
 There is a wide variety of indexes available in PostgreSQL. While most are common in almost all databases, there are some types of indexes that are more specific to PostgreSQL. For example, GIN indexes are helpful to speed up the search for element values within documents. GIN and GiST indexes could both be used for making full-text searches faster, whereas BRIN indexes are more useful when dealing with large tables, as it only stores the summary information of a page. We will look at these indexes in more detail in future blog posts. For now, I would like to talk about another of the special indexes that can speed up searches on a table with a huge number of columns and which is massive in size. And that is called a bloom index.
There is a wide variety of indexes available in PostgreSQL. While most are common in almost all databases, there are some types of indexes that are more specific to PostgreSQL. For example, GIN indexes are helpful to speed up the search for element values within documents. GIN and GiST indexes could both be used for making full-text searches faster, whereas BRIN indexes are more useful when dealing with large tables, as it only stores the summary information of a page. We will look at these indexes in more detail in future blog posts. For now, I would like to talk about another of the special indexes that can speed up searches on a table with a huge number of columns and which is massive in size. And that is called a bloom index.
In order to understand the bloom index better, let’s first understand the bloom filter data structure. I will try to keep the description as short as I can so that we can discuss more about how to create this index and when will it be useful.
Most readers will know that an array in computer sciences is a data structure that consists of a collection of values and variables. Whereas a bit or a binary digit is the smallest unit of data represented with either 0 or 1. A bloom filter is also a bit array of m bits that are all initially set to 0.
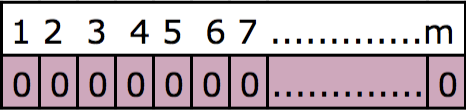
A bit array is an array that could store a certain number of bits (0 and 1). It is one of the most space-efficient data structures to test whether an element is in a set or not.
Let’s consider some alternates such as list data structure and hash tables. In the case of a list data structure, it needs to iterate through each element in the list to search for a specific element. We can also try to maintain a hash table where each element in the list is hashed, and we then see if the hash of the element we are searching for matches a hash in the list. But checking through all the hashes may be a higher order of magnitude than expected. If there is a hash collision, then it does a linear probing which may be time-consuming. When we add hash tables to disk, it requires some additional IO and storage. For an efficient solution, we can look into bloom filters which are similar to hash tables.
While using bloom filters, we may see a result that falls into a type I error but never a type II error. A nice example of a type I error is a result that a person with last name: “vallarapu” exists in the relation: foo.bar whereas it does not exist in reality (a false positive conclusion). An example for a type II error is a result that a person with the last name as “vallarapu” does not exist in the relation: foo.bar, but in reality, it does exist (a false negative conclusion). A bloom filter is 100% accurate when it says the element is not present. But when it says the element is present, it may be 90% accurate or less. So it is usually called a probabilistic data structure.
Let’s now understand the algorithm behind bloom filters better. As discussed earlier, it is a bit array of m bits, where m is a certain number. And we need a k number of hash functions. In order to tell whether an element exists and to give away the item pointer of the element, the element (data in columns) will be passed to the hash functions. Let’s say that there are only two hash functions to store the presence of the first element “avi” in the bit array. When the word “avi” is passed to the first hash function, it may generate the output as 4 and the second may give the output as 5. So now the bit array could look like the following:
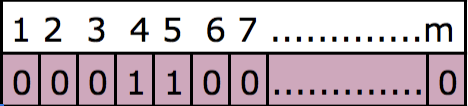
All the bits are initially set to 0. Once we store the existence of the element “avi” in the bloom filter, it sets the 4th and 5th bits to 1. Let’s now store the existence of the word “percona”. This word is again passed to both the hash functions and assumes that the first hash function generates the value as 5 and the second hash function generated the value as 6. So, the bit array now looks like the following – since the 5th bit was already set to 1 earlier, it doesn’t make any modifications there:
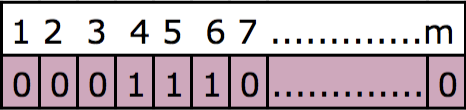
Now, consider that our query is searching for a predicate with the name as “avi”. The input: “avi” will now be passed to the hash functions. The first hash function returns the value as 4 and the second returns the value as 5, as these are the same hash functions that were used earlier. Now when we look in position 4 and 5 of the bloom filter (bit array), we can see that the values are set to 1. This means that the element is present.
Consider a query that is fetching the records of a table with the name: “don”. When this word “don” is passed to both the hash functions, the first hash function returns the value as 6 (let’s say) and the second hash function returns the value as 4. As the bits at positions 6 and 4 are set to 1, the membership is confirmed and we see from the result that a record with the name: “don” is present. In reality, it is not. This is one of the chances of collisions. However, this is not a serious problem.
A point to remember is – “The fewer the hash functions, the more the chances of collisions. And the more the hash functions, lesser the chances of collision. But if we have k hash functions, the time it takes for validating membership is in the order of k“.
