
 Recently I had a customer where every single query was running in a transaction, as well as even the simplest selects. Unfortunately, this is not unique and many connectors like Java love to do that.
Recently I had a customer where every single query was running in a transaction, as well as even the simplest selects. Unfortunately, this is not unique and many connectors like Java love to do that.
In their case, the Java connector changed autocommit=off for the connection itself at the beginning, and as these were permanent connections they never or almost never reconnected.
In the slow query log we could see after every select there was a commit. So why is this a problem?
Like always, the best way to deal with a problem to test it. I have created two EC2 instances t3.xlarge with Ubuntu, one for application and one for the databases. I have used sysbench to run my tests.
I have created a table with 1 million records and was running simple primary key point selects against the database. I was using three threads and running only 1 select per transactions, and every test was running for 60 seconds. I ran every test 3 times and took the average number of these three runs. These are the only MySQL variables I have changed:
|
1 2 3 4 |
innodb_buffer_pool_size=5G innodb_adaptive_hash_index=off query_cache_size=0 query_cache_type=0 |
The dataset could fit in memory as there were no disk reads.
I have tested four cases:
I was not trying to do a proper performance test to see the maximum performance on the server. I was only trying to demonstrate the impact on the executed query number if we are running every single query in a transaction in a limited time window.
Because my customer was running on MySQL 5.6 I did my first tests on that version as well.
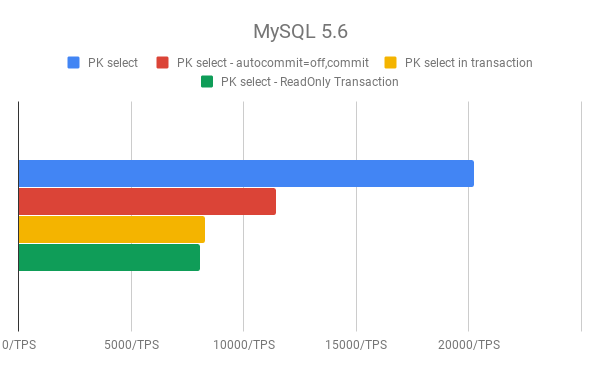
Here we can see the average transactions per second (inside InnoDB everything is a transaction even if we do not start it explicitly). In the same time window, sysbench could run more than twice as many PK lookups without transactions than in transactions. You can see there are big differences here.
It depends on your point of view, but if you measure the whole transaction time, yes it takes more time, but if you measure the single select statement that should take the same amount of time. So your single selects are not going to be slower.
Let me try to oversimplify this. Let’s say your database server can run only 1 query per second. That means in 100 seconds it can run 100 queries. What if we are using transaction? In the first second the database server will run the begin, then it runs the selectcommit. So it will run 1 select in every three seconds. In 100 seconds 33 begin, 33 select, 33 commit. Your query time is not going to be higher but your throughput is going to be impacted.
If there is no real reason (example repeatable read) why your selects should run in transactions, I would recommend to avoid them, because you can save a lot of extra roundtrip between the application and the database server, some CPU time, and even begin commits very fast, but in large scale you can save time as well.
Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back.
Database transactions, as implemented by InnoDB, have properties that are collectively known by the acronym ACID, for atomicity, consistency, isolation, and durability.
InnoDB associates every transaction with a transaction ID (TRX_ID field is part of every single row). That transaction ID is only needed for operations that might perform writes or locks like Select ... for update. Also, this transaction ID is used to create a read view, a snapshot of the database, as this is part of the MVCC mechanism. MVCC keeps information of the old pages until the transaction is running, an example is to be able to rollback. These pages also used to provide consistent reads. Even if this is just a single long-running select, because we started a transaction, InnoDB has to keep track of these changes. There are other internal processes happening when we explicitly start a transaction, which might be not necessary for a simple select query.
This is one of the reasons why they developed Read-only transactions to avoid these side effects.
When autocommit is enabled and we do not start transactions explicitly, the insert/delete/update operations are still handled inside MySQL like transactions, but InnoDB tries to detect non-locking select queries which should be handled like Read-only transactions.
