
 PostgreSQL is one of the finest object-relational databases, and its architecture is process-based instead of thread-based. While almost all the current database systems utilize threads for parallelism, PostgreSQL’s process-based architecture was implemented prior to POSIX threads. PostgreSQL launches a process “postmaster” on startup, and after that spans new process whenever a new client connects to the PostgreSQL.
PostgreSQL is one of the finest object-relational databases, and its architecture is process-based instead of thread-based. While almost all the current database systems utilize threads for parallelism, PostgreSQL’s process-based architecture was implemented prior to POSIX threads. PostgreSQL launches a process “postmaster” on startup, and after that spans new process whenever a new client connects to the PostgreSQL.
Before version 10 there was no parallelism in a single connection. It is true that multiple queries from the different clients can have parallelism because of process architecture, but they couldn’t gain any performance benefit from one another. In other words, a single query runs serially and did not have parallelism. This is a huge limitation because a single query cannot utilize the multi-core. Parallelism in PostgreSQL was introduced from version 9.6. Parallelism, in a sense, is where a single process can have multiple threads to query the system and utilize the multicore in a system. This gives PostgreSQL intra-query parallelism.
Parallelism in PostgreSQL was implemented as part of multiple features which cover sequential scans, aggregates, and joins.
There are three important components of parallelism in PostgreSQL. These are the process itself, gather, and workers. Without parallelism the process itself handles all the data, however, when planner decides that a query or part of it can be parallelized, it adds a Gather node within the parallelizable portion of the plan and makes a gather root node of that subtree. Query execution starts at the process (leader) level and all the serial parts of the plan are run by the leader. However, if parallelism is enabled and permissible for any part (or whole) of the query, then gather node with a set of workers is allocated for it. Workers are the threads that run in parallel with part of the tree (partial-plan) that needs to be parallelized. The relation’s blocks are divided amongst threads such that the relation remains sequential. The number of threads is governed by settings as set in PostgreSQL’s configuration file. The workers coordinate/communicate using shared memory, and once workers have completed their work, the results are passed on to the leader for accumulation.
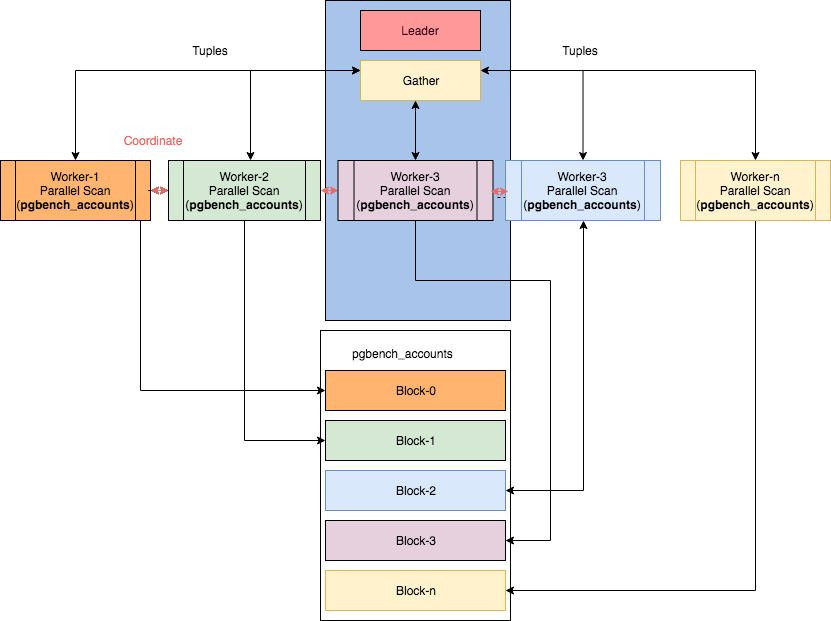
