
Recently I was doing some small testing by using EC2 instances on AWS and I noticed the execution time and performance highly depend on which time of the day I am running my scripts. I was using t3.xlarge instance type as I didn’t need many CPUs and memory for my tests, but from time to time I planned to use all the resources for a short time (few minutes), and this is when I noticed the difference.
First, let’s see what AWS says about T3 instances:
T3 instances start in Unlimited mode by default, giving users the ability to sustain high CPU performance over any desired time frame while keeping cost as low as possible.
In theory, I should not have any issues or performance differences. I have also monitored the CPU credit balance and there was no correlation between the balance and the performance at all, and because these were unlimited instances the balance should not have any impact.
I have decided to start a longer sysbench test on 3 threads to see how the QPS changes over the day.
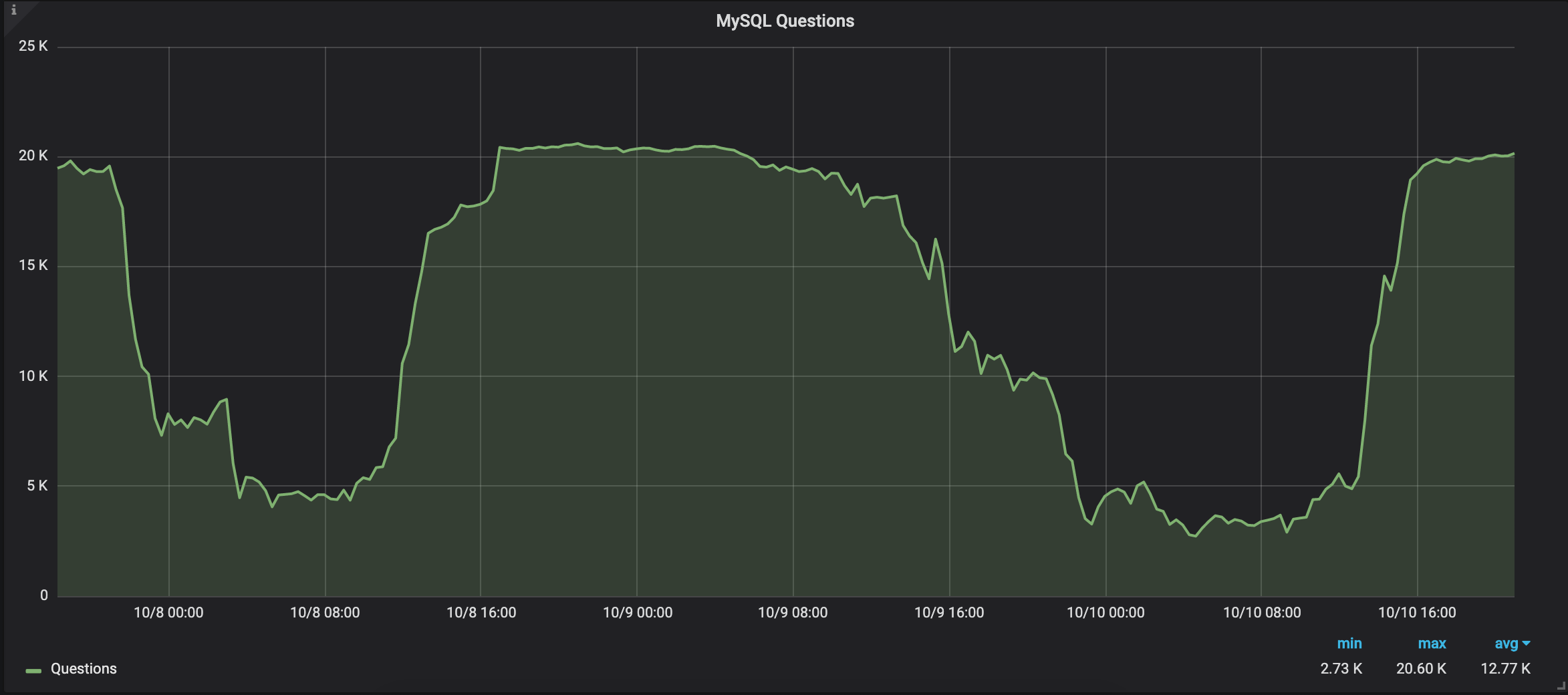
As you can see, the Query Per Second could go down by almost 90%, which is a lot. It’s important to highlightthat the sysbench script should have generated a very steady workload. So what is this big difference? After checking all the graphs I found this:
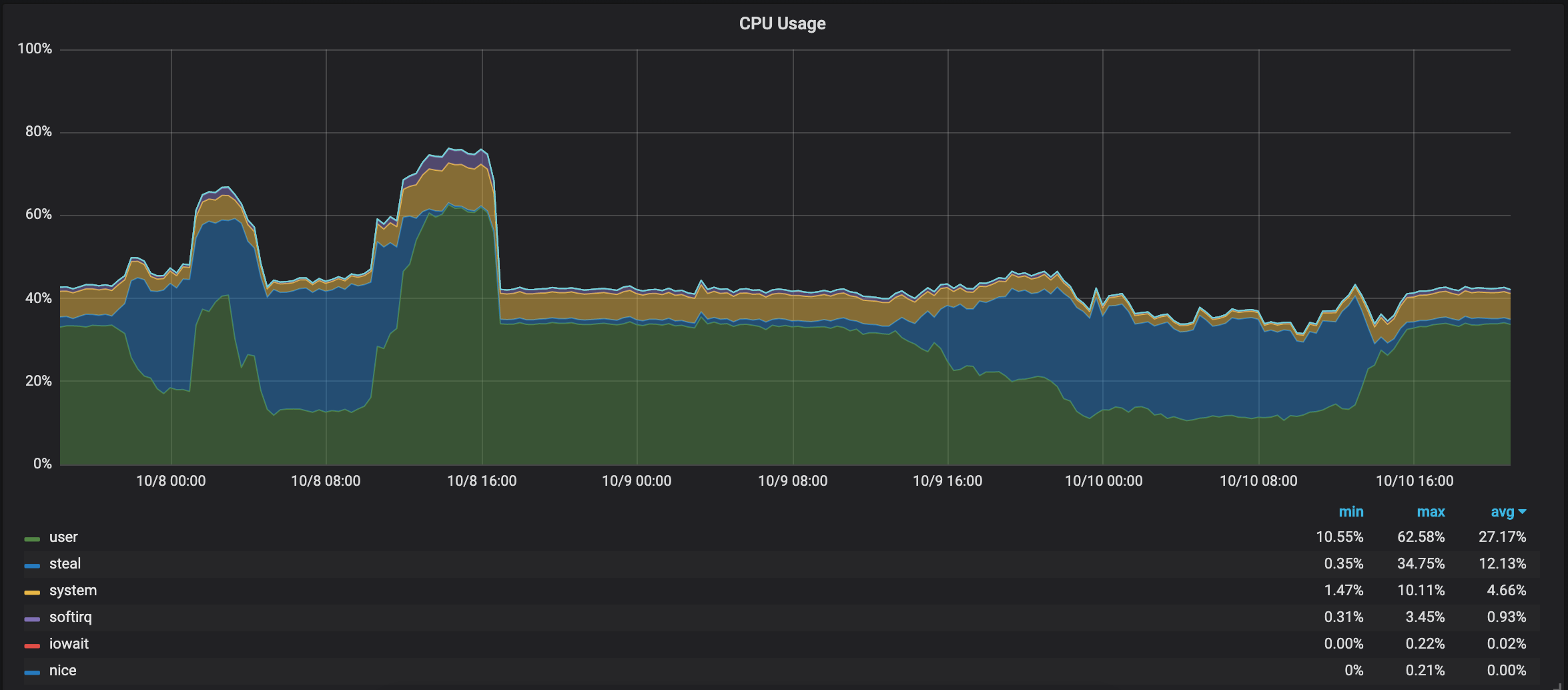
Stealing! A lot of stealing! Here is a good article which explains stealing very well. So probably, I have a noisy neighbor. This instance was running in N. California. I have stopped it and tried to start new instances to repeat the test but I have always gotten very similar results. There was a lot of stealing which was hurting the performance a lot, probably because that region is very popular and resources are limited.
