
 Nothing lasts forever, including hardware running your EC2 instances. You will usually receive an advance warning on hardware degradation and subsequent instance retirement, but sometimes hardware fails unexpectedly. Percona Monitoring and Management (PMM) currently doesn’t have an HA setup, and such failures can leave wide gaps in monitoring if not resolved quickly.
Nothing lasts forever, including hardware running your EC2 instances. You will usually receive an advance warning on hardware degradation and subsequent instance retirement, but sometimes hardware fails unexpectedly. Percona Monitoring and Management (PMM) currently doesn’t have an HA setup, and such failures can leave wide gaps in monitoring if not resolved quickly.
In this post, we’ll see how to set up automatic recovery for PMM instances deployed in AWS through Marketplace. The automation will take care of the instance following an underlying systems failure. We’ll also set up an automatic restart procedure in case the PMM instance itself is experiencing issues. These simple automatic actions go a long way in improving the resilience of your monitoring setup and minimizing downtime.
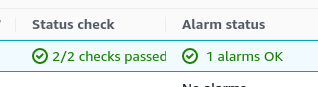
Each EC2 instance has two associated status checks: System and Instance. You can read in more detail about them on the “Types of status checks” AWS documentation page. The gist of it is, the System check fails to pass when there are some infrastructure issues. The Instance check fails to pass if there’s anything wrong on the instance side, like its OS having issues. You can normally see the results of these checks as “2/2 checks passed” markings on your instances in the EC2 console.

CloudWatch, an AWS monitoring system, can react to the status check state changes. Specifically, it is possible to set up a “recover” action for an EC2 instance where a system check is failing. The recovered instance is identical to the original, but will not retain the same public IP unless it’s assigned an Elastic IP. I recommend that you use Elastic IP for your PMM instances (see also this note in PMM documentation). For the full list of caveats related to instance recovery check out the “Recover your instance” page in AWS documentation.
According to CloudWatch pricing, having two alarms set up will cost $0.2/month. An acceptable cost for higher availability.
Let’s get to actually setting up the automation. There are at least two ways to set up the alarm through GUI: from the EC2 console, and from the CloudWatch interface. The latter option is a bit involved, but it’s very easy to set up alarms from the EC2 console. Just right-click on your instance, pick the “Monitor and troubleshoot” section in the drop-down menu, and then choose the “Manage CloudWatch alarms” item.
Once there, choose the “Status check failed” as the “Type of data to sample”, and specify the “Recover” Alarm action. You should see something like this.
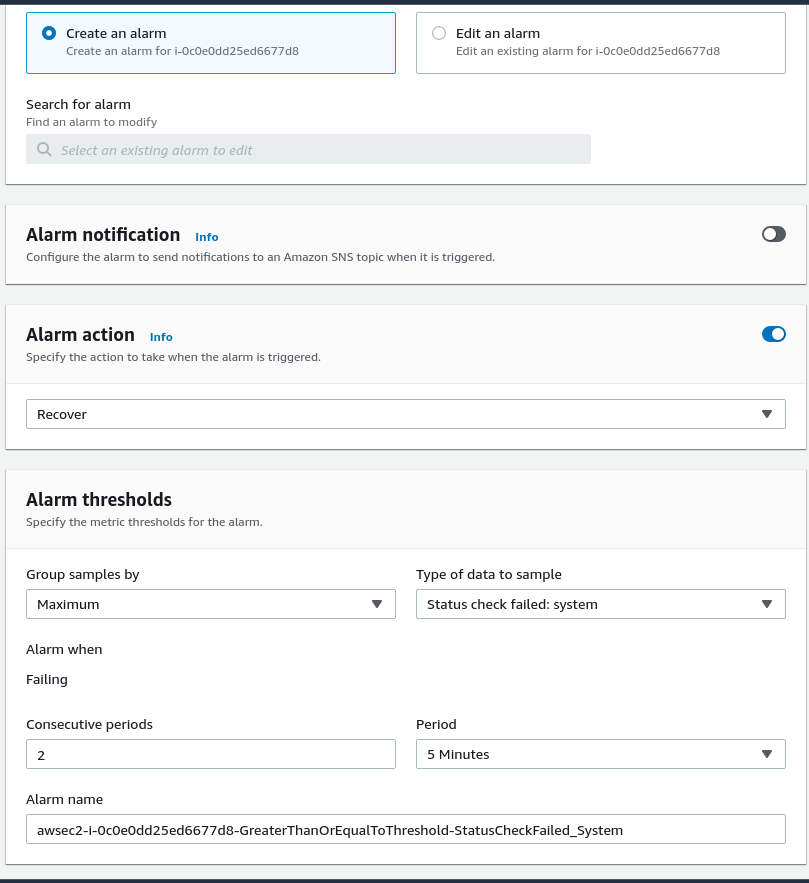
You could notice that GUI offers to set up a notification channel for the alarm. If you want to get a message if your PMM instance is recovered automatically, feel free to set that up.