In PostgreSQL 9.6, support for the parallel sequential scan was added. A sequential scan is a scan on a table in which a sequence of blocks is evaluated one after the other. This, by its very nature, allows parallelism. So this was a natural candidate for the first implementation of parallelism. In this, the whole table is sequentially scanned in multiple worker threads. Here is the simple query where we query the pgbench_accounts table rows (63165) which has 1500000000 tuples. The total execution time is 4343080ms. As there is no index defined, the sequential scan is used. The whole table is scanned in a single process with no thread. Therefore the single core of CPU is used regardless of how many cores are available.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
db=# EXPLAIN ANALYZE SELECT * FROM pgbench_accounts WHERE abalance > 0; QUERY PLAN ---------------------------------------------------------------------- Seq Scan on pgbench_accounts (cost=0.00..73708261.04 rows=1 width=97) (actual time=6868.238..4343052.233 rows=63165 loops=1) Filter: (abalance > 0) Rows Removed by Filter: 1499936835 Planning Time: 1.155 ms Execution Time: 4343080.557 ms (5 rows) |
What if these 1,500,000,000 rows scanned parallel using “10” workers within a process? It will reduce the execution time drastically.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
db=# EXPLAIN ANALYZE select * from pgbench_accounts where abalance > 0; QUERY PLAN ---------------------------------------------------------------------- Gather (cost=1000.00..45010087.20 rows=1 width=97) (actual time=14356.160..1628287.828 rows=63165 loops=1) Workers Planned: 10 Workers Launched: 10 -> Parallel Seq Scan on pgbench_accounts (cost=0.00..45009087.10 rows=1 width=97) (actual time=43694.076..1628068.096 rows=5742 loops=11) Filter: (abalance > 0) Rows Removed by Filter: 136357894 Planning Time: 37.714 ms Execution Time: 1628295.442 ms (8 rows) |
Now the total execution time is 1628295ms; this is a 266% improvement while using 10 workers thread used to scan.
Query used for the Benchmark: SELECT * FROM pgbench_accounts WHERE abalance > 0;
Size of Table: 426GB
Total Rows in Table: 1500000000
The system used for the Benchmark:
CPU: 2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
RAM: 256GB DDR3 1600
DISK: ST3000NM0033
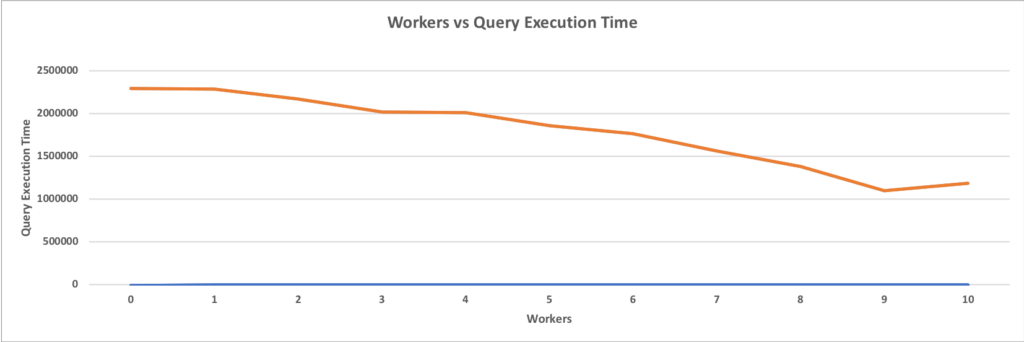
The above graph clearly shows how parallelism improves performance for a sequential scan. When a single worker is added, the performance understandably degrades as no parallelism is gained, but the creation of an additional gather node and a single work adds overhead. However, with more than one worker thread, the performance improves significantly. Also, it is important to note that performance doesn’t increase in a linear or exponential fashion. It improves gradually until the addition of more workers will not give any performance boost; sort of like approaching a horizontal asymptote. This benchmark was performed on a 64-core machine, and it is clear that having more than 10 workers will not give any significant performance boost.
