
In this article series, we will talk about the basic high availability architecture of a MongoDB: the MongoDB replica set.
We’ll cover it in three parts:
Having a secure cluster deployment not only means creating accounts with strong passwords, but also means ensuring secure encrypted connections to the database (and hopefully internal encryption). Often, security flaws come from internal personnel that can legitimately access the private network, but they are not supposed to have access to the data.
So, encrypting intra-node traffic ensures that no one could “sniff” sensitive data on the network.
It’s easy to deploy an architecture with a high availability cluster of MongoDB servers. It’s one of MongoDB’s more important strengths.
Even with MySQL, you can deploy architectures that provide HA. But you need to rely on some external tools. Most of them are third parties tools: Galera, MHA, Tungsten, ProxySQL, DRBD and others.
MongoDB provides HA by-design. To deploy an HA cluster, you need just MongoDB executables and some machines.
To start, a replica set:
The following picture shows a typical environment with an application querying a three-node replica set.
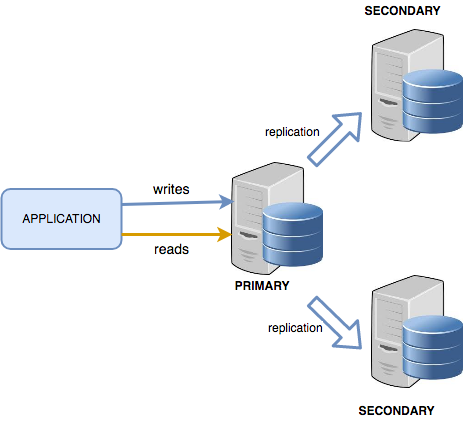
We have a client application (Mongo Shell, other clients or any custom application) that connects to the database through the Driver. Any supported programming language has its own specialized connector for MongoDB.
Let’s also say that, during normal operation, a replica set has just one node as PRIMARY and all the others are SECONDARY. The PRIMARY member is the only one that receives writes. It updates its local collections and documents as well as the oplog. The oplog events are then sent through the replication channel to all the SECONDARY nodes. Each SECONDARY node applies locally, and asynchronously, the same modifications on local data and the oplog.
The next picture shows internally how the replica set works. Each node is connected to all the others and a heartbeat mechanism is in place to ping any other node. The heartbeat has a configurable time for pinging nodes, and the default is 10 seconds.
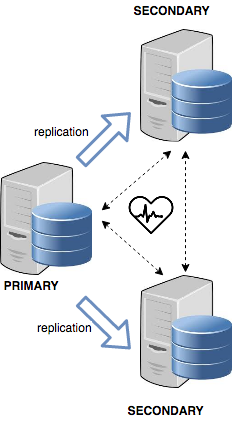
If all the nodes respond with an acknowledge to the heartbeat, the cluster continues to work. If one of the nodes crashes, the PRIMARY for example (the worst occurrence), an election takes place involving the remaining nodes.
When a SECONDARY doesn’t receive a response to the heartbeats after the configured timeout, it calls for an election. The still-alive nodes vote for a new PRIMARY. The election phase doesn’t normally take a long time and the election algorithm is complex enough to let them choose the best secondary to be the new primary. Let’s say it’s the secondary that is mostly up to date with the dead primary.
Other than the crash of the primary, there are other situations where a node calls for an election: when adding a node to the replica set, during “initiating a replica set” or during some maintenance activity. These kind of elections are not the purpose of this article.
The replica set cannot process write operations until the election completes successfully but could continue to serve read queries if such queries are configured to run on secondaries (we’ll discuss that later). After the election completes correctly, the cluster resumes normal operations.
The following picture shows what we’ve described so far.