The alarm will fire when the maximum value of the StatusCheckFailed_System metric is >=0.99 during two consecutive 300 seconds periods. Once the alarm fires, it will recover the PMM instance. We can check out our new alarm in the CloudWatch GUI.
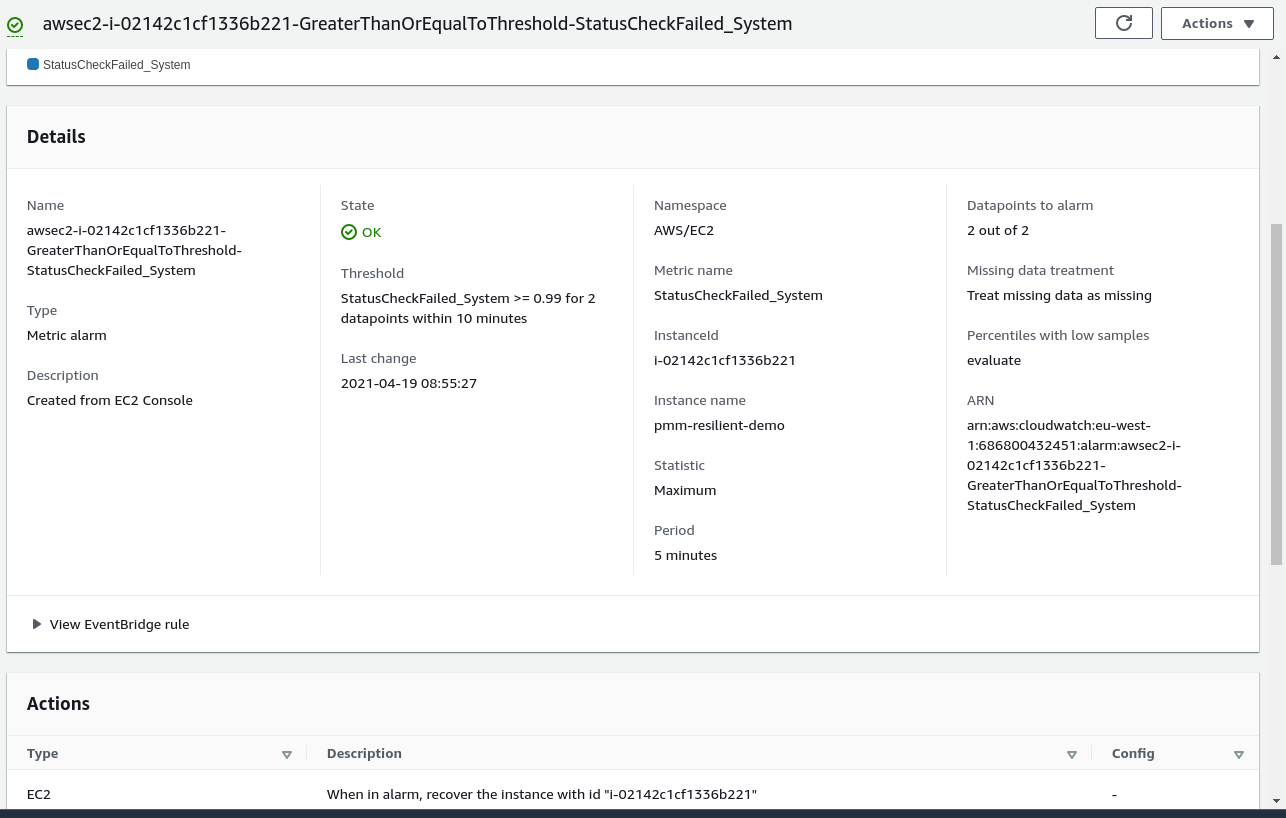
EC2 console will also show that the alarm is set up.
