
 We discussed one of the traditional ways to configure HAProxy with PostgreSQL in our previous blog about HAProxy using Xinetd. There we briefly mentioned the limitation of the HAProxy’s built-in pgsql-check health check option. It lacks features to detect and differentiate the Primary and Hot-Standby. It tries to establish a connection to the database instance and if the connection request is progressing, it will be considered as a successful check and there is no provision to check the current role (Primary or Standby).
We discussed one of the traditional ways to configure HAProxy with PostgreSQL in our previous blog about HAProxy using Xinetd. There we briefly mentioned the limitation of the HAProxy’s built-in pgsql-check health check option. It lacks features to detect and differentiate the Primary and Hot-Standby. It tries to establish a connection to the database instance and if the connection request is progressing, it will be considered as a successful check and there is no provision to check the current role (Primary or Standby).
So the question remains:
This blog post discusses what is possible using pgsql-check and how to achieve that.
Note: This blog demonstrates the concept. Integration with specific HA framework/script is left to users because there are a large number of HA solutions for PostgreSQL and these concepts are equally applicable for them
When a client initiates the connection to PostgreSQL, the first stage of a check is whether it is acceptable as per rules specified in pg_hba.conf. That stage needs to be completed before proceeding to the next stage of specific authentication mechanisms.
The pgsql-check is designed to check this first stage (pg_hba.conf) and return success if it is passed because a positive response from the server can be considered as a litmus test for whether the instance is up and capable of accepting connections. It doesn’t have to complete the authentication. pgsql-check abandons the connection after this check before completing the initial handshakes and PostgreSQL terminates it.
A connection request will be straight away rejected if pg_hba.conf rule says to “reject” it. For example, a pg_hba.conf entry like
|
1 |
host postgres pmm_user 192.168.80.20/32 reject |
tells PostgreSQL to reject connection from IP 192.168.80.20 as pmm_user to postgres database.
We can use this logic of modifying the pg_hba.conf entries as part of the failover/switchover procedure. Such automation is easily achievable by a callback script if you are using any kind of automation for failover or switchover. Alternatively, we can have a small script that checks the database instance status in each node and maintains the pg_hbha.conf entry accordingly.
In a nutshell, routing tables in HAProxy can get automatically modified and connections will be routed according to pg_hba.conf entries which are maintained as part of HA scripts/solution OR switchover/failover procedure.
I have one primary and two hot-standby servers with server nodes (pg0, pg1, pg2) and an application server (app). We shall create two users; one for the Primary connection (read-write) detection and another for standby (read-only) connection detection.
|
1 2 3 4 |
postgres=# create user primaryuser with password 'primaryuser'; CREATE ROLE postgres=# create user standbyuser with password 'standbyuser'; CREATE ROLE |
Now we need to have pg_hba.conf entry such a way that connection request to this user will be taken forward for authentication.
|
1 2 |
host primaryuser primaryuser 192.168.50.0/24 md5 host standbyuser standbyuser 192.168.50.0/24 md5 |
Please see that the username and database names are kept as same. because the default name of the database is the same as user. This will help with the straightaway rejection of connection which is what we want rather than later reporting that database "xyz" does not exist. We should keep in mind that there are NO such databases that exist in this PostgreSQL cluster with the name “primaryuser” or “standbyuser”. So this user won’t be really able to connect to any database even if we are not rejecting it. This is an added security to the whole setup.
We should reload the configuration:
|
1 2 3 4 5 |
postgres=# select pg_reload_conf(); pg_reload_conf ---------------- t (1 row) |
It is a good idea to verify the client connection from the application server to this user.
|
1 2 3 |
$ psql -h pg0 -U primaryuser Password for user primaryuser: psql: FATAL: database "primaryuser" does not exist |
Here we can see that connection request is taken forward for authentication, so it prompts for the password but the connection will be rejected finally because there is no such database as “primaryuser”. This is sufficient for HAProxy configuration.
We need to have the same setup for all the nodes of the PostgreSQL cluster because any node can be promoted to primary or demoted to standby.

