
If you do a quick web search about UUIDs and MySQL, you’ll get a fair number of results. Here are just a few examples:
So, does a well-covered topic like this one needs any more attention? Well, apparently – yes. Even though most posts are warning people against the use of UUIDs, they are still very popular. This popularity comes from the fact that these values can easily be generated by remote devices, with a very low probability of collision. With this post, my goal is to summarize what has already been written by others and, hopefully, bring in a few new ideas.
If you need more high availability in your MySQL database, check out Percona XtraDB Cluster (PXC)
UUID stands for Universally Unique IDentifier and is defined in the RFC 4122. It is a 128 bits number, normally written in hexadecimal and split by dashes into five groups. A typical UUID value looks like:
|
1 2 |
yves@laptop:~$ uuidgen 83fda883-86d9-4913-9729-91f20973fa52 |
There are officially 5 types of UUID values, version 1 to 5, but the most common are: time-based (version 1 or version 2) and purely random (version 3). The time-based UUIDs encode the number of 10ns since January 1st, 1970 in 7.5 bytes (60 bits), which is split in a “time-low”-“time-mid”-“time-hi” fashion. The missing 4 bits is the version number used as a prefix to the time-hi field. This yields the 64 bits of the first 3 groups. The last 2 groups are the clock sequence, a value incremented every time the clock is modified and a host unique identifier. Most of the time, the MAC address of the main network interface of the host is used as a unique identifier.
There are important points to consider when you use time-based UUID values:
Here’s an example using the “uuidgen” Unix tool to generate time-based values:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
yves@laptop:~$ for i in $(seq 1 500); do echo "$(date +%s): $(uuidgen -t)"; sleep 1; done 1573656803: 572e4122-0625-11ea-9f44-8c16456798f1 1573656804: 57c8019a-0625-11ea-9f44-8c16456798f1 1573656805: 586202b8-0625-11ea-9f44-8c16456798f1 ... 1573657085: ff86e090-0625-11ea-9f44-8c16456798f1 1573657086: 0020a216-0626-11ea-9f44-8c16456798f1 ... 1573657232: 56b943b2-0626-11ea-9f44-8c16456798f1 1573657233: 57534782-0626-11ea-9f44-8c16456798f1 1573657234: 57ed593a-0626-11ea-9f44-8c16456798f1 ... |
The first field rolls over (at t=1573657086) and the second field is incremented. It takes about 429s to see similar values again for the first field. The third field changes only once per about a year. The last field is static on a given host, the MAC address is used on my laptop:
|
1 2 |
yves@laptop:~$ ifconfig | grep ether | grep 8c ether 8c:16:45:67:98:f1 txqueuelen 1000 (Ethernet) |
The other frequently seen UUID version is 4, the purely random one. By default, the Unix “uuidgen” tool produces UUID version 4 values:
|
1 2 3 4 |
yves@laptop:~$ for i in $(seq 1 3); do uuidgen; done 6102ef39-c3f4-4977-80d4-742d15eefe66 14d6e343-028d-48a3-9ec6-77f1b703dc8f ac9c7139-34a1-48cf-86cf-a2c823689a91 |
The only “repeated” value is the version, “4”, at the beginning of the 3rd field. All the other 124 bits are random.
In order to appreciate the impact of using UUID values as a primary key, it is important to review how InnoDB organizes the data. InnoDB stores the rows of a table in the b-tree of the primary key. In database terminology, we call this a clustered index. The clustered index orders the rows automatically by the primary key.
When you insert a new row with a random primary key value, InnoDB has to find the page where the row belongs, load it in the buffer pool if it is not already there, insert the row and then, eventually, flush the page back to disk. With purely random values and large tables, all b-tree leaf pages are susceptible to receive the new row, there are no hot pages. Rows inserted out of the primary key order cause page splits causing a low filling factor. For tables much larger than the buffer pool, an insert will very likely need to read a table page from disk. The page in the buffer pool where the new row has been inserted will then be dirty. The odds the page will receive a second row before it needs to be flushed to disk are very low. Most of the time, every insert will cause two IOPs – one read and one write. The first major impact is on the rate of IOPs and it is a major limiting factor for scalability.
The only way to get decent performance is thus to use storage with low latency and high endurance. That’s where you’ll the second major performance impact. With a clustered index, the secondary indexes use the primary key values as the pointers. While the leaves of the b-tree of the primary key store rows, the leaves of the b-tree of a secondary index store primary key values.