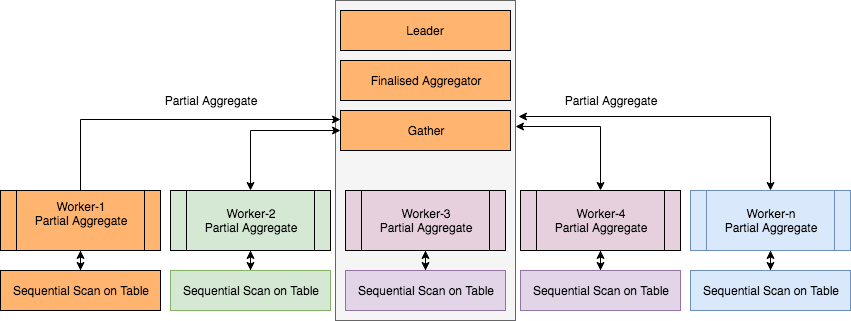
In databases, calculating aggregates are very expensive operations. When evaluated in a single process, these take a reasonably long time. In PostgreSQL 9.6, the ability to calculate these in parallel was added by simply dividing these in chunks (a divide and conquer strategy). This allowed multiple workers to calculate the part of aggregate before the final value(s) based on these calculations was calculated by the leader. More technically speaking, PartialAggregate nodes are added to a plan tree, and each PartialAggregate node takes the output from one worker. These outputs are then emitted to a FinalizeAggregate node that combines the aggregates from multiple (all) PartialAggregate nodes. So effectively, the parallel partial plan includes a FinalizeAggregate node at the root and a Gather node which will have PartialAggregate nodes as children.
|
1 2 3 4 5 6 7 8 9 10 |
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts; QUERY PLAN ---------------------------------------------------------------------- Aggregate (cost=73708261.04..73708261.05 rows=1 width=8) (actual time=2025408.357..2025408.358 rows=1 loops=1) -> Seq Scan on pgbench_accounts (cost=0.00..67330666.83 rows=2551037683 width=0) (actual time=8.162..1963979.618 rows=1500000000 loops=1) Planning Time: 54.295 ms Execution Time: 2025419.744 ms (4 rows) |
Following is an example of a plan when an aggregate is to be evaluated in parallel. You can clearly see performance improvement here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
db=# EXPLAIN ANALYZE SELECT count(*) from pgbench_accounts; QUERY PLAN ---------------------------------------------------------------------- Finalize Aggregate (cost=45010088.14..45010088.15 rows=1 width=8) (actual time=1737802.625..1737802.625 rows=1 loops=1) -> Gather (cost=45010087.10..45010088.11 rows=10 width=8) (actual time=1737791.426..1737808.572 rows=11 loops=1) Workers Planned: 10 Workers Launched: 10 -> Partial Aggregate (cost=45009087.10..45009087.11 rows=1 width=8) (actual time=1737752.333..1737752.334 rows=1 loops=11) -> Parallel Seq Scan on pgbench_accounts (cost=0.00..44371327.68 rows=255103768 width=0) (actual time=7.037..1731083.005 rows=136363636 loops=11) Planning Time: 46.031 ms Execution Time: 1737817.346 ms (8 rows) |
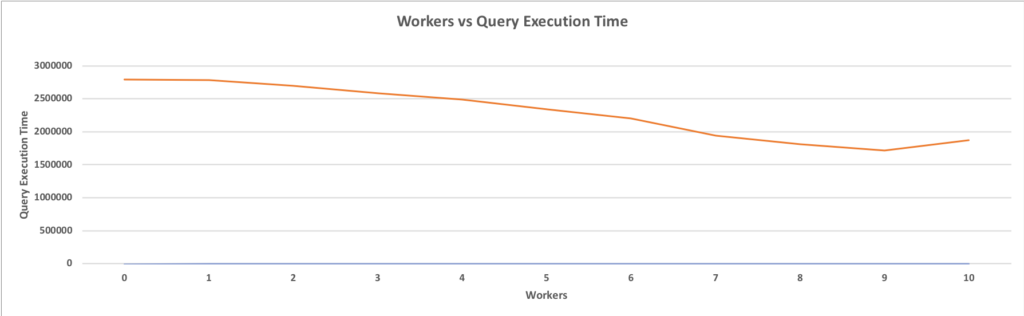
With parallel aggregates, in this particular case, we get a performance boost of just over 16% as the execution time of 2025419.744 is reduced to 1737817.346 when 10 parallel workers are involved.
Query used for the Benchmark: SELECT count(*) FROM pgbench_accounts WHERE abalance > 0;
Size of Table: 426GB
Total Rows in Table: 1500000000
The system used for the Benchmark:
CPU: 2 Intel(R) Xeon(R) CPU E5-2643 v2 @ 3.50GHz
RAM: 256GB DDR3 1600
DISK: ST3000NM0033
The parallel support for B-Tree index means index pages are scanned in parallel. The B-Tree index is one of the most used indexes in PostgreSQL. In a parallel version of B-Tree, a worker scans the B-Tree and when it reaches its leaf node, it then scans the block and triggers the blocked waiting worker to scan the next block.
