
 In this blog post, we will share some experiences with the hidden gem in MySQL called MyRocks, a storage engine for MySQL’s famous pluggable storage engine system. MyRocks is based on RocksDB which is a fork of LevelDB. In short, it’s another key-value store based on LSM-tree, thus granting it some distinctive features compared with other MySQL engines. It was introduced in 2016 by Facebook and later included, respectively, in Percona Server for MySQL and MariaDB.
In this blog post, we will share some experiences with the hidden gem in MySQL called MyRocks, a storage engine for MySQL’s famous pluggable storage engine system. MyRocks is based on RocksDB which is a fork of LevelDB. In short, it’s another key-value store based on LSM-tree, thus granting it some distinctive features compared with other MySQL engines. It was introduced in 2016 by Facebook and later included, respectively, in Percona Server for MySQL and MariaDB.
The original paper on LSM was published in 1996, and if you need a single takeaway, the following quote is the one: “The LSM-tree uses an algorithm that defers and batches index changes, cascading the changes from a memory-based component through one or more disk components in an efficient manner reminiscent of merge sort.” At the time, disks were slow and IOPS expensive, and the idea was to minimize the write costs by essentially turning random write load into a sequential one. The technology is quite popular, being a foundation or inspiration in a multitude of databases and storage engines: HBase, LevelDB, RocksDB, Tarantool, WiredTiger, and more. Even in 2020, when storage is faster and cheaper, LSM-tree can still provide substantial benefits for some workloads.
The development of MyRocks was started around 2015 by Facebook. Yoshinori Matsunobu gave multiple presentations, detailing the reasoning behind using RocksDB inside MySQL. They were underutilizing the servers because they were constrained in disk space and MyRocks allowed for better space efficiency. This better space efficiency is inherent for LSM tree storage engines.
So far, MyRocks continues to be a somewhat niche solution, and, frankly, not a lot of people know about it and consider its use. Without further ado, let’s see how it works and why would you want to use it.
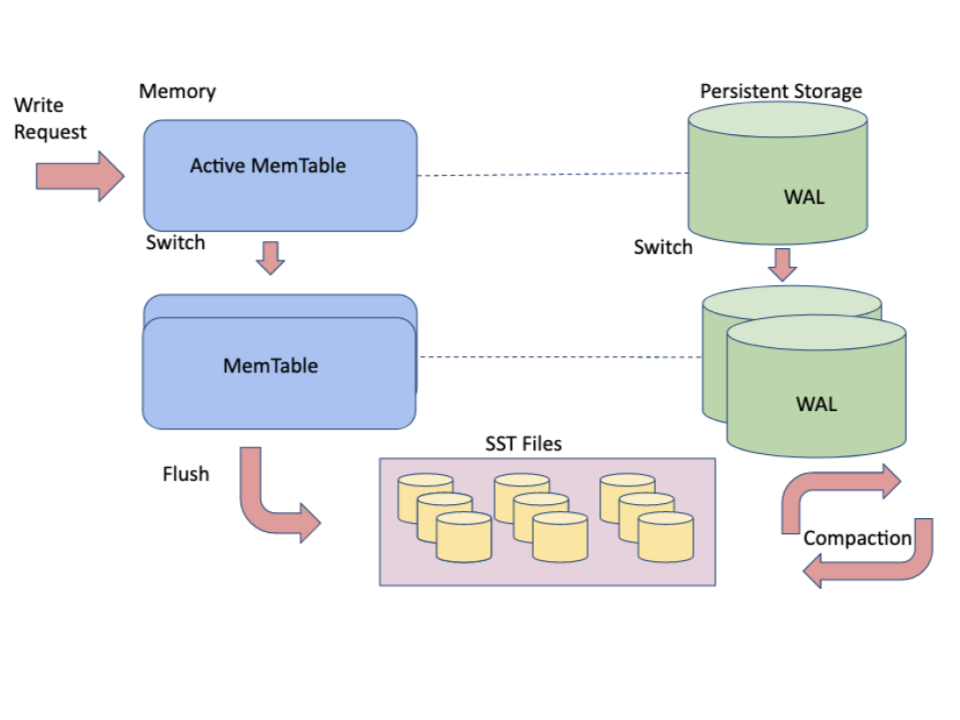
MyRocks engine is based on LSM-tree structure, which we have mentioned above. That makes it a very different beast than InnoDB. So let’s take a high-level overview of MyRocks internals. First, how does row-based data fit into key-value store? You can think of a regular clustered index as a key-value structure on its own: there’s a key, which value is a whole row. Secondary indexes can have primary indexes’ key as value, and additionally a column data value.