Let’s assume a table of 1B rows having UUID values as primary key and five secondary indexes. If you read the previous paragraph, you know the primary key values are stored six times for each row. That means a total of 6B char(36) values representing 216 GB. That is just the tip of the iceberg, as tables normally have foreign keys, explicit or not, pointing to other tables. When the schema is based on UUID values, all these columns and indexes supporting them are char(36). I recently analyzed a UUID based schema and found that about 70 percent of storage was for these values.
As if that’s not enough, there’s a third important impact of using UUID values. Integer values are compared up to 8 bytes at a time by the CPU but UUID values are compared char per char. Databases are rarely CPU bound, but nevertheless this adds to the latencies of the queries. If you are not convinced, look at this performance comparison between integers vs strings:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> select benchmark(100000000,2=3); +--------------------------+ | benchmark(100000000,2=3) | +--------------------------+ | 0 | +--------------------------+ 1 row in set (0.96 sec) mysql> select benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='df878007-80da-11e9-93dd-00163e000003'); +----------------------------------------------------------------------------------------------------+ | benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='df878007-80da-11e9-93dd-00163e000003') | +----------------------------------------------------------------------------------------------------+ | 0 | +----------------------------------------------------------------------------------------------------+ 1 row in set (27.67 sec) |
Of course, the above example is a worst-case scenario but it at least gives the span of the issue. Comparing integers is about 28 times faster. Even if the difference appears rapidly in the char values, it is still about 2.5 times slower:
|
1 2 3 4 5 6 7 |
mysql> select benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='ef878007-80da-11e9-93dd-00163e000003'); +----------------------------------------------------------------------------------------------------+ | benchmark(100000000,'df878007-80da-11e9-93dd-00163e000002'='ef878007-80da-11e9-93dd-00163e000003') | +----------------------------------------------------------------------------------------------------+ | 0 | +----------------------------------------------------------------------------------------------------+ 1 row in set (2.45 sec) |
Let’s explore a few solutions to address those issues.
The default representation for UUID, hash, and token values is often the hexadecimal notation. With a cardinality, the number of possible values, of only 16 per byte, it is far from efficient. What about using another representation like base64 or even straight binary? How much do we save? How is the performance affected?
Let’s begin by the base64 notation. The cardinality of each byte is 64 so it takes 3 bytes in base64 to represent 2 bytes of actual value. A UUID value consists of 16 bytes of data, if we divide by 3, there is a remainder of 1. To handle that, the base64 encoding adds ‘=’ at the end:
|
1 2 3 4 5 6 7 |
mysql> select to_base64(unhex(replace(uuid(),'-',''))); +------------------------------------------+ | to_base64(unhex(replace(uuid(),'-',''))) | +------------------------------------------+ | clJ4xvczEeml1FJUAJ7+Fg== | +------------------------------------------+ 1 row in set (0.00 sec) |
If the length of the encoded entity is known, like for a UUID, we can remove the ‘==’, as it is just dead weight. A UUID encoded in base64 thus has a length of 22.
The next logical step is to directly store the value in binary format. This the most optimal format but displaying the values in the mysql client is less convenient.
So, how’s the size impacting performance? To illustrate the impact, I inserted random UUID values in a table with the following definition…
|
1 2 3 4 |
CREATE TABLE `data_uuid` ( `id` char(36) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; |
… for the default hexadecimal representation. For base64, the ‘id’ column is defined as char(22) while binary(16) is used for the binary example. The database server has a buffer pool size at 128M and its IOPs are limited to 500. The insertions are done over a single thread.
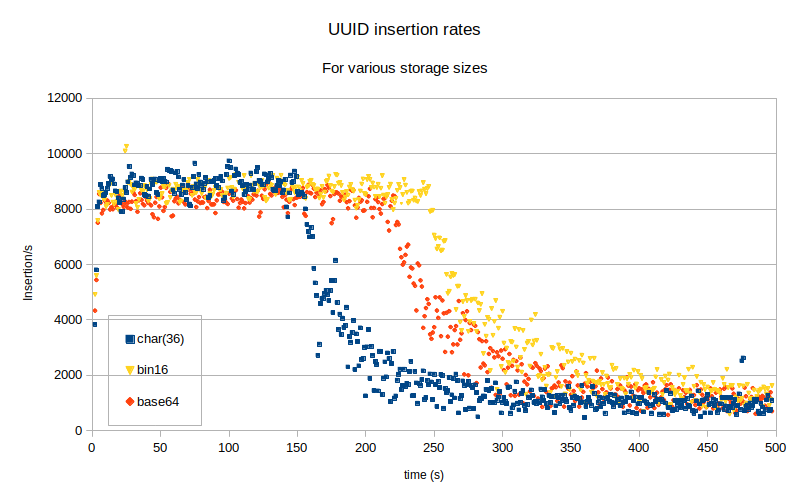
In all cases, the insertion rate is at first CPU bound but as soon the table is larger than the buffer pool, the insertion rapidly becomes IO bound. This is expected and shouldn’t surprise anyone. The use of a smaller representation for the UUID values just allows more rows to fit in the buffer pool but in the long run, it doesn’t really help the performance, as the random insertion order dominates. If you are using random UUID values as primary keys, your performance is limited by the amount of memory you can afford.