Out of curiosity, I have started two similar instances in the Stockholm region and repeated the same test and I got very steady performance as you can see here:
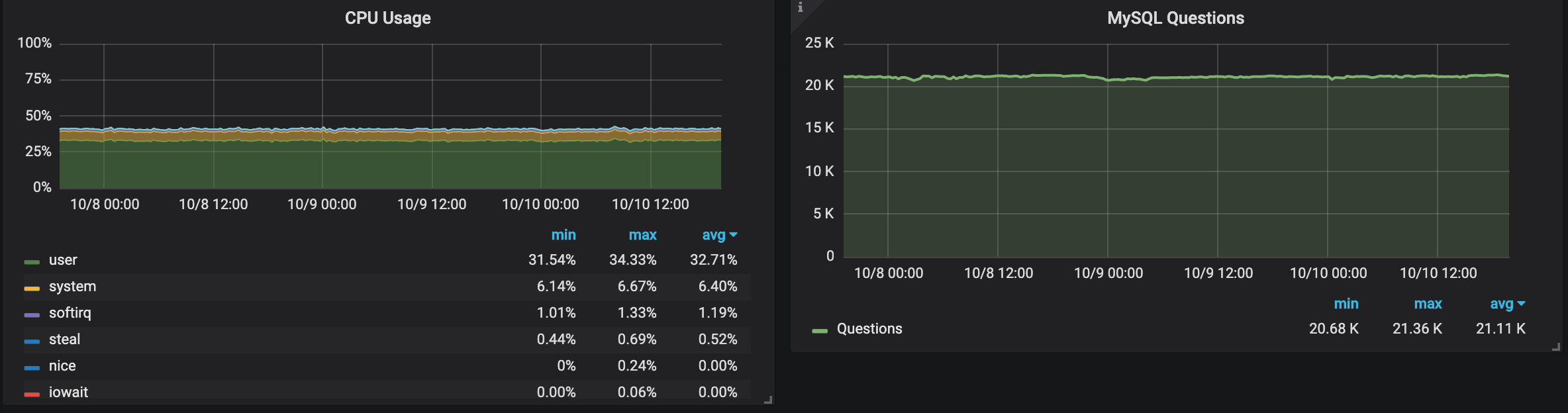
I guess this region is not that popular or filled yet, and we can see there is a huge difference between where you start your instance.
I also repeated the tests with the m5.xlarge instance type to see if it has the same behavior or not.