Confused? Let’s look at an example of this. Suppose we have a table foo with id and name columns, with 18 rows of data. We create an index on the id column of table foo. A system column CTID is attached with each row of table which identifies the physical location of the row. There are two values in the CTID column: the block number and the offset.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
postgres=# <strong>SELECT</strong> ctid, id <strong>FROM</strong> foo; ctid | id --------+----- (0,55) | 200 (0,56) | 300 (0,57) | 210 (0,58) | 220 (0,59) | 230 (0,60) | 203 (0,61) | 204 (0,62) | 300 (0,63) | 301 (0,64) | 302 (0,65) | 301 (0,66) | 302 (1,31) | 100 (1,32) | 101 (1,33) | 102 (1,34) | 103 (1,35) | 104 (1,36) | 105 (18 rows) |
Let’s create the B-Tree index on that table’s id column.
|
1 |
CREATE INDEX foo_idx ON foo(id) |
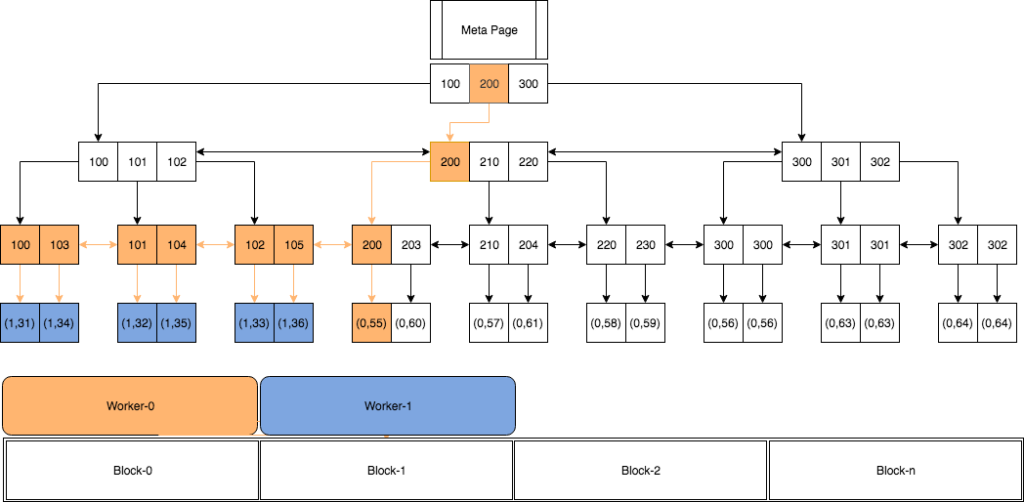
Suppose we want to select values where id <= 200 with 2 workers. Worker-0 will start from the root node and scan until the leaf node 200. It’ll handover the next block under node 105 to Worker-1, which is in a blocked and wait-state. If there are other workers, blocks are divided into the workers. A similar pattern is repeated until the scan is completed.
Parallel Bitmap Scans
To parallelize a bitmap heap scan, we need to be able to divide blocks among workers in a way very similar to parallel sequential scan. To do that, a scan on one or more indexes is done and a bitmap indicating which blocks are to be visited is created. This is done by a leader process, i.e. this part of the scan is run sequentially. However, the parallelism kicks in when the identified blocks are passed to workers, the same way as in a parallel sequential scan.
Parallel Joins
Parallelism in the merge joins support is also one of the hottest features added in this release. In this, a table joins with other tables’ inner loop hash or merge. In any case, there is no parallelism supported in the inner loop. The entire loop is scanned as a whole, and the parallelism occurs when each worker executes the inner loop as a whole. The results of each join sent to gather accumulate and produce the final results.