As we have seen, the most important issue is the random nature of the values. A new row may end up in any of the table leaf pages. So unless the whole table is loaded in the buffer pool, it means a read IOP and eventually a write IOP. My colleague David Ducos gave a nice solution to this problem but some customers do not want to allow for the possibility of extracting information from the UUID values, like, for example, the generation timestamp.
What if we somewhat just reduce then the randomness of the values in a way that a prefix of a few bytes is constant for a time interval? During the time interval, only a fraction of the whole table, corresponding to the cardinality of the prefix, would be required to be in the memory to save the read IOPs. This would also increase the likelihood a page receives a second write before being flushed to disk, thus reducing the write load. Let’s consider the following UUID generation function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
drop function if exists f_new_uuid; delimiter ;; CREATE DEFINER=`root`@`%` FUNCTION `f_new_uuid`() RETURNS char(36) NOT DETERMINISTIC BEGIN DECLARE cNewUUID char(36); DECLARE cMd5Val char(32); set cMd5Val = md5(concat(rand(),now(6))); set cNewUUID = concat(left(md5(concat(year(now()),week(now()))),4),left(cMd5Val,4),'-', mid(cMd5Val,5,4),'-4',mid(cMd5Val,9,3),'-',mid(cMd5Val,13,4),'-',mid(cMd5Val,17,12)); RETURN cNewUUID; END;; delimiter ; |
The first four characters of the UUID value comes from the MD5 hash of the concatenation of the current year and week number. This value is, of course, static over a week. The remaining of the UUID value comes from the MD5 of a random value and the current time at a precision of 1us. The third field is prefixed with a “4” to indicate it is a version 4 UUID type. There are 65536 possible prefixes so, during a week, only 1/65536 of the table rows are required in the memory to avoid a read IOP upon insertion. That’s much easier to manage, a 1TB table will need to have only about 16MB in the buffer pool to support the inserts.
Even if you use pseudo-ordered UUID values stored using binary(16), it is still a very large data type which will inflate the size of the dataset. Remember the primary key values are used as pointers in the secondary indexes by InnoDB. What if we store all the UUID values of a schema in a mapping table? The mapping table will be defined as:
|
1 2 3 4 5 6 7 |
CREATE TABLE `uuid_to_id` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `uuid` char(36) NOT NULL, `uuid_hash` int(10) unsigned GENERATED ALWAYS AS (crc32(`uuid`)) STORED NOT NULL, PRIMARY KEY (`id`), KEY `idx_hash` (`uuid_hash`) ) ENGINE=InnoDB AUTO_INCREMENT=2590857 DEFAULT CHARSET=latin1; |
It is important to notice the uuid_to_id table does not enforce the uniqueness of uuid. The idx_hash index acts a bit like a bloom filter. We’ll know for sure a UUID value is not present in the table when there is no matching hash value but we’ll have to validate with the stored UUID value when there is a matching hash. To help us here, let’s create a SQL function:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
DELIMITER ;; CREATE DEFINER=`root`@`%` FUNCTION `f_uuid_to_id`(pUUID char(36)) RETURNS int(10) unsigned DETERMINISTIC BEGIN DECLARE iID int unsigned; DECLARE iOUT int unsigned; select get_lock('uuid_lock',10) INTO iOUT; SELECT id INTO iID FROM uuid_to_id WHERE uuid_hash = crc32(pUUID) and uuid = pUUID; IF iID IS NOT NULL THEN select release_lock('uuid_lock') INTO iOUT; SIGNAL SQLSTATE '23000' SET MESSAGE_TEXT = 'Duplicate entry', MYSQL_ERRNO = 1062; ELSE insert into uuid_to_id (uuid) values (pUUID); select release_lock('uuid_lock') INTO iOUT; set iID = last_insert_id(); END IF; RETURN iID; END ;; DELIMITER ; |
The function checks if the UUID values passed exist in the uuid_to_id table, and if it does it returns the matching id value otherwise it inserts the UUID value and returns the last_insert_id. To protect against the concurrent submission of the same UUID values, I added a database lock. The database lock limits the scalability of the solution. If your application cannot submit twice the request over a very short time frame, the lock could be removed. I have also another version of the function with no lock calls and using a small dedup table where recent rows are kept for only a few seconds. See my github if you are interested.
