
 There were two new releases in the OpenSource Analytical Databases space, which made me want to evaluate how they perform in the Star Schema Benchmark.
There were two new releases in the OpenSource Analytical Databases space, which made me want to evaluate how they perform in the Star Schema Benchmark.
I covered Star Schema Benchmarks a few times before:
What are the new releases:
MariaDB 10.5 comes with built-in ColumnStore and an interesting capability to replicate data from InnoDB to ColumnStore in real-time within the same instance, and they named it “hybrid transactional and analytical processing”.
For ClickHouse, there was not a single release, but continuous improvements for the last three years to support JOIN queries, support of updating data, and improved integration with MySQL.
For the ClickHouse testing, I will use the 20.4.6 version.
For the benchmark I will Star Schema Benchmark with scale factor 2500, which in sizes is:
Star Schema Benchmark prescribes to execute 13 queries and I will measure execution time for each query.
Example of table schemas and queries you can find in my results repo:
Side note: ClickHouse documentation provides examples for Star Schema queries, however, they took a denormalization approach, which is valid, but does not allow to test how original queries with 3-way JOINs would perform, which is my goal in this experiment.
The first result I want to see is how long it would take to load 15bln rows into the database and what the final table size will be.
ClickHouse:
time clickhouse-client –query “INSERT INTO lineorder FORMAT CSV” < lineorder.tbl
real 283m44.217s
user 557m13.079s
sys 17m28.207s
ColumnStore:
time cpimport -m1 -s”,” -E ‘”‘ sbtest lineorder lineorder.tbl
real 800m11.175s
user 767m50.866s
sys 22m22.703s
ClickHouse:
root@nodesm:/data/sdd/clickhouse/data# du -sh default
355G default
ColumnStore:
root@nodesm:/data/sdd/cs# du -sh data1
625G data1

Now I want to compare query execution times for ColumnStore and ClickHouse. I will use queries as close to the original as possible, but for ClickHouse I still need to adjust queries in order to be able to execute them.
