinitely. Starting with MySQL 5.5, the IGNORE_SERVER_IDS parameter were added to CHANGE MASTER precisely to handle this case. What it does is allowing a server (the one that issues the CHANGE MASTER with IGNORE_SERVER_IDS) to eliminate events originating from other servers than just itself. This command can then be used to re-direct the downstream server when “shrinking the ring” because one server was lost and have it eliminate all statements that originated from the lost server.
‘@Jacky Leung: correct, GTIDs make reconnecting the remaining servers much easier. However that doesn’t make a ring a good HA solution.
@Daniel Nichter van Eeden: totally agree with you.
@Pawel Kudzia: my point was to mention that a ring is bad option for HA and write scalability. Your use case is different and you only have 2 servers, that makes it a good solution for you.
@Mats Kindahl: I mostly worked with 5.1 setups, so I didn’t know about the IGNORE_SERVER_IDS parameter, thanks!