
 When I was in the interview process here at Percona, I was told I’d be leading the team that delivered Percona Monitoring and Management (PMM) and so naturally, I wanted to know just what that meant. I started researching the product and I got even more excited about this opportunity because as I read, PMM was actually designed…FOR ME! Well, a much younger and less gray-haired version of me, anyway. A tool designed for the SysAdmin/DBA/DevOps-y types to find and fix issues with speed! That evening I went to the website and pulled down the latest version of PMM partly to ace the interview and partly to see how easy the new wave of engineers have it compared to “my day”. Well, I struggled…BOY did I struggle!
When I was in the interview process here at Percona, I was told I’d be leading the team that delivered Percona Monitoring and Management (PMM) and so naturally, I wanted to know just what that meant. I started researching the product and I got even more excited about this opportunity because as I read, PMM was actually designed…FOR ME! Well, a much younger and less gray-haired version of me, anyway. A tool designed for the SysAdmin/DBA/DevOps-y types to find and fix issues with speed! That evening I went to the website and pulled down the latest version of PMM partly to ace the interview and partly to see how easy the new wave of engineers have it compared to “my day”. Well, I struggled…BOY did I struggle!
The installation was a breeze…basic RPM-based client with simple docker install for the server, decent instructions mostly copy/paste-able, run of the mill commands to get things connected…this was gonna be easy and I coasted all the way to the point of having registered my first MariaDB instance to my new monitoring suite… and then I slammed face-first into a brick wall! EVERYTHING worked, every command resulted in an expected response, and I had glimmers of confirmation that I was on the right track…right there on the dashboard I could see awareness of my newly added host: The number of nodes monitored went from 1 to 2…but why did I have no data about my system…why could I not see anything on the MySQL summary pages…how would I ever know how awesome Query Analytics (QAN) was without the data I was promised…but wait…THERE WAS QAN DATA…how can that be, “whyyyyyyyyyy???????……”
Look, I’m a geek at heart…a nerd’s nerd, I embrace that. I have a more robust home network than most small to midsize businesses…because why not! The house is divided into a few VLANs to ensure the guest-wifi is internet only and my kids’ devices are only given access to the web interfaces of the services they need (email, Plex, etc)…I wouldn’t call it bulletproof but it was designed with layers of security in mind. So when I installed the PMM server in my sandbox environment (its own VLAN) and tried to let it monitor my core DB I knew I’d need to make a hole for my database server to talk to this docker image on my trusty Cisco Pix 501 (R.I.P.) to allow it to talk TCP on port 443 from the DB (client) to PMM (server) and it registered no problem. But no stats…no great errors on the client side, no idea where to look for errors on the server side…stuck. I’d like to tell you I pulled out my trusted troubleshooting guide and turned to page one where it says “check the firewall dummy”, but I cannot. Surely this problem is FAR more complex and requires a complete dissection of every single component…and I was up for the challenge.
Well, I was up until probably three in the morning determined to emerge victorious when I finally threw in the towel and went to bed defeated…visions of being a Perconian and joining an elite team of super-smart people were quickly fading and I remember thinking… “If I can’t figure this out, I sure as hell wouldn’t hire me”. The next morning I woke up and went for my run and finally ran through the troubleshooting basics in my mind and realized that I’ll bet there’s good info on the firewall logs! Low and behold…my single purpose VM is trying to connect back to my DB on TCP port 42000 and 42001. That can’t be right…what on earth would be going on there… Google to the rescue, it was NOT Percona trying to harvest my ‘oh, so valuable’ blog data or family picture repository.
Turns out, this is by design.
