
In this post, I want to evaluate Group Replication Scaling capabilities in cases when we increase the number of nodes and increase user connections. While this setup is identical to that in my post “Evaluating Group Replication Scaling Capabilities in MySQL”, in this case, I will use an I/O bound workload.
For this test, I will deploy multi-node bare metal servers, where each node and client are dedicated to an individual server and connected between themselves by a 10Gb network.
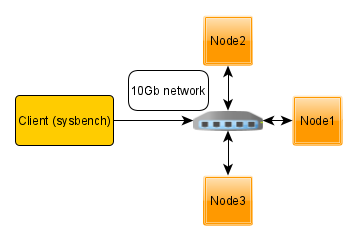
Also, I will use 3-nodes and 5-nodes Group Replication setup. In both cases, the load is directed only to ONE node, but I expect with five nodes there is some additional overhead from replication.
Hardware specifications:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
System | Supermicro; SYS-F619P2-RTN; v0123456789 (Other) Service Tag | S292592X0110239C Platform | Linux Release | Ubuntu 18.04.4 LTS (bionic) Kernel | 5.3.0-42-generic Architecture | CPU = 64-bit, OS = 64-bit Threading | NPTL 2.27 SELinux | No SELinux detected Virtualized | No virtualization detected # Processor ################################################## Processors | physical = 2, cores = 40, virtual = 80, hyperthreading = yes Models | 80xIntel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz Caches | 80x28160 KB # Memory ##################################################### Total | 187.6G |
For the benchmark, I use sysbench-tpcc 1000W prepared database as:
|
1 |
./tpcc.lua --mysql-host=172.16.0.11 --mysql-user=sbtest --mysql-password=sbtest --mysql-db=sbtest --time=300 --threads=64 --report-interval=1 --tables=10 --scale=100 --db-driver=mysql --use_fk=0 --force_pk=1 --trx_level=RC prepare |
The configs, scripts, and raw results are available on our GitHub. The workload is IO-bound, that is, data (about 100GB) exceeds innodb_buffer_pool (also 25GB).
For the MySQL version, I use MySQL 8.0.19.
Let’s review the results I’ve got. First, let’s take a look at how performance changes when we increase user threads from 1 to 256 for three nodes.
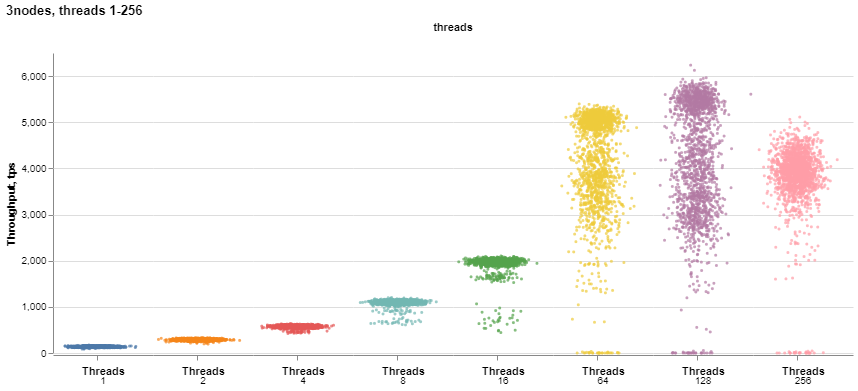
It is interesting to see how the results become unstable when we increase the number of threads. For more detail, let’s draw the chart with the individual scales for each set of threads:
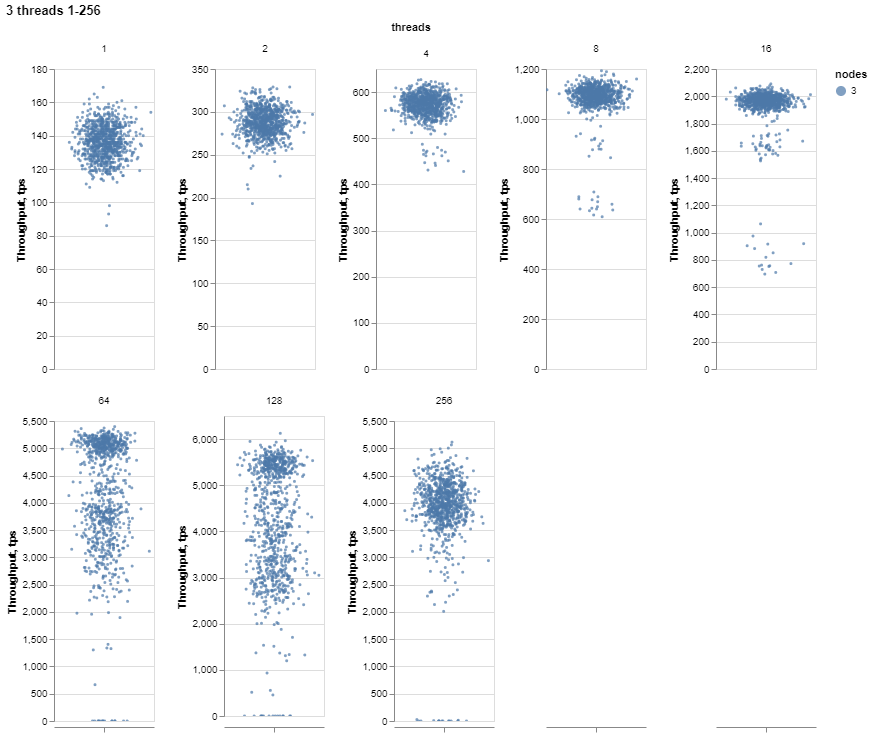
As we can see, there are a lot of variations for threads starting with 64. Let’s check the 64 and 128 threads with a 1-sec resolution.