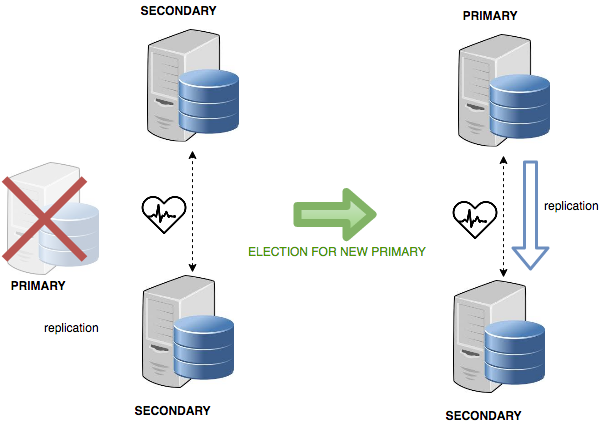
To work properly, a replica set needs to have an odd number of members. In case of a network split, only an odd number of members ensures we have the majority of votes in one of the subsets. A new PRIMARY is elected in the subset with the majority of nodes.
So, as a consequence, three is the minimum number of nodes for a Replica Set to assure high availability.
Since each node needs to have a complete copy of the data, if you have a huge database you will need to provide at least three machines with a lot of resources for disks, memory and CPUs. This could be expensive.
Fortunately, you can configure one of the nodes as an Arbiter, a special member that doesn’t replicate data. It’s empty, but it can vote during an election.
Using an arbiter node is a good solution to maintain an odd number of members, without spending a lot of money to have a third node as powerful as the others. An arbiter node cannot be elected as the new primary since it doesn’t have data.
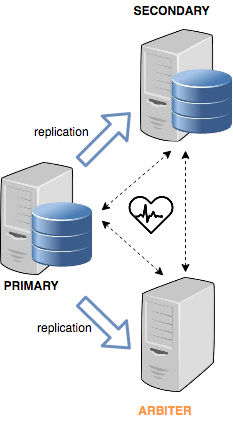
Another important feature is the Priority. We can give each node weight. This kind of configuration is important in case we want to be sure that only a particular subset of our members can be elected as primary.
Here is a realistic multi-data-center replica set deployment.
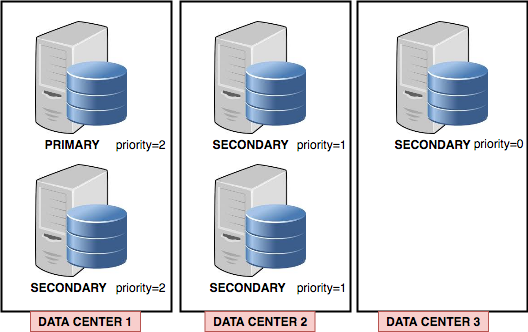
The picture shows a replica set deployed in three data centers. In case of a PRIMARY failure, only the other node in Data Center 1 can be elected. Only if both nodes in Data Center 1 are unavailable will one of the nodes in Data Center 2 get elected. The secondary node in Data Center 3 has a priority=0, so it can never be elected.
We can say that Data Center 1 is the “main site”, Data Center 2 is the “Disaster Recovery” site and Data Center 3 could be for “backups” (for running “analytics”, for example).
A hidden member is a node that maintains a copy of primary’s data, but it’s invisible to client applications.
These kinds of nodes are useful for different usage patterns from the other members. Backups and analytics are good examples.
The priority of a hidden member must be zero. Although it can’t be elected as primary, it can vote during an election.
We can even define a secondary member that reflects an earlier state of the data set. This is useful for backups, but best for recovering from unsuccessful application upgrades or some human error when deleting or modifying documents.
To configure a delay member, we need to set the slaveDelay parameter to a value that is the number of seconds of delay.
This kind of node should be hidden and must have priority=0. It cannot be elected, but it can vote during elections.
In Part 2 on the MongoDB replica set, we’ll provide a step-by-step guide to configure a basic and fully operational three-node replica set.
For further reading about MongoDB replica set internals: https://github.com/mongodb/mongo/wiki/Replication-Internals.
Resources
RELATED POSTS