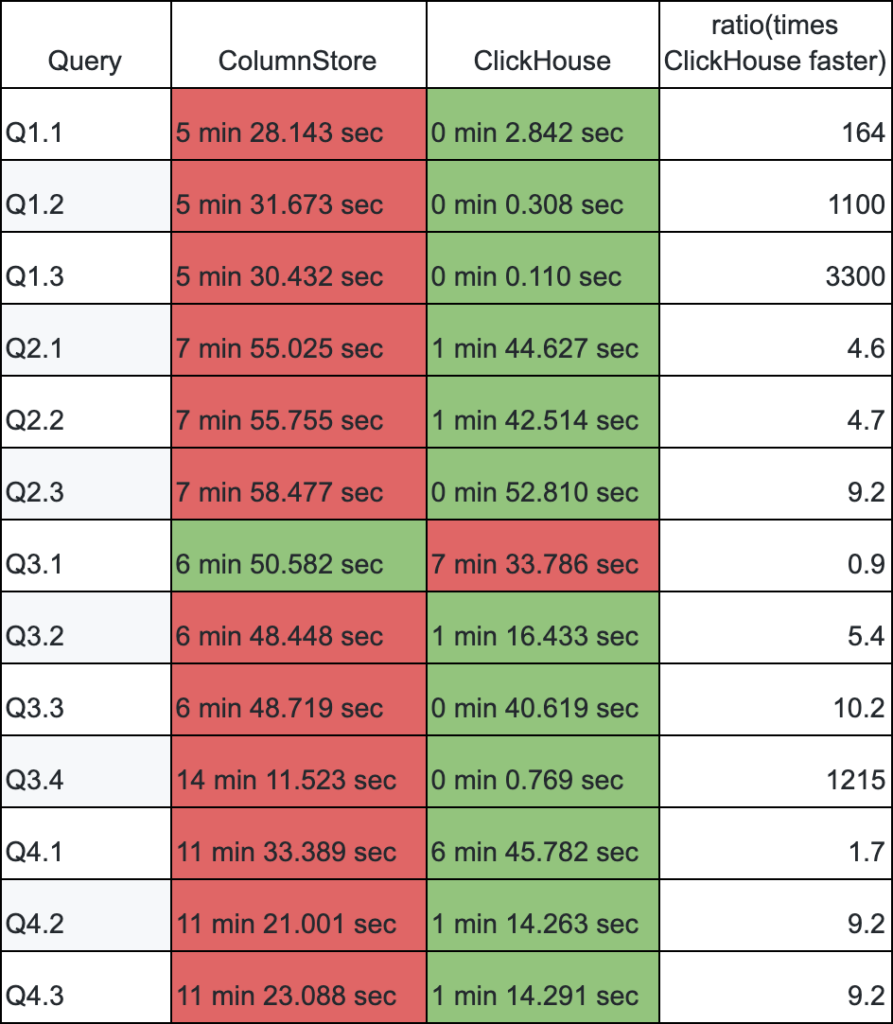
We can see that ClickHouse outperforms, sometimes by a huge margin, in all queries but one – Query 3.1. Also, query 4.1 is particularly hard for ClickHouse.
I mentioned that to run queries in ClickHouse they still need modifications, so let’s take a look.
If three years ago (see the blog I mentioned earlier, ClickHouse in a General Analytical Workload – Based on a Star Schema Benchmark), a 3-way JOIN query like:
|
1 2 |
SELECT sum(LO_REVENUE),P_MFGR, toYear(LO_ORDERDATE) yod FROM lineorderfull ,customerfull,partfull WHERE C_REGION = 'ASIA' and LO_CUSTKEY=C_CUSTKEY and P_PARTKEY=LO_PARTKEY GROUP BY P_MFGR,yod ORDER BY P_MFGR,yod; |
Had to be written as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
SELECT sum(LO_REVENUE), P_MFGR, toYear(LO_ORDERDATE) AS yod FROM ( SELECT LO_PARTKEY, LO_ORDERDATE, LO_REVENUE FROM lineorderfull ALL INNER JOIN ( SELECT C_REGION, C_CUSTKEY AS LO_CUSTKEY FROM customerfull ) USING (LO_CUSTKEY) WHERE C_REGION = 'ASIA' ) ALL INNER JOIN ( SELECT P_MFGR, P_PARTKEY AS LO_PARTKEY FROM partfull ) USING (LO_PARTKEY) GROUP BY P_MFGR, yod ORDER BY P_MFGR ASC, yod ASC |
Now, the multi-table queries can be written as:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT toYear(LO_ORDERDATE) AS year, C_NATION, SUM(LO_REVENUE - LO_SUPPLYCOST) AS profit FROM lineorder INNER JOIN customer ON C_CUSTKEY = LO_CUSTKEY INNER JOIN supplier ON LO_SUPPKEY = S_SUPPKEY INNER JOIN part ON P_PARTKEY = LO_PARTKEY WHERE (C_REGION = 'AMERICA') AND (S_REGION = 'AMERICA') AND ((P_MFGR = 'MFGR#1') OR (P_MFGR = 'MFGR#2')) GROUP BY year, C_NATION ORDER BY year ASC, C_NATION ASC |
Pretty much a query with standard JOIN syntax.
Word of Caution:
Even though queries in ClickHouse look like normal JOIN queries, ClickHouse DOES NOT HAVE query optimizer. That means that tables will be joined in the order you have written them, and ClickHouse will not try to change table order for the optimal execution. This task is still on developers.