This example uses a pretty conservative alarm check duration of 10 minutes, spread over two 5-minute intervals. If you want to recover a PMM instance sooner, risking triggering on false positives, you can bring down the alarm period and number of evaluation periods. We also use the “maximum” of the metric over a 5-minute interval. That means a check could be in failed state only one minute out of five, but still count towards alarm activation. The assumption here is that checks don’t flap for ten minutes without a reason.
While we’re at it, we can also set up an automatic action to execute when “Instance status check” is failing. As mentioned, usually that happens when there’s something wrong within the instance: really high load, configuration issue, etc. Whenever a system check fails, an instance check is going to be failing, too, so we’ll set this alarm to check for a longer period of time before firing. That’ll also help us to minimize the rate of false-positive restarts, for example, due to a spike in load. We use the same period of 300 seconds here but will only alarm after three periods show instance failure. The restart will thus happen after ~15 minutes. Again, this is pretty conservative, so adjust as you think works best for you.
In the GUI, repeat the same actions that we did last time, but pick the “Status check failed: instance” data type, and “Reboot” alarm action.
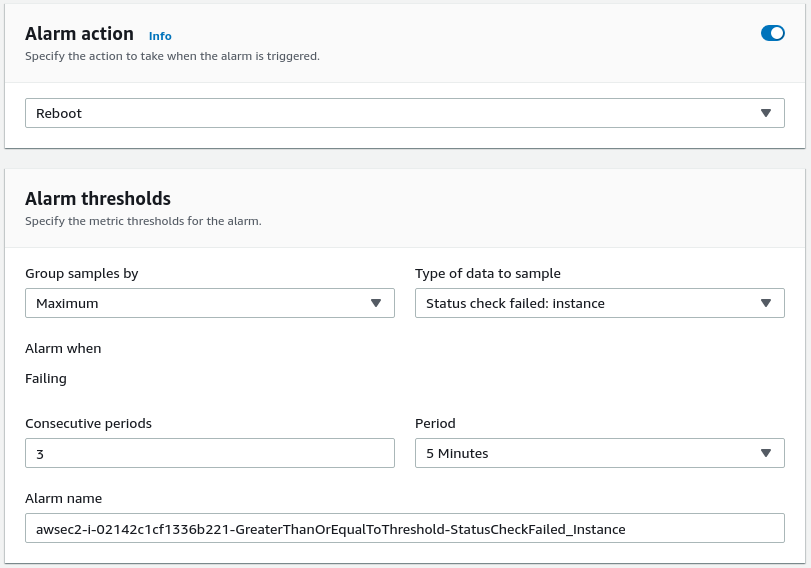
Once done, you can see both alarms reflected in the EC2 instance list.

