
 Abstract: Storage engine algorithmic gains have mostly settled and Moore’s law for CPU speed is bottoming out, but database performance still stands to increase ~10x thanks to continuing NAND Flash improvement, Optane, Flash-idiomatic SSD drives (e.g. OpenChannel, Zoned Namespaces), KeyValue SSD, etc. The downside is each storage engine revolution historically has broken encapsulation/reuse and required DBMS developers to remake backup and restore, high availability, diagnostics, etc. This article aims to create a checklist of necessary features that should be in new db-accelerating disks before we buy into them.
Abstract: Storage engine algorithmic gains have mostly settled and Moore’s law for CPU speed is bottoming out, but database performance still stands to increase ~10x thanks to continuing NAND Flash improvement, Optane, Flash-idiomatic SSD drives (e.g. OpenChannel, Zoned Namespaces), KeyValue SSD, etc. The downside is each storage engine revolution historically has broken encapsulation/reuse and required DBMS developers to remake backup and restore, high availability, diagnostics, etc. This article aims to create a checklist of necessary features that should be in new db-accelerating disks before we buy into them.
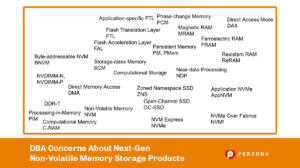
Over the last two decades, the performance of databases has increased by approximately 100-fold per server. Part of that ~x100 was the software improvements but mostly it is thanks to better hardware, especially the HDD -> Flash SSD upgrade.
There are more upcoming gifts from the silicon heavens that will soon improve database performance ~x10, and maybe even another x10 on top of that by the time they’re done.
These will have performance benefits for all sorts of software, but for databases let’s summarize it roughly as:
All the new storage devices above can implement a key-value datastore and, depending on a few other factors, can probably be wrapped as a storage engine for DBMSes like MySQL or MongoDB.
“Another victory just around the corner” you might think, “thank goodness current-generation DBMSes are built in the paradigm of code reuse and encapsulation”.
The evolutionary paths opening up now are quite numerous. The choices for the storage engine developers at the moment are:
That is now. When it gets to the next generation of persistent memory it will all start again. There will be a new userspace interface, new kernel drivers, new FPGA/ASICs on the pluggable drive/memory, etc.
The storage solution providers will provide the above, so it might seem as though we just have to be patient for now and then, when the winning solutions arrive, retrain ourselves to learn new performance analysis and tuning techniques.
But with industry history as our guide the new, plug-in database storage engines being delivered to the market will only be complete for the single-server database. I.e. I predict they will ship the product out the door without the following.
I think storage engine developers forget that as a business-imposed rule basically all database deployments have two external systems that are supposed to capture everything. Taking backups and having replicasets is how we user-proof and power-failure-proof the database.
To make this efficient the new storage engines should have the following to get the data out efficiently to external backup, or replicas:
Fast backup with consistency isn’t just a nice-to-have; higher write throughput and sizes > 10TB on a single drive will need to be accommodated by the time this technology becomes commonplace in datacenters. Slower, up-the-stack backup methods like classic database table dumps won’t finish within reasonable times for the new middle-size, let alone big-size, databases.
The hot backups we have today are ‘bolt-on after’ systems. It wasted a lot of developer and DBA time, and fragmentation between the alternatives continues to divide engineering hours and hence the progress the industry makes. So let’s make hot backup and efficient replication an initial requirement this time.
Storage engines (e.g. InnoDB or WiredTiger) might be replaced by drives that do basically all the indexing, consistency guarantee, clean-up processing, etc., on the drive without any execution path involving the db software on the CPU. The internal engine metrics current storage engines include should be matched with equivalents reporting activity within in-situ processing drives.
DBAs need it for monitoring, and engineers examining defects in the field are blind without them.
With the existing file-based databases the “mongod” or “mysqld” or “postgres” etc. user owns the database file. “chown -R dbuser:dbgroup /data/db; chmod 660 /data/db/files*”. Unless you subvert it, accidentally or deliberately, other (non-root) processes won’t have access to the db records in those files.
There are some solutions that will provide a Key-value API by NVMe commands without having any filesystem though.
How does access control work when they are no files? How does, say, a Key-value SSD discriminate between user processes?
So far, as my current reading goes, the consensus-finding for that hasn’t started in earnest yet.
I am quite eager to get started with the new NVM, whether an SSD drive or permanent memory in DIMMS, to have storage engines that will put pre-2020 state-of-the-art database performance to shame.
But at the same time, to avoid needless double-work across the database industry, I don’t think we should put these drives to use in our general-purpose DBMSes until they natively support all the following:




