
 It is very common to see many customer cases where a sudden increase in disk space usage is caused by a lot of WAL segments filling up the WAL directory (pg_wal). Panicking customers generally ask “Why isn’t PostgreSQL deleting them?”. The most common reasons we used to find were:
It is very common to see many customer cases where a sudden increase in disk space usage is caused by a lot of WAL segments filling up the WAL directory (pg_wal). Panicking customers generally ask “Why isn’t PostgreSQL deleting them?”. The most common reasons we used to find were:
However, a different type of case started appearing in recent years, which is in the title of this post. Obviously, “slow” is subjective and mostly users refer to “slow” compared to the speed at which the WAL segment generation is happening. The recent increase in such cases is mainly triggered by an increase in processing power per host server, ever-increasing the scalability of PostgreSQL (eg, recent advancements in partitioning features, bulk data loading improvements, etc.), and faster, new-generation storage. Basically, more work is getting done per server, and as a consequence, a huge amount of WAL generation is also becoming the new normal. The reason why WAL compression is becoming a pressing need is also not different.
How backup solutions like WAL-G and pgBackRest solve this with built-in compression features is also discussed in that blog post.
Meanwhile, remote cloud storage is becoming a more attractive choice for storing archive WAL due to the price advantage over costly backup appliances and time-tested reliability. Moreover, users/organizations are becoming increasingly familiar with cloud storage, and this increase in comfort level is the major driving force in the decision-making towards cloud storage for backups.
But this rapid generation of WAL segments + slow/remote location of storage as the archive location is a deadly combination for the overall WAL archival process. Unless monitored and handled properly, it can lead to disaster.
In this blog, we are going to look at a bit of internals on how the archiver process works and how it deals with the external shell command specified in archive_command in a synchronous fashion. Additionally, we shall try to look at specific areas in this synchronous archival processing of WAL, and how it is hurting the speed of archival and becoming a challenge.
PostgresSQL’s WAL archival is very flexible because it can use an external shell command specified as the parameter value of archive_command. This feature can be used for executing any custom archive script as discussed in the previous blog. Let’s look at how the archival of WAL is initiated.
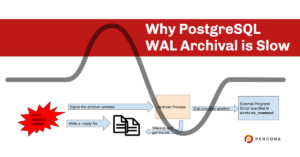
Typically, the entire chain of events for archiving starts as part of WAL writing (XLogWrite()). When a WAL segment file is completed, it notifies the archiver process that it has something to do with the segment (internal functions XLogArchiveNotifySeg -> XLogArchiveNotify ) by inserting a .ready file into archive_status directory within the pg_wal location. For example, if the WAL segment to be archived is 0000000100000001000000C6 , then the .ready file will be 0000000100000001000000C6.ready. This .ready file acts as the notification file for the archiver process. In addition to creating this file, a signal is also sent to the archiver process for waking up (sends a SIGUSR1 to archiver process). Now the archiver process can wake up and start working on all the .ready files.

All the direct communication with the archiver happens through signals. Once the archiver receives the signal ( SIGUSR1 ), it knows there is some work to be done. Then the archiver starts going through each of the files with .ready suffix and finds the oldest segment file which needs to be copied. It is important the oldest WAL segment should be the first to go to archive because:
1. This will help when restore needs to be performed, as WALs from the archives are applied in the order. If any WAL is missing in between, the recoverability will be affected.
2. The Oldest WAL segments will have a higher chance of getting recycled when a checkpoint happens. So it has a higher chance of losing.
Now let’s look at major bottles-necks in the entire operation.
Let’s look at the first problem. The method of finding out the oldest WAL segments one by one and archiving them one by one is not very efficient. For every iteration, the archiver process needs to go through complete the list of .ready files to find the oldest. In normal circumstances, this won’t be a big problem. However, in many highly active servers and slow backup storage, we are experiencing the archival lagging behind by several thousand to million WAL segments. In those circumstances, doing a directory listing and iterating over .ready files become highly ineffective and this adds more slowness to WAL archiving – which is already lagging. The cumulative effect leads to dangerous conditions if left unnoticed.
The second problem of slowness starts here. Once the segment is identified, that needs to be archived. An internal function pgarch_archiveXlog() is called which will be invoking system() system call to execute external commands/scripts which is specified as archive_command. This command generally takes 2 arguments – %p, which will be the relative path of the source segment file, and %f which specifies the filename of the source segment file. Once the external shell command is executed by system() call, its return value is checked for understanding whether the execution was successful (WAL is archived) or failed. Basically the archiver waits for the external commands to return. If the external script has latency for execution due to some reason, all the latencies will add up.
If there is a failure/timeout in the underlying system while executing the archive_command, the archiver will wait for a second more before reattempting. so slow and storage connected over the WAN has more chances of waiting for more time. A WAL segment will be archived only if the previous one is successful. Once the external shell command returns successfully (above-mentioned, pgarch_archiveXlog() function will be successful), this .ready notification file will be renamed to .done by the archiver pgarch_archiveDone().
One of the frequently asked questions here is “Do we need to script for removing the WALs segments and .done files which are already archived?” The answer is No. The checkpoint process will do it for you. It will delete both .done and corresponding WAL segment files (recycling of WAL segment files is considered). If there any .ready files remain in the archive_staus directory for which the corresponding WAL segment is already recycled or removed, those .ready files will be removed by the archiver process itself.
As we discussed there are only two notification statuses – .ready or .done. There is no notification status for archive “in-progress“, which is essential if multiple, concurrent archival needs to happen. So by very design, it is not there. Unless a success of the WAL archival is reported back and .ready file is renamed to .done, we consider that the archival has never happened. So if any failure happens in between, PostgreSQL will attempt the archive again (sometimes recopy the same file).
Advanced backup solutions like pgBackRest have the asynchronous backup feature which will allow multiple background worker processes to do the compression and WAL archive push while a frontend will be acknowledging back to PostgreSQL. We will be covering this in an upcoming blog post.
The synchronous operation of WAL archiving is becoming more and more of a pain as of late. This entire operation of WAL archive goes one after another for every outstanding WALs in a loop until there are no more WAL segments to archive. There is a high chance of WAL segments getting piled up in pg_wal directory if the rate of WAL segment generation exceeds the rate of archiving, and the problem worsens as the number of .ready files increases. The archiver wakes up and does all of the iterations discussed above once it receives the signal (SIGUSR1), and the process continues until a SIGUSR2 is received. There is no built-in mechanism to make it asynchronous. However, since PostgreSQL uses external command/scripts for the archiving operation, a smart program/script can convert this entire synchronous operation into asynchronous. This underlines the need for a backup tool that can push the WAL archives in an asynchronous fashion.
Our white paper “Why Choose PostgreSQL?” looks at the features and benefits of PostgreSQL and presents some practical usage examples. We also examine how PostgreSQL can be useful for companies looking to migrate from Oracle.
Resources
RELATED POSTS