If you don’t know, Prometheus uses a “pull” model to get data from the exporters, whereby the server reaches out to the exporter to pull the data it needs. PMM clients register to the server with a “push” model by initiating the connection from the client and pushing the registration data over TCP port 443, which it later uses to send QAN data. So in a protected network, to register then get both QAN data AND exporter metrics you need to open TCP port 443 with communication originating from the PMM client and destined to the PMM Server AND open up TCP ports 4200x originating from the PMM server destined for the client. Why the “x”, well because you need to open up a port for EACH exporter you run on the client; so just monitoring MySQL, you’ll need to open 42000 for the node stats and 42001 for MySQL, add an external exporter, also open up 42002, the same server has a proxySQL instance, open up 42003 and so on. Oh…and do this for EVERY server you want to have monitored behind that firewall. 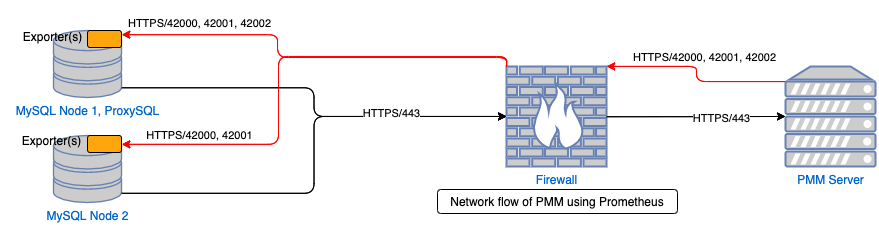
So I opened up the ports and, like magic, the data just started flowing and it was glorious. I chalked the issue up to me just being dumb and that the whole world probably knew the model of exporters. Well, it turns out, I was wrong: the whole world did not know This ends up being THE single most asked question on our PMM Forums, I think I’ve answered this question personally about 50 times in various ways. The reality is, this is an extremely common network configuration and an extremely frustrating hurdle to overcome but I guess we’re stuck with it right? NO! Not even for a second..there HAS to be a better way. We’d kicked around a few ideas of how we’d implement it but all of them were somewhat expensive from a time and manpower standpoint and all we got from it was a little less configuration for a lot of effort, we could just make the documentation better for a fraction of the cost and move on UNTIL I was introduced to a product called VictoriaMetrics.
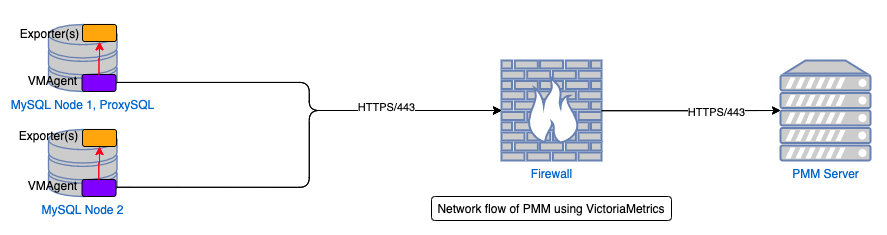
VictoriaMetrics is an alternative to Prometheus and boasts compatibility with the vast majority of Prometheus ecosystem (exporters, alertmanager, etc.) but adds some elements that are pretty cool. To start with, VictoriaMetrics can use the VMAgent installed on a client to collect the metrics on a client machine and PUSH them to the server. This instantly solves the problem of data flowing in a single, consistent direction regardless of the number of “things” being monitored per node but we’d have to add another process on the server in the form of the Prometheus PushGateway to received the data..it works but feels really clunky to add two brand new processes to solve one problem. Instead, we decided to replace Prometheus with VictoriaMetricsDB (VMDB) as its preferred method of data ingestion IS the push model (although can still perform the pull, or scrapes, of exporters directly). For us it’s not an insignificant change to implement so it better be worth it; well we think it is. The benchmarks they’ve done show the VMDB needs about 1/5th of the RAM and with its compression uses about 7x LESS disk space. As an added bonus, VictoriaMetrics supports data replication for clustering/high availability which is something very high on our list of priorities for PMM. One of the biggest hurdles for making PMM highly available is the fact that there’s not a great solution to data replication for Prometheus, all of the other DB’s in the product (PostgreSQL and ClickHouse) support clustering/high availability so paves the way to bring that to life in 2021!
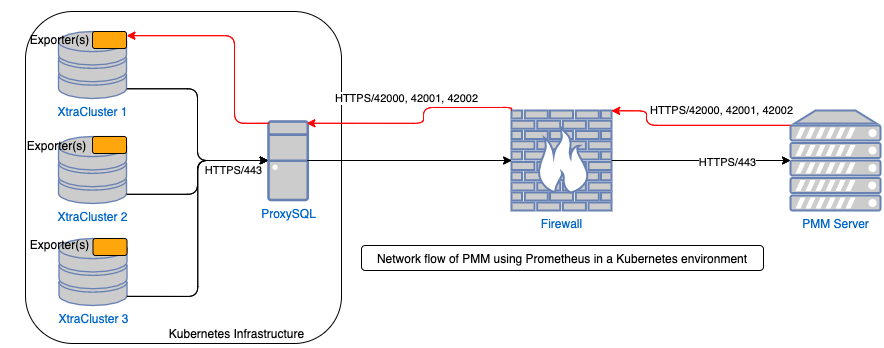
The best part is, there’s more! I’ll stay light on the technical details but turns out our desire to have a single direction (from client to server) path of communication comes in handy elsewhere: Kubernetes! As more companies are exploring what the world-famous orchestrator can do we’re seeing an increasing number of companies putting DB’s inside Kubernetes (K8s) as well (and we’re one of those companies in case you haven’t heard about our recently announced beta). Well, one of K8s core design principles is not allowing entities outside K8s to communicate directly with running pods inside…if your customer or application needs an answer, talk to the Proxy layer and it will decide what pod is best to serve your request…that way if that pod should die..you’ll never know, the orchestrator will quietly destroy and recreate it and do all the things needed to get the replacement registered and the failed pod deregistered in the load balancer! But when it comes to databases we NEED to see how each DB node in the DB cluster is performing because “healthy” from K8s perspective may not be “healthy” from a performance perspective and our “take action” thresholds will be different when it comes to increasing (or even decreasing) DB cluster sizes to meet the demands.
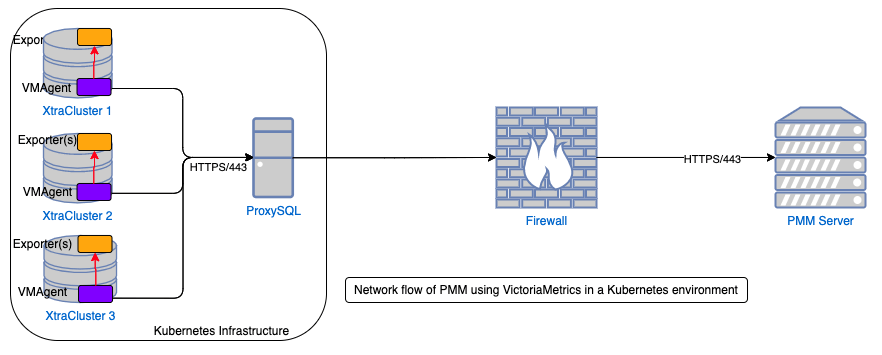
Other things we’ll get from this move and will enable over time:
The bottom line is, there are major reasons this effort needed to be undertaken, and the good news is, we’ve been working on this for the past several months in a close partnership with the VictoriaMetrics team and it’s been released! As it stands right now, this release of Percona Monitoring and Management includes the VMAgent (defaulted to pull mode still) with VMDB AND a K8s compatible pmm-client that works with Percona’s latest operator! You can test it out as you like with a new flag on the ‘pmm-admin config’ and ‘pmm-admin add’ commands to set your mode to push instead of pull. Oh, and in case you’re wondering…I got the job 😉 Enjoy and let us know what you think!
Try Percona Monitoring and Management Today!
Resources
RELATED POSTS





Wouldn’t it have been easier to implement PushProx? This is the officially supported, lightweight, reverse agent for “dial home” situations.
https://github.com/prometheus-community/PushProx
If our goal was purely resolving the Push vs Pull model, yes I’m sure that project could have worked just fine but there was more we were trying to resolve with one effort. PMM Server requires pretty sizable resources even for a small number of nodes monitored and Prometheus is always the worst offender inside our container from a RAM perspective (not saying it’s Prometheus that’s to blame at all, just how we’re using it) so seeing the reduced memory consumption under the same loads and better storage compression was an instant win. We also suffer from “holes” in the data during network blips/outages, restarts, or overloaded systems so eventually unlocking the client-side caching will help eliminate that as well. In the end there were lots of options evaluated but this route seemed to give us the biggest bang for our development dollar.