All writes in MyRocks are done sequentially to a special structure called memtable, one of the few mutable structures in the engine. Since we need the writes to actually be durable, all writes are also written to WAL (a concept similar to InnoDB redo log), which is flushed to disk. Once the memtable becomes full, it’s copied in memory and made immutable. In the background, the immutable memtables will be flushed to disk in the form of sorted string tables (SSTs), forming the L0 of the multi-leveled compaction scheme. During this initial flush, changes in the memtable are deduplicated (a thousand updates for one key become a single update). Resulting SSTs are immutable, and, on L0, have overlapping data.
As more SSTs are created on L0, they will start to pour over to L1…L6. On each level after L0, data within SSTs is not overlapping, thus compaction can proceed in parallel. Compaction takes an SST from the higher level, and merges it with one (or more) SSTs on the lower level, deleting the originals and creating new ones on the lower level. Eventually, data reaches the lowest level. As you can see below, each level has more and more data, so most data is actually stored at the lower levels. The merge mentioned happens for Key Value pairs, and during the merge KV on the lower level will always be older than KV on the higher one, and thus can be discarded.
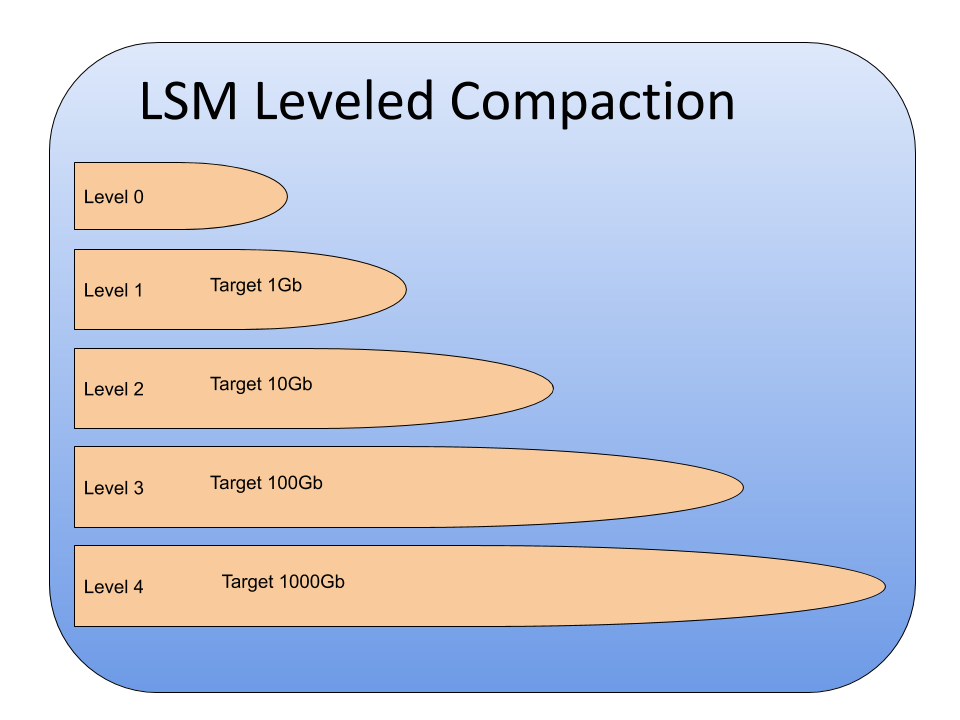
Having immutable SSTs allows them to be filled to 100% all the time, improving space utilization. In fact, that’s one of the selling points of MyRocks, as it allows for greater space efficiency. In addition to the inherent compactness of the SSTs, data there is also compressed, which further minimizes the footprint. An interesting feature here is that you can specify different compression algorithms for the bottommost (where, by nature, most of the data is) and other levels.