Setting up our alarm is also very easy to do using the AWS CLI. You’ll need an AWS account with permissions to create CloudWatch alarms, and some EC2 permissions to list instances and change their state. A pretty minimal set of permissions can be found in the policy document below. This set is enough for a user to invoke CLI commands in this post.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{"Version": "2012-10-17", "Statement": [ { "Action": [ "cloudwatch:PutMetricAlarm", "cloudwatch:GetMetricStatistics", "cloudwatch:ListMetrics", "cloudwatch:DescribeAlarms" ], "Resource": [ "*" ], "Effect": "Allow" }, { "Action": [ "ec2:DescribeInstanceStatus", "ec2:DescribeInstances", "ec2:StopInstances", "ec2:StartInstances" ], "Resource": [ "*" ], "Effect": "Allow" } ] } |
And here are the specific AWS CLI commands. Do not forget to change instance id (i-xxx) and region in the command. First, setting up recovery after system status check failure.
|
1 2 3 4 5 6 7 8 9 |
$ aws cloudwatch put-metric-alarm --alarm-name restart_PMM_on_system_failure_i-xxx --alarm-actions arn:aws:automate:REGION:ec2:recover --metric-name StatusCheckFailed_System --namespace AWS/EC2 --dimensions Name=InstanceId,Value=i-xxx --statistic Maximum --period 300 --evaluation-periods 2 --datapoints-to-alarm 2 --threshold 1 --comparison-operator GreaterThanOrEqualToThreshold --tags Key=System,Value=PMM |
Second, setting up restart after instance status check failure.
|
1 2 3 4 5 6 7 8 9 |
$ aws cloudwatch put-metric-alarm --alarm-name restart_PMM_on_instance_failure_i-xxx --alarm-actions arn:aws:automate:REGION:ec2:reboot --metric-name StatusCheckFailed_Instance --namespace AWS/EC2 --dimensions Name=InstanceId,Value=i-xxx --statistic Maximum --period 300 --evaluation-periods 3 --datapoints-to-alarm 3 --threshold 1 --comparison-operator GreaterThanOrEqualToThreshold --tags Key=System,Value=PMM |
Unfortunately, it doesn’t seem to be possible to simulate system status check failure. If there’s a way, let us know in the comments. Because of that, we’ll be testing our alarms using instance failure instead. The simplest way to fail the Instance status check is to mess up networking on an instance. Let’s just bring down a network interface. In this particular instance, it’s ens5.
|
1 2 3 4 5 6 7 |
# ip link ... 2: ens5:... ... # date Sat Apr 17 20:06:26 UTC 2021 # ip link set ens5 down |
The stuff of nightmares: having no response for a command. In 15 minutes, we can check that the PMM instance is available again. We can see that alarm triggered and executed the restart action at 20:21:37 UTC.
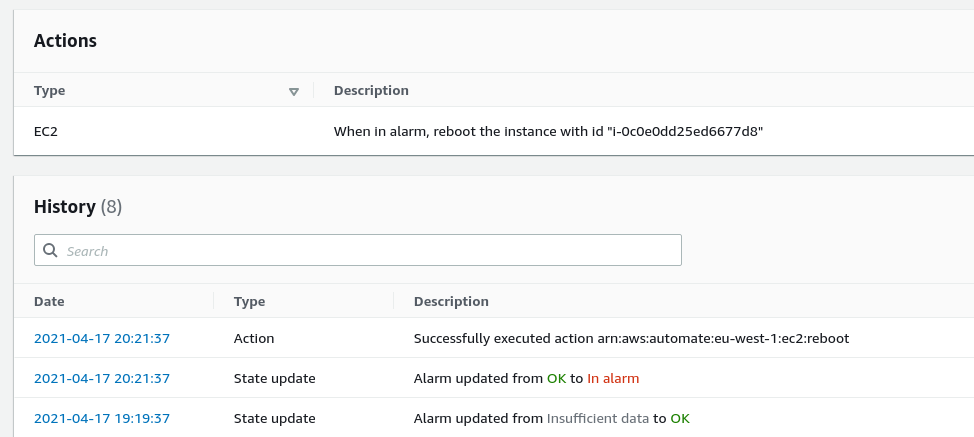
And we can access the server now.
|
1 2 |
$ date Sat Apr 17 20:22:59 UTC 2021 |
The alarm itself takes a little more time to return to OK state. Finally, let’s take a per-minute look at the instance check metric.