As you’ll now have understood bloom filters, you’ll know a bloom index uses bloom filters. When you have a table with too many columns, and there are queries using too many combinations of columns – as predicates – on such tables, you could need many indexes. Maintaining so many indexes is not only costly for the database but is also a performance killer when dealing with larger data sets.
So, if you create a bloom index on all these columns, a hash is calculated for each of the columns and merged into a single index entry of the specified length for each row/record. When you specify a list of columns on which you need a bloom filter, you could also choose how many bits need to be set per each column. The following is an example syntax with the length of each index entry and the number of bits per a specific column.
|
1 2 |
CREATE INDEX bloom_idx_bar ON foo.bar USING bloom (id,dept_id,zipcode) WITH (length=80, col1=4, col2=2, col3=4); |
length is rounded to the nearest multiple of 16. Default is 80. And the maximum is 4096. The default number of bits per column is 2. We can specify a maximum of 4095 bits.
Here is what it means in theory when we have specified length = 80 and col1=2, col2=2, col3=4. A bit array of length 80 bits is created per row or a record. Data inside col1 (column1) is passed to two hash functions because col1 was set to 2 bits. Let’s say these two hash functions generate the values as 20 and 40. The bits at the 20th and 40th positions are set to 1 within the 80 bits (m) since the length is specified as 80 bits. Data in col3 is now passed to four hash functions and let’s say the values generated are 2, 4, 9, 10. So four bits – 2, 4, 9, 10 –are set to 1 within the 80 bits.
There may be many empty bits, but it allows for more randomness across the bit arrays of each of the individual rows. Using a signature function, a signature is stored in the index data page for each record along with the row pointer that points to the actual row in the table. Now, when a query uses an equality operator on the column that has been indexed using bloom, a number of hash functions, as already set for that column, are used to generate the appropriate number of hash values. Let’s say four for col3 – so 2, 4, 9, 10. The index data is extracted row-by-row and searched if the rows have those bits (bit positions generated by hash functions) set to 1.
And finally, it says a certain number of rows have got all of these bits set to 1. The greater the length and the bits per column, the more the randomness and the fewer the false positives. But the greater the length, the greater the size of the index.
Bloom index is shipped through the contrib module as an extension, so you must create the bloom extension in order to take advantage of this index using the following command:
|
1 |
CREATE EXTENSION bloom; |
Let’s start with an example. I am going to create a table with multiple columns and insert 100 million records.
|
1 2 3 4 5 6 7 8 |
percona=# CREATE TABLE foo.bar (id int, dept int, id2 int, id3 int, id4 int, id5 int,id6 int,id7 int,details text, zipcode int); CREATE TABLE percona=# INSERT INTO foo.bar SELECT (random() * 1000000)::int, (random() * 1000000)::int, (random() * 1000000)::int,(random() * 1000000)::int,(random() * 1000000)::int,(random() * 1000000)::int, (random() * 1000000)::int,(random() * 1000000)::int,md5(g::text), floor(random()* (20000-9999 + 1) + 9999) from generate_series(1,100*1e6) g; INSERT 0 100000000 |
The size of the table is now 9647 MB as you can see below.
|
1 2 3 4 5 |
percona=# dt+ foo.bar List of relations Schema | Name | Type | Owner | Size | Description -------+------+-------+----------+---------+------------- foo | bar | table | postgres | 9647 MB | (1 row) |
Let’s say that all the columns: id, dept, id2, id3, id4, id5, id6 and zip code of table: foo.bar are used in several queries in random combinations according to different reporting purposes. If we create individual indexes on each column, it is going to take almost 2 GB disk space for each index.
We’ll try creating a single btree index on all the columns that are most used by the queries hitting this table. As you can see in the following log, it took 91115.397 ms to create this index and the size of the index is 4743 MB.
|
1 2 3 4 5 6 7 8 9 10 |
postgres=# CREATE INDEX idx_btree_bar ON foo.bar (id, dept, id2,id3,id4,id5,id6,zipcode); CREATE INDEX Time: 91115.397 ms (01:31.115) postgres=# di+ foo.idx_btree_bar List of relations Schema | Name | Type | Owner | Table | Size | Description --------+---------------+-------+----------+-------+---------+------------- foo | idx_btree_bar | index | postgres | bar | 4743 MB | (1 row) |
Now, let’s try some of the queries with a random selection of columns. You can see that the execution plans of these queries are 2440.374 ms and 2406.498 ms for query 1 and query 2 respectively. To avoid issues with the disk IO, I made sure that the execution plan was captured when the index was cached to memory.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
Query 1 ------- postgres=# EXPLAIN ANALYZE select * from foo.bar where id4 = 295294 and zipcode = 13266; QUERY PLAN ----------------------------------------------------------------------------------------------------- Index Scan using idx_btree_bar on bar (cost=0.57..1607120.58 rows=1 width=69) (actual time=1832.389..2440.334 rows=1 loops=1) Index Cond: ((id4 = 295294) AND (zipcode = 13266)) Planning Time: 0.079 ms Execution Time: 2440.374 ms (4 rows) Query 2 ------- postgres=# EXPLAIN ANALYZE select * from foo.bar where id5 = 281326 and id6 = 894198; QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_btree_bar on bar (cost=0.57..1607120.58 rows=1 width=69) (actual time=1806.237..2406.475 rows=1 loops=1) Index Cond: ((id5 = 281326) AND (id6 = 894198)) Planning Time: 0.096 ms Execution Time: 2406.498 ms (4 rows) |
Let’s now create a bloom index on the same columns. As you can see from the following log, there is a huge size difference between the bloom (1342 MB) and the btree index (4743 MB). This is the first win. It took almost the same time to create the btree and the bloom index.