Another important component for the MyRocks engine is Column Family (CF). Each key-value pair (or, in familiar terms, each index) is associated with a CF. Quoting the Percona Server for MySQL docs: “Each column family has distinct attributes, such as block size, compression, sort order, and MemTable.” In addition to controlling physical storage characteristics, this provides atomicity for queries across different key spaces.
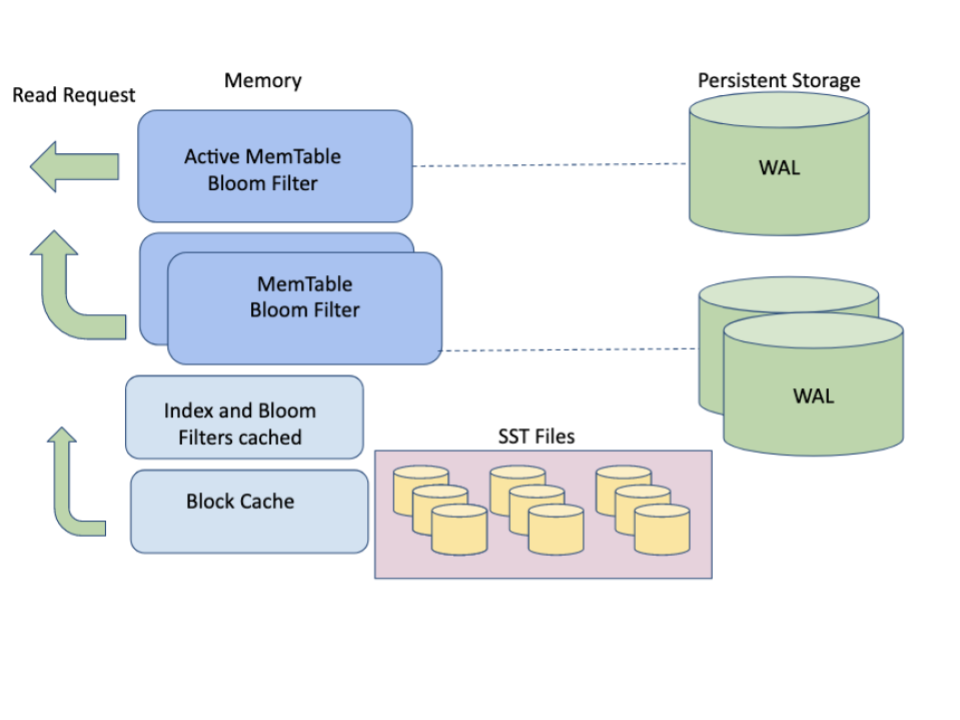
So far we’ve only been talking about writing the data. Reading it is also quite different in MyRocks due to its structure. Since the data is leveled, to find a value for a key, you need to look at memtables, L0, L1 … L6. This is an LSM read penalty. However, you don’t always have to scan the whole dataset to find the row, and not all scans go to disk. The read path starts in memtables, which will by definition have the most recent data. Then the block cache will be used, which might contain the recently-accessed data.
Once in-memory options are exhausted, reads will spill to disk and start traversing SSTs on consecutive levels. L0 has to be scanned whole since data in SSTs overlaps, but only a subset of SSTs on other levels has to be scanned, as we know key ranges of data inside each SST. To further improve this scanning, bloom filters are utilized, which helps the scan operation answer a question: “is key present in given SST?” – but only if we are sure it’s not present. Thus, we can avoid reading some SSTs, whose key range covers the key we look for. Unfortunately, for now, there’s no BF-like technique for range scans, though prefix bloom filters might help.
Each time we find the data we’re looking for, we populate the block cache for future use. In addition to that, index and bloom filter data is also cached, thus speeding up the SST scans even if the data is not in block cache. Even with all of these improvements, you can see that in general, the reads are more involved than they are in regular b-tree storage engines. The negative effects, however, become less pronounced the more data there’s in the data set.
Production readiness of a solution is defined not only by its own maturity but also by the ecosystem around it. Let’s review how MyRocks fits with existing tools and regular maintenance activities.