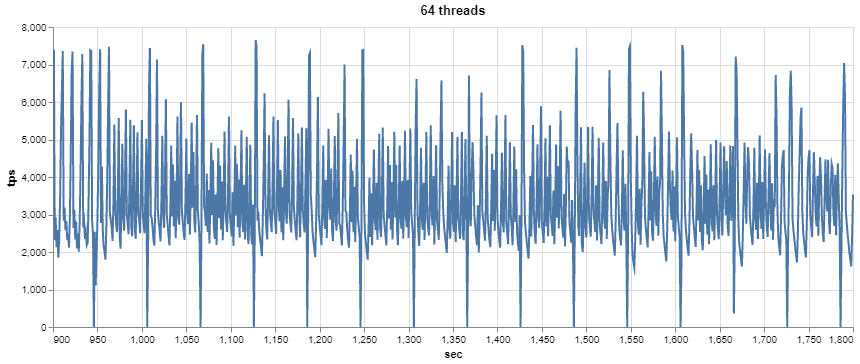
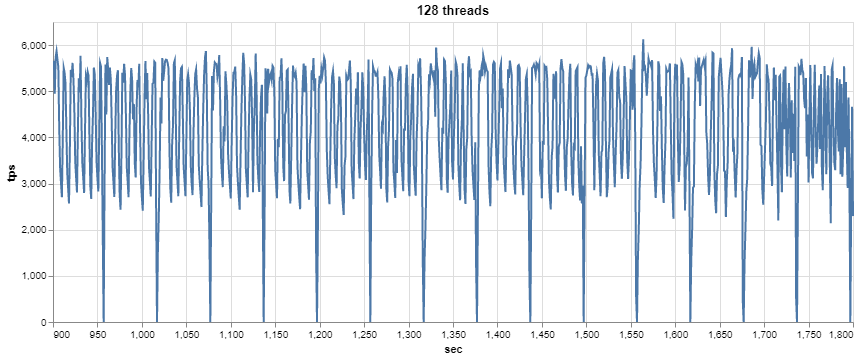
It looks as if cyclical processes are going on, with periodical drops to 0, which may be related to this bug.