|
1 2 3 4 5 6 7 8 9 10 11 |
postgres=# CREATE INDEX idx_bloom_bar ON foo.bar USING bloom(id, dept, id2, id3, id4, id5, id6, zipcode) WITH (length=64, col1=4, col2=4, col3=4, col4=4, col5=4, col6=4, col7=4, col8=4); CREATE INDEX Time: 94833.801 ms (01:34.834) postgres=# di+ foo.idx_bloom_bar List of relations Schema | Name | Type | Owner | Table | Size | Description --------+---------------+-------+----------+-------+---------+------------- foo | idx_bloom_bar | index | postgres | bar | 1342 MB | (1 row) |
Let’s run the same queries, check the execution time, and observe the difference.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
Query 1 ------- postgres=# EXPLAIN ANALYZE select * from foo.bar where id5 = 326756 and id6 = 597560; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Bitmap Heap Scan on bar (cost=1171823.08..1171824.10 rows=1 width=69) (actual time=1265.269..1265.550 rows=1 loops=1) Recheck Cond: ((id4 = 295294) AND (zipcode = 13266)) Rows Removed by Index Recheck: 2984788 Heap Blocks: exact=59099 lossy=36090 -> Bitmap Index Scan on idx_bloom_bar (cost=0.00..1171823.08 rows=1 width=0) (actual time=653.865..653.865 rows=99046 loops=1) Index Cond: ((id4 = 295294) AND (zipcode = 13266)) Planning Time: 0.073 ms Execution Time: 1265.576 ms (8 rows) Query 2 ------- postgres=# EXPLAIN ANALYZE select * from foo.bar where id5 = 281326 and id6 = 894198; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------------------ Bitmap Heap Scan on bar (cost=1171823.08..1171824.10 rows=1 width=69) (actual time=950.561..950.799 rows=1 loops=1) Recheck Cond: ((id5 = 281326) AND (id6 = 894198)) Rows Removed by Index Recheck: 2983893 Heap Blocks: exact=58739 lossy=36084 -> Bitmap Index Scan on idx_bloom_bar (cost=0.00..1171823.08 rows=1 width=0) (actual time=401.588..401.588 rows=98631 loops=1) Index Cond: ((id5 = 281326) AND (id6 = 894198)) Planning Time: 0.072 ms Execution Time: 950.827 ms (8 rows) |
From the above tests, it is evident that the bloom indexes performed better. Query 1 took 1265.576 ms with a bloom index and 2440.374 ms with a btree index. And query 2 took 950.827 ms with bloom and 2406.498 ms with btree. However, the same test will show a better result for a btree index, if you would have created a btree index on those 2 columns only (instead of many columns).
If you look at the execution plans generated after creating the bloom indexes (consider Query 2), 98631 rows are considered to be matching rows. However, the output says only one row. So, the rest of the rows – all 98630 – are false positives. The btree index would not return any false positives.
In order to reduce the false positives, you may have to increase the signature length and also the bits per column through some of the formulas mentioned in this interesting blog post through experimentation and testing. As you increase the signature length and bits, you might see the bloom index growing in size. Nevertheless, this may reduce false positives. If the time spent is greater due to the number of false positives returned by the bloom index, you could increase the length. If increasing the length does not make much difference to the performance, then you can leave the length as it is.
Bloom indexes are very helpful when we have a table that stores huge amounts of data and a lot of columns, where we find it difficult to create a large number of indexes, especially in OLAP environments where data is loaded from several sources and maintained for reporting. You could consider testing a single bloom index to see if you can avoid implementing a huge number of individual or composite indexes that could take additional disk space without much performance gain.
Resources
RELATED POSTS





Bloom Indexes are totally unsuited for olap queries as you can not use datetime range filters.
Nicely explained. Thanks.
I think Bloom Index is the first bitmap index in PostgreSQL. So, would this be faster for columns with limited values such as enums?