
 Here at Percona’s Training and Education department, we are always at work with trying to keep our materials up-to-date and relevant to current technologies. In addition, we keep an eye out for what topics are “hot” and are generating a lot of buzz. Unless you’ve been living under a rock for the past year, Kubernetes is the current buzz word/technology. This is the first post in this blog series where we will dive into Kubernetes, and explore using it with Percona XtraDB Cluster.
Here at Percona’s Training and Education department, we are always at work with trying to keep our materials up-to-date and relevant to current technologies. In addition, we keep an eye out for what topics are “hot” and are generating a lot of buzz. Unless you’ve been living under a rock for the past year, Kubernetes is the current buzz word/technology. This is the first post in this blog series where we will dive into Kubernetes, and explore using it with Percona XtraDB Cluster.
Editor Disclaimer: This post is not intended to convince you to switch to a containerized environment. This post is simply aimed to educate about a growing trend in the industry.
Let’s start at the beginning. First, there were hardware-based servers; we still have these today. Despite the prevalence of “the cloud”, many large companies still use private datacenters and run their databases and applications “the traditional way.” Stepping up from hardware we venture into virtual machine territory. Popular solutions here are VMWare (commercial product), QEMU, KVM, and Virtual Box (the latter three are OSS).
Virtual Machines (VM) abstract away the hardware on which they are running using emulation software; this is generally referred to as the hypervisor. Such a methodology allows for an entirely separate operating system (OS) to run “on top of” the OS running natively against the hardware. For example, you may have CentOS 7 running inside a VM, which in turn, is running on your Mac laptop, or you could have Windows 10 running inside a VM, which is running on your Ubuntu 18 desktop PC.
There are several nice things about using VMs in your infrastructure. One of those is the ability to move a VM from one server to another. Likewise, deploying 10 more VMs just like the first one is usually just a couple of clicks or a few commands. Another is a better utilization of hardware resources. If your servers have 8 CPU cores and 128GB of memory, running one application on that server might not fully utilize all that hardware. Instead, you could run multiple VMs on that one server, thus taking advantage of all the resources. Additionally, using a VM allows you to bundle your application, and all associated libraries, and configs into one “unit” that can be deployed and copied very easily (We’ll come back to this concept in a minute).
One of the major downsides of the VM solution is the fact that you have an entire, separate, OS running. It is a huge waste of resources to run a CentOS 7 VM on top of a CentOS 7 hardware-server. If you have 5 CentOS 7 VMs running, you have five separate linux kernels (in addition to the host kernel), five separate copies of /usr, and five separate copies of the same libraries and application code taking up precious memory. Some might say that, in this setup, 90-99% of each VM is duplicating efforts already being made by the base OS. Additionally, each VM is dealing with its own CPU context switching management. Also, what happens when one VM needs a bit more CPU than another? There exists the concept of CPU “stealing” where one VM can take CPU from another VM. Imagine if that was your critical DB that had CPU stolen!
What if you could eliminate all that duplication but still give your application the ability to be bundled and deployed across tens or hundreds of servers with just a few commands? Enter: containers.
Simply put, a container is a type of “lightweight” virtual machine without all the overhead of running an independent operating system on top of a hypervisor. A container can be as small as a single line script or as large as <insert super complicated application with lots of libraries, code, images, etc.>.
With containers, you essentially get all of the “pros” surrounding VMs with a lot less “cons,” mainly in the area of performance. A container is not an emulation, like VMs. On Linux, the kernel provides control groups (cgroups) functionality, which can limit and isolate CPU, memory, disk, and network. This action of isolation becomes the container; everything needed is ‘contained’ in one place/group. In more advanced setups, these cgroups can even limit/throttle the number of resources given to each container. With containers, there is no need for an additional OS install; no emulation, no hypervisor. Because of this, you can achieve “near bare-metal performance” while using containers.
Containers, and any applications running inside the containers, run inside their own, isolated, namespace, and thus, a container can only see its own process, disk contents, devices assigned, and granted network access.
Much like VMs, containers can be started, stopped, and copied from machine to machine, making deployment of applications across hundreds of servers quite easy.
One potential downside to containers is that they are inherently stateless. This means that if you have a running container, and make a change to its configuration or update a library, etc., that state is not saved if the container is restarted. The initial state of the launched container will be restored on restart. That said, most container implementations provide a method for supplying external storage which can hold stateful information to survive a restart or redeployment.
The concept of “containers” is generic. Many different implementations of containers exist, much like different distributions of Linux. The most popular implementation of containers in the Linux space is Docker. Docker is free, open-source software, but can also be sold with a commercial license for more advanced features. Docker is built upon one of the earlier linux container implementations, LXC.
Docker uses the concept of “images” to distribute containers. For example, you can download and install the Percona MySQL 8.0 image to your server, and from that image, create as many separate, independent containers of ‘Percona MySQL 8’ as your hardware can handle. Without getting too deep into the specifics, Docker images are the end result of multiple compressed layers which were used during the building process of this image. Herein lies another pro for Docker. If multiple images share common layers, there only needs to be one copy of that layer on any system, thus the potential for space savings can be huge.