First and foremost, can we back it up online with minimal locking as we can innodb? The answer is yes (with some catches). Original Facebook’s MySQL 5.6 includes myrocks_hotbackup script, which enables hot backups of MyRocks, but no other engines. Starting with Percona XtraBackup version 8.0.6 and Mariabackup 10.2.16/10.3.8, we have the ability to use a single tool to back up heterogeneous clusters.
One of the significant MyRocks limitations is that it doesn’t support online DDL as InnoDB does. You can use solutions like pt-online-schema-change and gh-ost, which are preferred anyway when doing large table changes. For pt-osc, there are some details to note. Global transaction isolation should be set to Read Committed, or pt-osc will fail when a target table is already in RocksDB engine. It also needs binlog_format to be set to ROW. Both of these settings are usually advisable for MyRocks anyway, as it doesn’t support gap locking yet, and so its repeatable read implementation differs.
Because we’re limited to ROW-level replication, tools like pt-table-checksum and pt-table-sync will not work, so be careful with the data consistency.
Monitoring is another important consideration for production use. MyRocks is quite well-instrumented internally, providing more than a hundred metrics, extensive show engine output, and verbose logging. Here’s an overview of some of the available metrics: MyRocks Information Schema. With Percona Monitoring and Management, you get a dedicated dashboard for MyRocks, providing an overview of the internals of the engine.
Partitioning in MyRocks is supported and has an interesting feature where you can assign partitions to different column families: Column Families on Partitioned Tables.
Unfortunately, for now, encryption does not work with MyRocks, even though RocksDB supports pluggable encryption.
We have compiled a basic load test on MyRocks vs InnoDB with the following details.
We downloaded Ontime Performance Data Reporting for the year 2019 and loaded it to both engines. The test consisted of loading to a single table data for one year worth of information (about 14million rows). Load scripts can be found at github repo.
AWS Instance : t2.large – 8Gb Ram – 16Gb SSD
| Engine | Size | Duration | Rows | Method |
| innodb + log_bin off | 5.6Gb | 9m56 | 14,009,743 | Load Infile |
| innodb + log_bin on | 5.6Gb ** | 11m58 | 14,009,743 | Load Infile |
| innodb compressed + log_bin on | 2.6Gb ** | 17m9 | 14,009,743 | Load Infile |
| innodb compressed + log_bin off | 2.6Gb | 15m56 | 14,009,743 | Load Infile |
| myrocks/lz4 + log_bin on | 1.4G* | 9m24 | 14,009,743 | Load Infile |
| myrocks/lz4 + log_bin off | 1.4G* | 8m2 | 14,009,743 | Load Infile |
* MyRocks WAL files aren’t included (This is a configurable parameter)
**InnoDB Redo logs aren’t included
As we’ve shown above, MyRocks can be a surprisingly versatile choice of the storage engine. While usually it’s sold on space efficiency and write load, benchmarks show that it’s quite good in TPC-C workload. So when would you use MyRocks?
In the simplest terms:
This best translates to servers with expensive storage (SSDs), and to the cloud, where these could be significant price points.
But real databases rarely consist of pure log data. We do selects, be it point lookups or range queries, we modify the data. As it happens, if you can sacrifice some database-side constraints, MyRocks can be surprisingly good as a general-purpose storage engine, more so the larger the data set you have. Give it a try, and let us know.
Limitations to consider before moving forward:
Warnings:
It’s designed for small transactions, so configure for bulk operations. For loading data, use rocksdb_bulk_load=1, and for deleting large data sets use rocksdb-commit-in-the-middle.
Mixing different storage engines in one transaction will work, but be aware of the differences of how isolation levels work between InnoDB and RocksDB engines, and limitations like the lack of Savepoints. Another important thing to note when mixing storage engines is that they use different memory structures, so plan carefully.
Corrupted immutable files are not recoverable.
Exposing MyRocks Internals Via System Variables: Part 1, Data Writing
Webinar: How to Rock with MyRocks





Were you folks able to get prefix bloom filters working in MyRocks 8.0? I could not. I filed https://jira.percona.com/browse/PS-7137. Not sure if there is any issue with my config.
Were you able to get prefix bloom filter working in MyRocks 8.0? I could not, and filed https://jira.percona.com/browse/PS-7137.