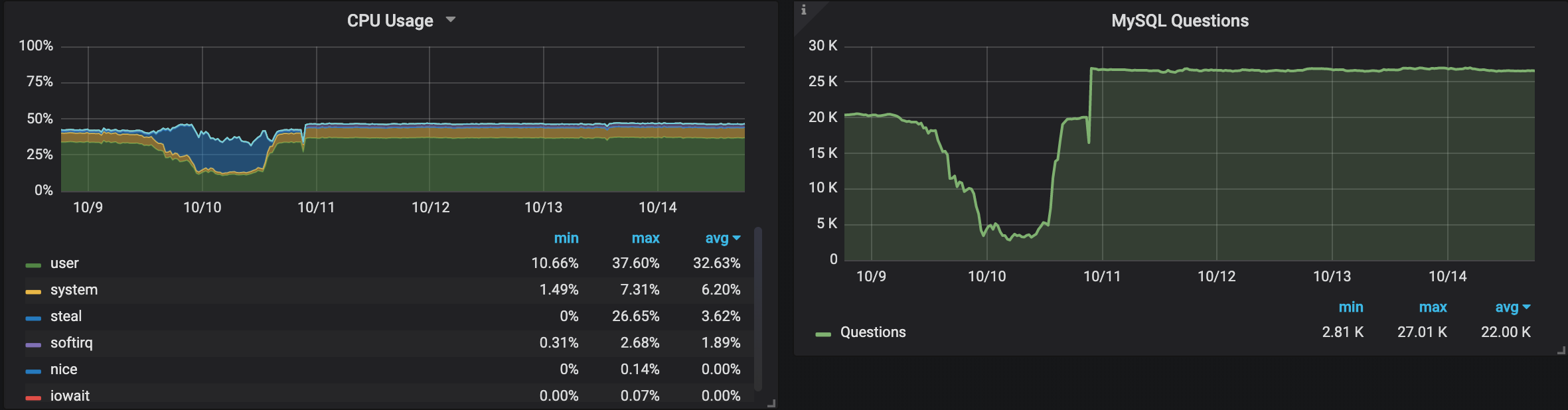
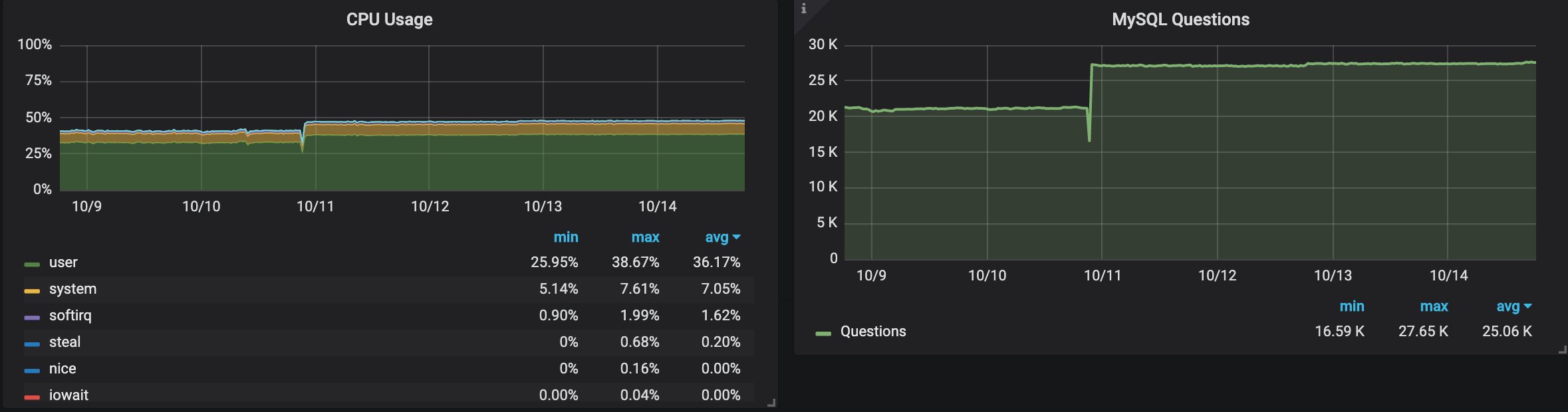
After I changed the instance type, we can see that both regions give very similar, steady performance, but if we take a closer look:
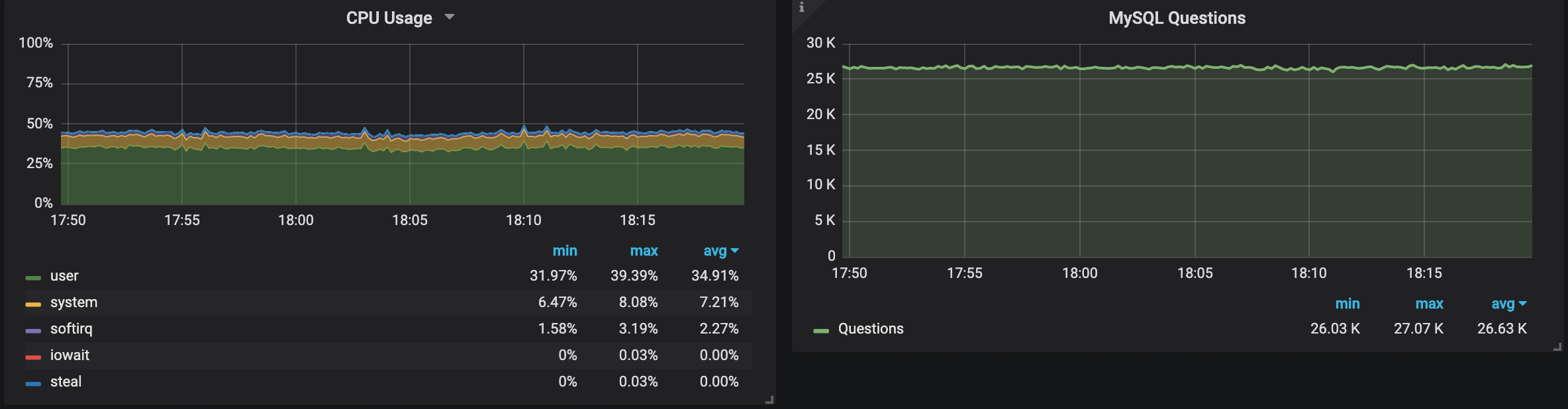
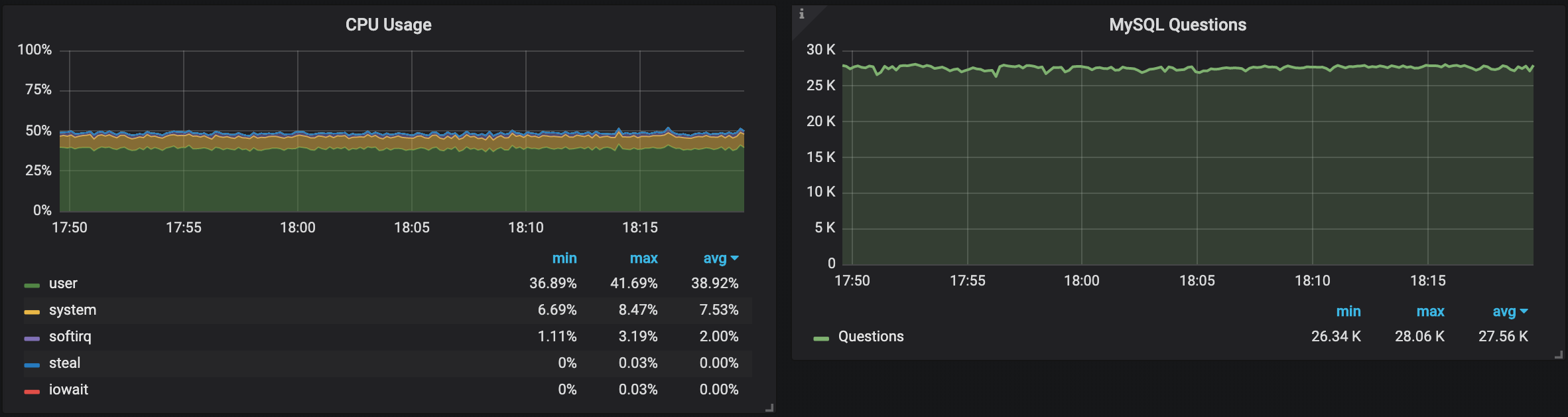
The instance in Stockholm still performs almost 5% more QPS as in N. California, and uses more CPU as well.
If you are using T2 and T3 instance types, you should monitor the CPU usage very closely because noisy neighbors can hurt your performance a lot. If you need stable performance, T2 and T3 are not recommended but if you only need a short burst it might work but still, you have to monitor the steal. Other instance types can give you a much more stable performance but you could still see some difference between the regions.