I was curious if is there any difference/improvements between the versions so I re-ran my tests on multiple MySQL versions.
I have tested:
![]()
What we can see here? We can see that a big difference is still there in all versions, and actually, I was not expecting it to disappear because from the application point of view it still has to do the round trips to the database server.
We knew there is a regression in the newer version of MySQL regarding the performance of point lookups. Mark Callaghan and many other people already blogged about this, but as we can see the regression is quite big. I am already working on another blog post where I am trying to dig deeper on what is causing this degradation.
The newer version of MySQL servers are more optimized on high concurrent workloads, and they can handle more threads at the same time as the previous versions. There are many detailed blog posts in this area as well.
We can also see, for these simple queries starting Read-only transactions, they are actually a lit bit slower than starting normal transactions. The difference is between 1-4% while in MySQL 8.0 it is around 1% slower. That is a very small difference but is continuous through all the tests.
If you are running every single select query in a transaction your throughput could be definitely lower than without transactions. If your application requires higher throughput, you should not use explicit transactions for every select query.
Resources
RELATED POSTS





Thanks, I’ve been wondering was is the impact of various transaction models on SELECT.
The disclaimer part is important and I find the title a bit misleading. The benchmark is not measuring the impact of a transaction on the query time, but the impact of additional roundtrip in a business process. Obviously, the more roundtrip, the longer it gets!
It would be nice to run a similar test, but to increase the number of threads measure the max QPS at full server capacity.
Questions about the 4 cases you tested:
1) How do you do a SELECT without transaction?
2) How is “SELECT without transaction” different from “autocommit=off (select,commit)”?
3) For the case of “autocommit=off (select,commit)” seems like you’re still using a new transaction for each SELECT. So how is it different from the case “inside a transaction (begin,select,commit)”?
Thanks.
Hi Andy,
As I have mentioned in the blog post as well, every query even selects inside InnoDB they are running in a transactions, but there are differences between explicit and implicit transaction example, just the round trips between the database and the application servers. As you can see these round trips can impact the throughput very much.
So the answers to your questions:
1) You can start a select without explicitly using a transaction, that was I meant it that part.
2) In that case the application does not have to send the
start transactionandcommit.3) The test did not start an explicit transaction.
Maybe the easiest way to show what would you see in the slow log if it was enabled:
1) “Select without transaction” – no explicit transaction: In the slow log you could see only select queries like:
“select c from sbtest1 where id=XX;”
“select c from sbtest1 where id=XY;”
“select c from sbtest1 where id=XXX;”
2) “inside a transaction (begin,select,commit) – we start explicit transaction”, In the slow log will see this:
“start transaction;”
“select c from sbtest1 where id=XX;”
“commit;”
3) autocommit=off (select,commit) – in the slow log you will see:
“select c from sbtest1 where id=XX;”
“commit;”
“select c from sbtest1 where id=XX;”
“commit;”
4) Read-Only transaction – in the slow log you will see:
“START TRANSACTION READ ONLY”
“select c from sbtest1 where id=XX;”
“commit;”
I hope this makes it more clear.
Hi Tibor,
Thanks for the examples. That really helps.
To make sure I got it right, your examples only work when autocommit=off, right?
If autocommit is not turned off, then
“select c from sbtest1 where id=XX;”
would be exactly the same as:
“start transaction;”
“select c from sbtest1 where id=XX;”
“commit;”
Correct?
Hi Andy,
That is a more complex question than you would think. But the short answer it is not the same. From the application point of view 3 times more roundtrip. From MySQL view they are also not the same because MySQL handles the autocommit=0N + read only queries differently and MySQL even try to catch the read only queries and run them like a read only transaction. More details here:
https://dev.mysql.com/doc/refman/8.0/en/innodb-performance-ro-txn.html
https://web.archive.org/web/20120108020602/http://blogs.innodb.com/wp/2011/12/better-scaling-of-read-only-workloads/
http://dimitrik.free.fr/blog/archives/2012/07/mysql-performance-readonly-adventure-in-mysql-56.html