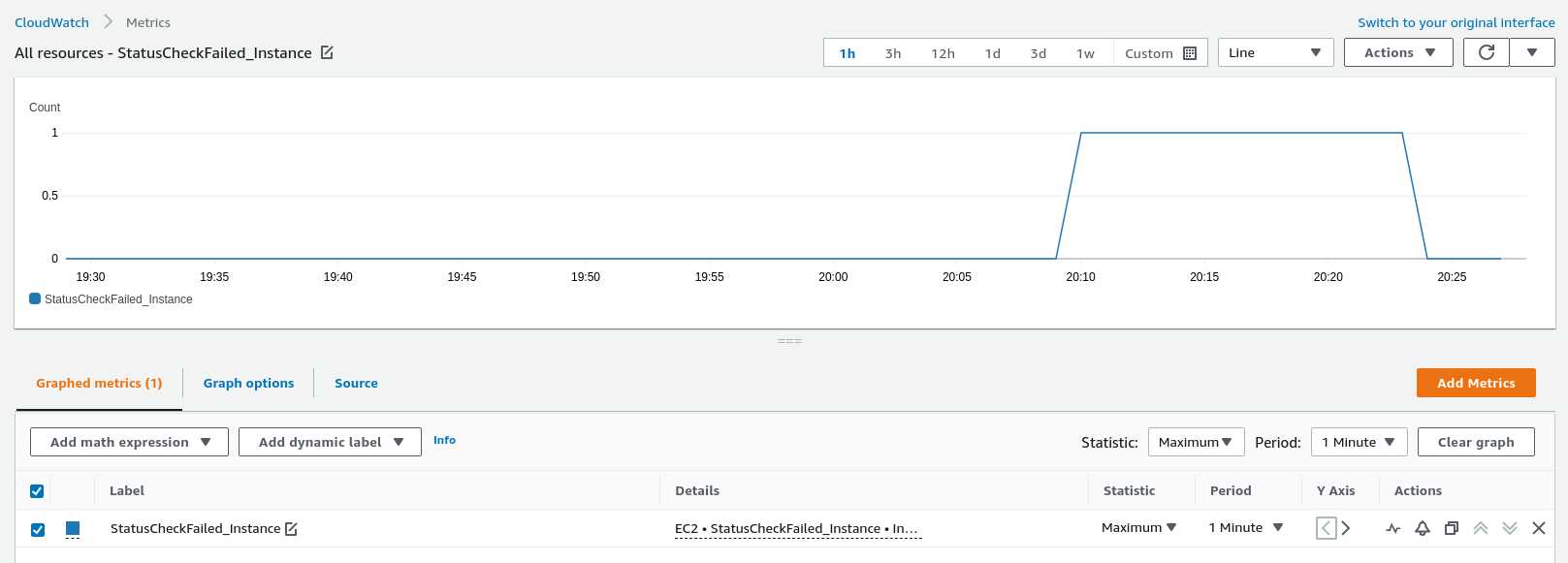
Instance failure was detected at 20:10 and resolved at 20:24, according to the AWS data. In reality, the server rebooted and was accessible even earlier. PMM instances deployed from a marketplace image have all the required service in autostart, and thus PMM is fully available after restarting without a need for an operator to take any action.
Even though Percona Monitoring and Management itself doesn’t offer high availability at this point, you can utilize built-in AWS features to make your PMM installation more resilient to failure. PMM in the Marketplace is set up in a way that should not have problems with recovery from the instance retirement events. After your PMM instance is recovered or rebooted, you’ll be able to access monitoring without any manual intervention.
Note: While this procedure is universal and can be applied to any EC2 instance, there are some caveats explained in the “What do I need to know when my Amazon EC2 instance is scheduled for retirement?” article on the AWS site. Note specifically the Warning section.
Resources
RELATED POSTS