Resources
RELATED POSTS





I used to have three build nodes all on t3a.mediumv in Ireland (euwest1). I had such problems with cycle stealing they I ended up switching to low end m5a instances and my problems disappeared.
Would you mind running the tests on the new ARM instance types? I’m thinking that those would save even more money over the t types and probably won’t be oversubscribed yet.
That page actually doesn’t explain CPU steal well at all. They assume everyone has the same workload and performance class. In the real world, on a hypervisor you will most likely be mixing with differences on both of those.
CPU steal is seen where your VM is requesting more performance than what it is “paying” for. If the underlying hardware has spare capacity (either because all the slots aren’t full, or the other slots are mostly idle) then your VM can ask for more CPU (than it’s paying for) and get it.
However if everyone is using their fair share of CPU and your VM requests more, it will have to wait and the stall metric increases.
You aren’t being penalized because of your “noisy” neighbors – you are just being limited to the virtual CPU performance that you signed up for.
This is super well documented by aws themselves and if you understood how they work before creating the article then you probably would not have written it.
Please do research before writing scare articles just for clicks. That’s just lame brother.
From aws-
T2, T3, and T3a Instances
These instances provide a baseline level of CPU performance with the ability to burst to a higher level when required by your workload. An Unlimited instance can sustain high CPU performance for any period of time whenever required. For more information, see Burstable Performance Instances. These instances are well-suited for the following applications:
Websites and web applications
Code repositories
Development, build, test, and staging environments
Microservices
For more information, see Amazon EC2 T2 Instances and Amazon EC2 T3 Instances.
Burstable does not mean indefinitely – so of course your tests are showing exactly how those instances work. They are doing how they’ve been programmed. Not only that the reason you get solid performance from other instance types I’d due to the fact you are renting and paying to have those specs at all times. Burstable instances are not like that. Any person with a aws SA associate certificate will tell you this.
Hi Jeremy,
The purpose of the article is not to scare people it is just to raise a behaviour which is not clear for everyone. I specially mentioned I was using Unlimited instances in this test. You are saying as well: “An Unlimited instance can sustain high CPU performance for any period of time whenever required.”
This sentence for me and for 99% of the people would mean I can get a stable performance with T3 instance types as well. But that is not true as you can see. That’s the whole point of the post to show even with Unlimited you can have performance degradation if you have some noisy neighbours.
Jeremy, the documentation talks about the cpu credit system. Tiber is refering to a totally different problem. And with such a rude language you are embarrassing yourself.
Thanks for the nice write-up Tibor, I wonder if you always had enough CPU credits remaining as these burstable CPU instances consume from them and the performance can vary greatly if you consume all of them.
Regards,
Abbas
Yes, I was monitoring the CPU credit as well and did not have any impact on the performance. There were times wen credit went down but QPS went up and there were times when Credit went up but QPS went down… I could not find any correlation between performance and CPU credit on Unlimited instances.
I think many people, but not you obviously, have a naive view of AWS hardware provisioning. They think that if they suddenly deploy 50 EC2 instances, that Amazon will rush out and buy more servers and have them installed in order to meet instant demand.
Of course, when you think about it, Amazon rely on having fairly high levels of usage in order to maximise profits, and having idle hardware lying around just in case someone wants it is a way to lose money, hence the spot pricing scheme to make at least some money from idle hardware, they can get their hardware back for exclusive use at any time by simply bidding the price up!
Thank you for this article. We have T instances for EC2 and RDS and we are expecting some very strange performance behavior. Do you have plan to test RDS?
Hi Tibor,
I forgot to mention, another useful thing to test out would be to stop and start the EC2 instance, this should move the instance to a less busy host, just a trick that usually works.
Many thanks.
Abbas
Hi Tibor, Great post! Which monitoring solution did you use?
Thanks!
Does these sysbench tests talk to a DB server on another remote host, or is a server instance running on the host itself as part of this test? Asking to know if that extra load is also causing the baseline utilization to go up.