With human intervention, it is still possible to improve Query 3.1 for ClickHouse, if we write it in the following form (Thanks to Alexander Zaytsev from Altinity for the help!):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT C_NATION, S_NATION, toYear(LO_ORDERDATE) AS year, SUM(LO_REVENUE) AS revenue FROM lineorder INNER JOIN customer ON C_CUSTKEY = LO_CUSTKEY INNER JOIN supplier ON LO_SUPPKEY = S_SUPPKEY WHERE LO_CUSTKEY in (select distinct C_CUSTKEY from customer where C_REGION = 'ASIA') AND LO_SUPPKEY in (select distinct S_SUPPKEY from supplier where S_REGION = 'ASIA') AND AND year >= 1992 AND year <= 1997 GROUP BY C_NATION, S_NATION, year ORDER BY year ASC, revenue DESC; |
Execution time for query 3.1 is reduced from 7 min 33 sec to 5 min 44 sec.
It is possible that other queries also can be improved, but I want to keep them in the original form.
Update queries are not part of Star Schema Benchmark, but this question is quite regular.
Can we update data AND how well UPDATE queries are performing, because it can be a challenge for analytical databases?
For this, ClickHouse introduced a special UPDATE syntax, which looks like ALTER TABLE … UPDATE to highlight this is not a typical UPDATE statement.
Also it is worth noting that ALTER TABLE UPDATE in ClickHouse is executed in an asynchronous way, meaning that until it is finished you may see inconsistencies during the period while changes are applied.
So let’s execute the query:
|
1 |
ALTER TABLE lineorder UPDATE LO_QUANTITY = LO_QUANTITY-1 WHERE 1=1; |
ClickHouse:
Please note this query will update 15 bln rows, which is not a trivial task!
We can see how long it will take to apply the changes. For this, I will run the following query
|
1 |
clickhouse-client -m default -q " select toYear(LO_ORDERDATE) year, sum(LO_QUANTITY) from lineorder GROUP BY year;" |
in the loop to see when sum(LO_QUANTITY) is adjusted for new values.
The result: It took about 2 mins after ALTER TABLE query for SELECT query to reflect new values.
ColumnStore:
For the ColumnStore I will use the normal UPDATE syntax:
|
1 |
UPDATE lineorder SET LO_QUANTITY = LO_QUANTITY-1; |
The query is performed in a synchronous way and it is transactional.
I waited 6 hours for the query to finish, and at that point, I had to kill it, as I could not wait any longer.
Again, please note the difference in executing updates:
ClickHouse – the update is run asynchronous and is NOT transactional, which likely will result in read queries returning inconsistent results while UPDATE is running.
ColumnStore – the update is synchronous and transactional. Likely this is why it takes that long to update 15bln rows.
So obviously, if it comes to preference, I would choose ClickHouse given query execution times, data load times, and new improved JOIN syntax.
The benefit of ColumnStore is that it comes in a single MySQL-like package (MariaDB-flavor) and there is an easy way to integrate data flow from InnoDB to ColumnStore.
ClickHouse makes improvements for integrations with MySQL (see ClickHouse and MySQL – Better Together, but there is still room for improvements!
For reference – the hardware I used is:
Architecture: x86_64
CPU(s): 48
On-line CPU(s) list: 0-47
Thread(s) per core: 2
Core(s) per socket: 12
Socket(s): 2
NUMA node(s): 2
CPU family: 6
Model: 63
Model name: Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50GHz
and SATA SSD storage and 128GB of RAM
You can find queries and the results on our GitHub repository:
https://github.com/Percona-Lab-results/Clickhouse-ColumnStore-SSB-Jul2020





> Also it is worth noting that ALTER TABLE UPDATE in ClickHouse is executed in an asynchronous way, meaning that until it is finished you may see inconsistencies during the period while changes are applied.
There is a setting
mutations_sync. When set to 1, the query will wait for mutation to finish.Cool. Great addition!
> Now, the multi-table queries can be written as
You could leave the query unchanged. ClickHouse tries to rewrite commas with CROSS JOINs and CROSS JOINs with INNER ones itself. But it’s better to check if there’s no CROSS JOINs left. You could do it with such queries:
set enable_debug_queries = 1;
analyze ;
You could find some CROSS JOINs not rewritten to INNER ones cause ClickHouse can’t change table order in JOIN for now and can not split some complex WHERE clauses to extract ON section for INNER JOIN. So a query with commas instead of explicit JOIN could be silently slow.
analyze select … ;
First of all, another demonstration of great performance from Clickhouse. Credit to Robert Hodges, Altinity, and everyone working on Clickhouse for great work.