We are going to have two ports open in haproxy for connection.
Here is the sample haproxy configuration (/etc/haproxy/haproxy.cfg) I used in the demonstration setup
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
global maxconn 100 defaults log global mode tcp retries 2 timeout client 30m timeout connect 4s timeout server 30m timeout check 5s listen stats mode http bind *:7000 stats enable stats uri / listen pgReadWrite bind *:5000 option pgsql-check user primaryuser default-server inter 3s fall 3 server pg0 pg0:5432 check port 5432 server pg1 pg1:5432 check port 5432 server pg2 pg2:5432 check port 5432 listen pgReadOnly bind *:5001 option pgsql-check user standbyuser default-server inter 3s fall 3 server pg0 pg0:5432 check port 5432 server pg1 pg1:5432 check port 5432 server pg2 pg2:5432 check port 5432 |
Note: haproxy installation and default configuration file location might change based on OS. On Redhat clones, installation is generally as simple as running: $ sudo yum install haproxy
As we can see in the configuration, the check is using option pgsql-check with user primaryuser for “pgReadWrite” connections and standbyuser for “pgReadOnly” connections which are intended for Primary and Standby connections respectively. All three nodes of the cluster are candidates for all the types of connections.
Once we have the configuration ready, the haproxy service can be started up.
|
1 |
$ sudo systemctl start haproxy |
At this stage, all nodes will be listed as candidates for both read-write and read-only connections which will be marked in the green background color.
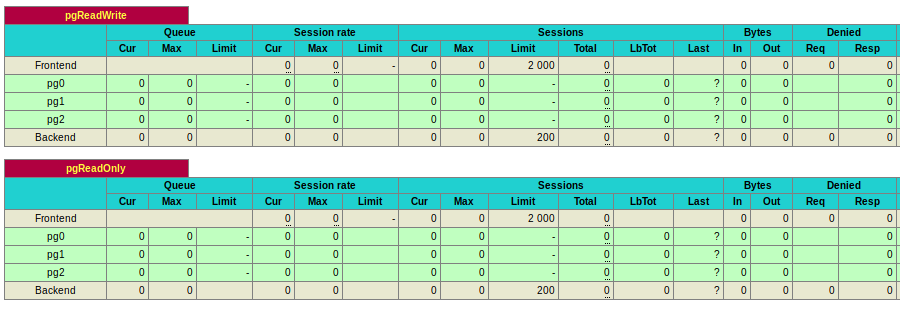
This is not what we want to achieve.
All HA solutions for failover/switchover have the provision for housekeeping which updates configuration files like recovery.conf and capability for callback custom scripts. It is the responsibility of the same failover/switchover procedure to make changes to pg_hba.conf in this case. The change should be such a way that the pg_hba.conf setting should reject the standbyuser connection on the primary node and primaryuser connection from standby servers. For this demonstration, I am directly modifying the authentication method “reject”.
On Primary:
|
1 |
$ sed -i 's/(hosts*standbyusers*standbyuser.*) md5/1 reject/g' $PGDATApg_hba.conf |
So that the line will change to:
|
1 |
host standbyuser standbyuser 192.168.50.0/24 reject |
On Standby:
|
1 |
$ sed -i 's/(hosts*primaryusers*primaryuser.*) md5/1 reject/g' $PGDATApg_hba.conf |
So that the line will change to:
|
1 |
host primaryuser primaryuser 192.168.50.0/24 reject |
After reloading the configuration, the routing tables will get updated with the right set of information
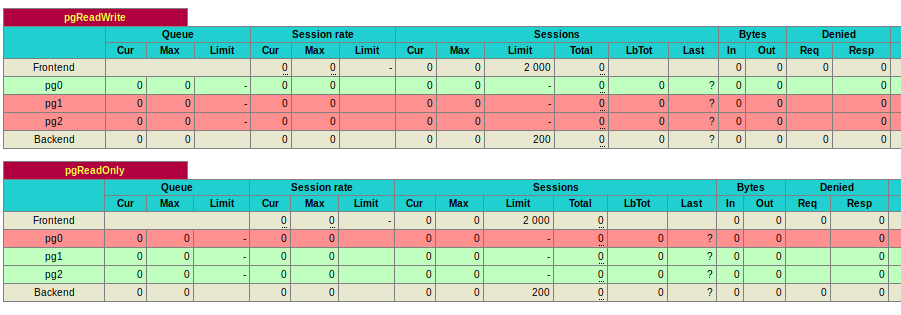
This is what we need to have.