Another nice feature of Docker containers is its built-in versioning capabilities. If you are familiar with the version control software Git, then you should know the concept of “tags” which is extremely similar to Docker tags. These tags allow you to track and specify Docker images when creating and deploying images. For example, using the same image ( percona/percona-server ), you can deploy percona/percona-server:5.7 or percona/percona-server:8.0 In this example, “5.7” and “8.0” are the tags used.
Docker also has a huge community ecosystem for sharing images. Visit https://hub.docker.com/ and search for just about any popular OSS project and you will probably find out that someone has already created an image for you to utilize.
Docker containers are extremely simple to maintain, deploy, and use within your infrastructure. But what happens when you have hundreds of servers, and you’re trying to manage thousands of docker containers? Sure, if one server goes down, all you need to do, technically speaking, is re-launch those downed containers on another server. Do you have another server in your sea of servers with enough free capacity to handle this additional load? What if you were using persistent storage and need that volume moved along with the container? Running and managing large installations of containers can quickly become overwhelming.
Now we will discuss the topic of container orchestration.
Pronounced, koo-ber-net-ies, and often abbreviated K8S (there are 8 letters between the ‘K’ and last ‘S’), is the current mainstream project for managing Docker containers at very large scale. Kubernetes is Greek for “governor”, “helmsman”, or “captain”. Rather than repeating it here, you can read more about the history of K8S on your own.
K8S has many moving parts to itself, as you might have imagined. Take a look at this image.
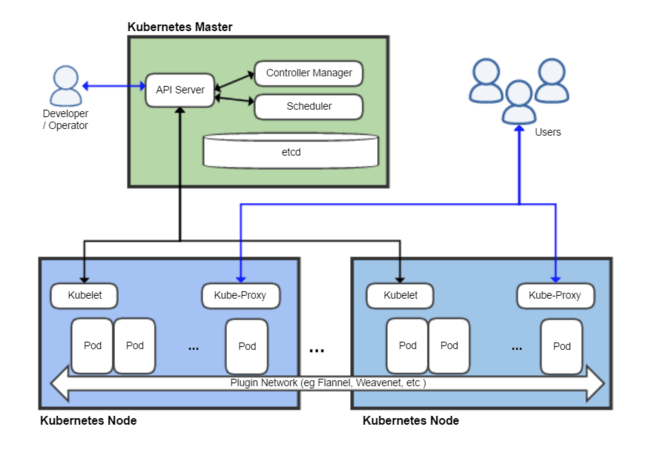
At the bottom of the image are two ‘Kubernetes Nodes’. These are usually your physical hardware servers, but could also be VMs at your cloud provider. These nodes will have a minimum OS installed, along with other necessary packages like K8S and Docker.
Kubelet is a management binary used by K8S to watch existing containers, run health checks, and launch new containers.
Kube-proxy is a simple port-mapping proxy service. Let’s say you had a simple webserver running as a container on 172.14.11.109:34223. Your end-users would access an external/public IP over 443 like normal, and kube-proxy would map/route that external access to the correct internal container.
The next concept to understand is a pod. This is typically the base term used when discussing what is running on a node. A pod can be a single container or can be an entire setup, running multiple containers, with mapped external storage, that should be grouped together as a single unit.
Networking within K8S is a complex topic, and a deep discussion is not suitable for this post. At an entry-level, what you need to know is that K8S creates an “overlay” network, allowing a container in a pod on node1 to talk to a container in a pod on node322 which is in another datacenter. Should your company policy require it, you can create multiple overlay networks across your entire K8S and use them as a way to isolate traffic between pods (ie: think old-school VLANs).
At the top of the diagram, you can see the developer/operator interacting with the K8S master node. This node runs several processes which are critical to K8S operation:
kube-apiserver: A simple server to handle/route/process API requests from other K8S tools and even your own custom tools
etcd: A highly available key-value store. This is where K8S stores all of its stateful data.
kube-scheduler: Manages inventory and decides where to launch new pods based on available node resources.
You might have noticed that there is only 1 master node in the above diagram. This is the default installation. This is not highly available and should the master node go down, the entire K8S infrastructure will go down with it. In a true production environment, it is highly recommended that you run the master node in a highly-available manner.
In this post, we discussed how traditional hardware-based setups have been slowly migrating, first towards virtual machine setups and now to containerized deployments. We brought up the issues surrounding managing large container environments and introduced the leading container orchestration platform, Kubernetes. Lastly, we dove into K8S’s various components and architecture.
Once you have your K8S cluster set up with a master node, and many worker nodes, you’ll finally be able to launch some pods and have services accessible. This is what we will do in part 2 of this blog series.
Resources
RELATED POSTS





I have seen about Docker Swarm before and I see Kubernetes is extremely difficult to understand