There a few adjustments to the benchmarking methodology I would recommend to get to a more direct comparison:
CH=Clickhouse
CS=Columnstore
1) CH from memory vs CS from storage. CS detects patterns in the data and uses that for partition elimination. Default dbgen is completely randomized yielding no partition elimination. Loading by weekly batches would allow for queries like q1-3 (d_weeknuminyear=6 and d_year=1994) to use about 0.03% of the memory to run with CS. Many, but not all queries would run from memory.
2) Inconsistent # of joins between CH and CS.
SSB has query sets with growing complexity:
Q1.x joins 2 tables
Q2.x joins 3 tables
Q3.x joins 4 tables
Q4.x joins 5 tables
The CH queries are run without the dim_date table:
Q1.x no joins
Q2.x joins 2 tables
Q3.x joins 3 tables
Q4.x joins 4 tables
Option A – include the dim_date table for both engines..
Maybe better option to match the benchmark?
Option B – exclude the dim_date table for both engines..
SSB Q1.3 query
and dim_date.d_weeknuminyear = 6 and dim_date.d_year = 1994
CH: rewrite
(toISOWeek(LO_ORDERDATE) = 6) AND (toYear(LO_ORDERDATE) = 1994)
Potential CS rewrite:
Q LO_ORDERDATE > date_add(‘1994-01-01’,INTERVAL 6 week) and LO_ORDERDATE < date_add('1994-01-01',INTERVAL 6 + 1 week)
3) Uint32 instead of Decimal with CH DDL. Columns lo_quantity, lo_extendedprice, lo_ordtotalprice, lo_discount, lo_revenue, and lo_supplycost should all be decimal.
This may be by design with CH. They do have functions to convert Uint32 to Decimal, but I don't see them in the queries so not really sure what results actually happen.
SELECT toDecimal32(2, 4) AS x, x / 3
┌──────x-─┬─divide(toDecimal32(2, 4), 3)─┐
│ 2.0000 │ 0.6666 │
└────────┴───────────────-────┘
I see some discussions here on what happens with clickhouse-client wire protocol vs. without:
https://github.com/ClickHouse/clickhouse-go/issues/148
https://clickhouse.tech/docs/en/sql-reference/data-types/decimal/
There are performance benefits of integer over decimal, and many/most systems declare+enforce decimal and store internally as integer (but hiding any manual conversion from the end-user).
I think the SSB amount columns are in fractional pennies (or just pennies) so they have to decimal point, and INT is fine for them. The application would them into dollar amounts. It assumes that the underlying database doesn’t have a fixed precision fractional type.
*no decimal point
the type should be the same in both databases though because decimal is slower than int
If the server crashes during the “mutation” are the changed rows rolled back?
What SSB dbgen do you use? As I recall the dbgen from the paper generates invalid SSB datasets when SF>1000. Also the ssb benchmark paper says you are supposed to run each query on cold cache (db restart with flushed os cache). Each query in each flight filters data more progessively (needle in haystack) so if you aren’t going to restart db you might want to run them in reverse order (3.3, 3.2, 3.1) as with large buffers you won’t be doing as much IO for the later queries in a flight.
Just some thoughts 🙂
Also, to be fair, you could do the “update” on columnstore by:
CREATE TABLE new_table as SELECT …
Then swap the tables when you are done. That would be a lot faster than trying to update 15B rows, which is something nobody would ever do in a single transaction in any database, if we are being honest with ourselves. Also, I think it is unfair to test different queries against the two databases and compare them as if they are the same. Run the same queries on columnstore, and see how it fairs.
Justin,
You and Jim bring are valid point. I will incorporate them in my next evaluation.