Now let’s take a look at the performance under five nodes (compared to 3 nodes):
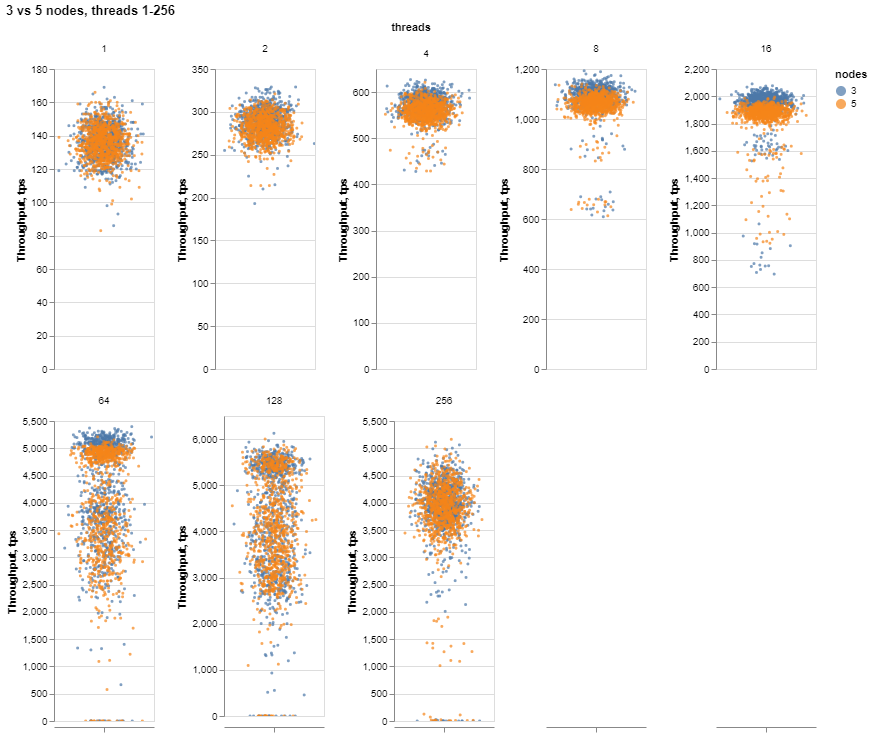
There does not seem to be a huge difference, and only when there are stable results with 8-16 threads can we see a decline for five nodes. For threads 64 to 256, when the variance is prevailing, it is hard to notice the difference.
As there are occasional drops in high threads, I wanted to check how the cluster would handle sustained incoming rate, which is about 75% of average throughput. For this, I will test on 64 threads with incoming rate 3100 transactions per sec (the average throughput for three nodes under 64 threads is 4100 tps).
First, let’s see how the system handles throughput.
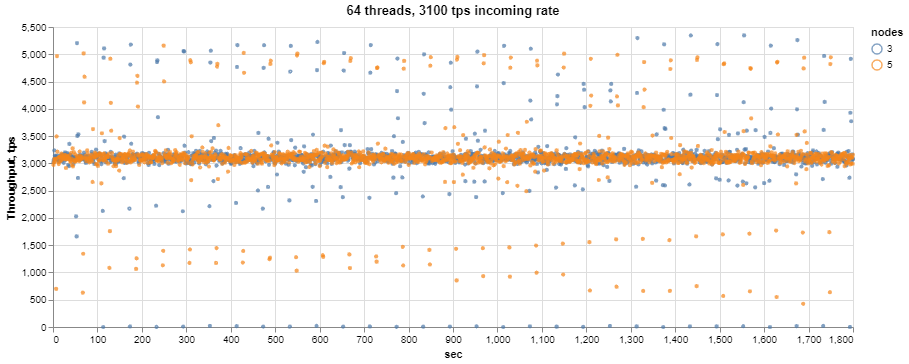
We can see that most of the time, the throughput is 3100 tps, but there are still intermittent drops as well as jumps with the return to the regular incoming rate. Now, more interesting – how does it affect latency?
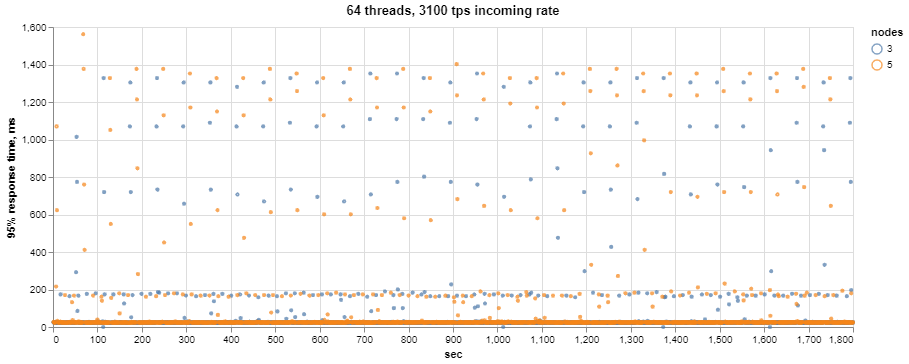
While, again, most of the time, the system shows about 25ms 95% response time, during the drops, it jumps up to 1400ms, which obviously will result in a bad application and user experience.
From my findings, it seems that in I/O bound workload cases, Group Replication also handles extra nodes quite well in this workload, but the multiple threads are still problematic. I am open to suggestions on how the multiple threads performance can be improved, so please leave your comments below.
Resources
RELATED POSTS