Now, let’s have a look at the insertion rates using these alternate approaches.
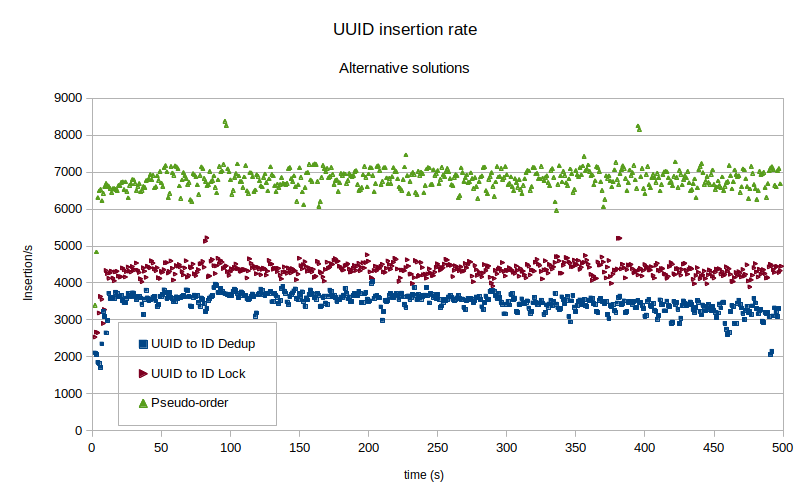
The pseudo-order results are great. Here I modified the algorithm to keep the UUID prefix constant for one minute instead of one week in order to better fit the test environment. Even if the pseudo-order solution performs well, keep in mind it is still bloating the schema and overall the performance gains may not be that great.
The mapping to integer values, although the insert rates are smaller due to the additional DMLs required, decouples the schema from the UUID values. The tables now use integers as primary keys. This mapping removes nearly all the scalability concerns of using UUID values. Still, even on a small VM with limited CPU and IOPS, the UUID mapping technique yields nearly 4000 inserts/s. Put into context, this means 14M rows per hour, 345M rows per day and 126B rows per year. Such rates likely fit most requirements. The only growth limitation factor is the size of the hash index. When the hash index will be too large to fit in the buffer pool, performance will start to decrease.
Of course, there are other possibilities to generate unique IDs. The method used by the MySQL function UUID_SHORT() is interesting. A remote device like a smartphone could use the UTC time instead of the server uptime. Here’s a proposal:
|
1 2 3 |
(Seconds since January 1st 1970) << 32 + (lower 2 bytes of the wifi MAC address) << 16 + 16_bits_unsigned_int++; |
The 16 bits counter should be initialized at a random value and allowed to roll over. The odds of two devices producing the same ID are very small. It has to happen at approximately the same time, both devices must have the same lower bytes for the MAC and their 16 bits counter at the same increment.
All the data related to this post can be found in my github.





Note that in MySQL 8.0, the function UUID_TO_BIN can be used to encode a UUID into a BINARY(16) value. This function may also rearrange the parts of the UUID so that you will get monotonically increasing values. This should avoid the insert performance issues you discuss.
Does using autoincrement numeric value as id (primary key) and an uuid column (unique key) on the same table have the same issues?
It is not as bad but you may end up in a situation where the primary key is not optimal. At least try not to store in hex.
Indeed, the 8.0 uuid_to_bin function with the swap_flag at 1 is a good alternative, at least for the ordering impact.
Unrelated to the article, but is the source code viewer that you used on this article an open source project?
We use: https://wordpress.org/plugins/crayon-syntax-highlighter/
https://www.2ndquadrant.com/en/blog/sequential-uuid-generators/ explains a solution in PostgreSQL for using UUID as Pramary Key
ULIDs are lexicographically sortable and may be generated client-side. https://github.com/ulid/spec Since they’re just 128bit numbers, you can easily insert them into UUID columns. I think they’re an excellent alternative to RFC 4122 UUIDs, especially as database identifiers
Which version of MySql was used for this benchmarks? If it 5 are there any benchmark for Version 8?
I used 5.7, I have no plan for similar benchmarks on 8.0.x and I don’t expect a significant difference.
Great article Yves – appreciate the work you put into it.
Thanks for the great research! Now popularity of the
cuid(https://github.com/ericelliott/cuid) format, which declares benefits above UUID in binary search, is growing! Can you please make a short comparison with it too?How about secondary indexes with UUID?