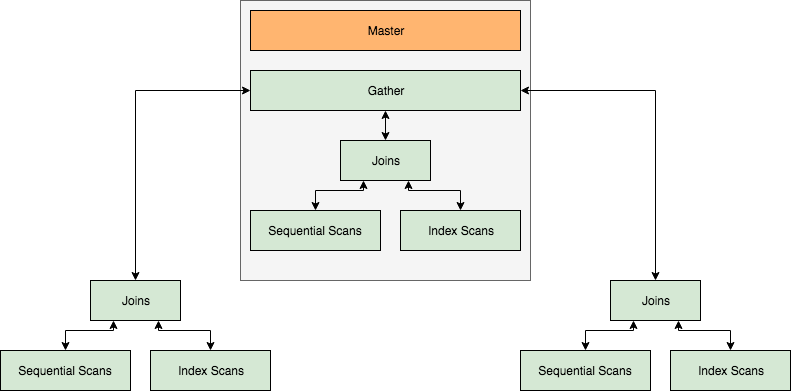
It is obvious from what we’ve already discussed in this blog that parallelism gives significant performance boosts for some, slight gains for others, and may cause performance degradation in some cases. Ensure that parallel_setup_cost or parallel_tuple_cost are set up correctly to enable the query planner to choose a parallel plan. Even after setting low values for these GUIs, if a parallel plan is not produced, refer to the PostgreSQL documentation on parallelism for details.
For a parallel plan, you can get per-worker statistics for each plan node to understand how the load is distributed amongst workers. You can do that through EXPLAIN (ANALYZE, VERBOSE). As with any other performance feature, there is no one rule that applies to all workloads. Parallelism should be carefully configured for whatever the need may be, and you must ensure that the probability of gaining performance is significantly higher than the probability of a drop in performance.
Our white paper looks at the features and benefits of PostgreSQL and presents some practical usage examples. We also examine how PostgreSQL can be useful for companies looking to migrate from Oracle.
Resources
RELATED POSTS





Great explanation, but I noticed that your graphs seem to be showing the opposite of what you are saying. The more workers you add the lower the Query Execution Time, as I am currently reading the graph it looks like the query is taking longer the more workers you have.
Thanks Derek, Its was typo and fixed.
I don’t think that swapping the Worker legend fixed it. I don’t have your source data from your tests, but from your explanation it took 4343080ms to run the sequential scan without parallelism. When you add one worker it makes sense that the cost will increase slightly since you have the added overhead of the gather process. After that the cost should decrease down to a final speed of 1628295ms with 10 workers.
The line on your graph tells that story but in reverse, showing a slight decrease with that addition of the gather process and then a steady increase as workers are added with a final diminishing return when you reach 10 workers. I feel that by reversing the direction of the Workers legend it just added confusion to the graph.
I believe the graph should be downward sloping to the right, with the X axis increasing from 0 to 10 like in the original version. What caught my eye when I was originally reading the article what that the data points from your description didn’t match up with the Y axis legend
No, data is correct, Here is the complete dataset I have for the first graph
Workers Execution Time (ms)
10 1182976
9 1098745
8 1382642
7 1561483
6 1764753
5 1855142
4 2009847
3 2012568
2 2164726
1 2285845
0 2288745
One more thing, a slight variation in benchmark is expected, even I did that multiple time and took the median to remove the ourlier.
To remove the confusion, lets draw that in increasing order
I like how that looks, it matches up with what you are describing and helps reinforce the comment about reaching a limit of how throwing more workers at the problem will eventually have a negative effect.
Thanks for your input.
“PostgreSQL is one of the finest object-relational databases”
It’s the only database I’ve ever heard describe itself as “object-relational”, and its object features are so weak and unmaintained that its own manual suggests avoiding them.
Let’s call a spade a spade. It’s a relational database.
hi,Ibrar,
I find the following:
when I execute a large query which use parallel(pg version is 10 or 11), at the same time, there are some file created in the /dev/shm/ directory, and file name is “PostgreSQL.NNNNNNNNN”,
I want to know:
1. What is the file PostgreSQL.NNNNNNNNN ,and what does NNNNNNNNN mean?
2.If this file(PostgreSQL.NNNNNNNNN) is about parallel, and if the PG has very high parallel throughouts, should we set the large /dev/shm ?
Don’t worry about PostgreSQL.NNNNN file, it is for internal use. The “NNNNN” is a internal handle information. You only need to worry about shared_buffers. a
How do I set up a query to use multiple workers?