Testing of this HAProxy setup can be done from the machine (app) where HAProxy is currently configured.
Connections to port 5000 will be routed to Primary:
|
1 2 3 4 5 6 |
$ psql -h localhost -U postgres -p 5000 -c "select pg_is_in_recovery()" Password for user postgres: pg_is_in_recovery ------------------- f (1 row) |
Connection to port 5001 will be routed to one of the standby:
|
1 2 3 4 5 6 |
$ psql -h localhost -U postgres -p 5001 -c "select pg_is_in_recovery()" Password for user postgres: pg_is_in_recovery ------------------- t (1 row) |
So with the help of a custom callback script which modifies the pg_hba.conf, HAProxy can maintain its routing table and thereby redirect the connections.
The advantage of built-in pgsql-check is obvious in that we don’t need any extra components and setup is very straight-forward.
On the disadvantage side, the modification of pg_hba.conf is the key and we should make sure that it is getting updated as part of failover and switchover.
As we described in the concept, pgsql-check is designed to abandon the connections after the check which PostgreSQL will be logging as:
|
1 |
LOG: could not receive data from client: Connection reset by peer |
Moreover, all the connection requests are rejected at the pg_bha.conf rule will be logged as well:
|
1 |
FATAL: pg_hba.conf rejects connection for host "192.168.50.40", user "primaryuser", database "primaryuser", SSL off |
PostgreSQL log file will be containing a lot of such messages which you can ignore, but it will be nice if you are expecting the log files to be clean.
Special Note:- There are some recent improvements to HAProxy like this commit which improves the disconnection of pgsql-check. So messages like LOG: could not receive data from client: Connection reset by peer may not appear in the logs. This is tested and confirmed with HAProxy Version 2.0.8. However, at the time of writing this blog, it is not available in most of the repositories and you may have to build it from source code.
You’ve chosen PostgreSQL for its flexibility, performance, and cost savings—but even experienced IT leaders can hit avoidable pitfalls along the way. Here’s what to look out for.





Thanks for the article! What solution would you suggest for routing r/o and r/w queries.
Individual statement routing is NOT something I would recommended. because each packet in the routing server need to be analyzed which slows down the routing. It becomes very complicated when there are statements which are part of long running transactions and Many things in application start breaking if the physical standby gets delayed.
Instead, Oracle like approach is preferred :- Connection routing, where application module decides whether it needs a read-only or read-write connection. HAProxy setup discussed in these blogs helps in Layer 4 routing which is of least overhead and a stable well proven methodology.
You can implement the check inside haproxy itself simulating psql protocol, using . No need to maintain the hba.conf. I wrote this check and shared it here https://github.com/gplv2/haproxy-postgresql
Yes Glen, I already saw your repo sometime back. That method is there in my plan as one of the next blog post item in the series. Thank you for your feedback.
Oh Cool, didn’t expect the exposure .. I had to make it myself at the time since it didn’t exist afaik. It’s working really great for a good year now on the busiest database (city of Brussels) and a few other clusters less busy. we have elaborated on the configuration as well doing the inverse, e.g balancing slave queries as well, playing with backup servers (as in haproxy backup parameter). So we have standby slaves that take over when the primary slave doesn’t work anymore. (which serves some read-only requests). Working fine. The only thing I think would be worth some thinking about is this setting :
# close open sessions in case the downed server is still running but is out of sync with the master
default-server on-marked-down shutdown-sessions
As a little glitch with the check (network/failed haproxy check) will disconnect all pending connections, which could otherwise be recovered on TCP level. Good article, there is not enough out there on making true HA postgres clusters. tx