
Every database management system is not optimized for every workload. Database systems are designed for specific loads, and thereby give better performance for that workload. Similarly, some kinds of queries work better on some database systems and worse on others. This is the era of specialization, where a product is designed for a specific requirement or a specific set of requirements. We cannot achieve everything performance-wise from a single database system. PostgreSQL is one of the finest object databases and performs really well in OLTP types of workloads, but I have observed that its performance is not as good as some other database systems for OLAP workloads. ClickHouse is one of the examples that outperforms PostgreSQL for OLAP.
ClickHouse is an open source, column-based database management system which claims to be 100–1,000x faster than traditional approaches, capable of processing of more than a billion rows in less than a second.
If we have a different kind of workload that PostgreSQL is not optimized for, what is the solution? Fortunately, PostgreSQL provides a mechanism where you can handle a different kind of workload while using it, by creating a data proxy within PostgreSQL that internally calls and fetches data from a different database system. This is called Foreign Data Wrapper, which is based on SQL-MED. Percona provides a foreign data wrapper for the Clickhousedb database system, which is available at Percona’s GitHub project repository.
Ontime (On Time Reporting Carrier On-Time Performance) is an openly-available dataset I have used to benchmark. It has a table size of 85GB with 109 number of different types of columns, and its designed queries more closely emulate the real world.
https://github.com/Percona-Lab/ontime-airline-performance/blob/master/download.sh
| Q# | Query Contains Aggregates and Group By |
|---|---|
| Q1 | SELECT DayOfWeek, count(*) AS c FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC; |
| Q2 | SELECT DayOfWeek, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY DayOfWeek ORDER BY c DESC; |
| Q3 | SELECT Origin, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Origin ORDER BY c DESC LIMIT 10; |
| Q4 | SELECT Carrier, count(*) FROM ontime WHERE DepDelay>10 AND Year = 2007 GROUP BY Carrier ORDER BY count(*) DESC; |
| Q5 | SELECT a.Carrier, c, c2, c*1000/c2 as c3 FROM ( SELECT Carrier, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year=2007 GROUP BY Carrier ) a INNER JOIN ( SELECT Carrier,count(*) AS c2 FROM ontime WHERE Year=2007 GROUP BY Carrier) b on a.Carrier=b.Carrier ORDER BY c3 DESC; |
| Q6 | SELECT a.Carrier, c, c2, c*1000/c2 as c3 FROM ( SELECT Carrier, count(*) AS c FROM ontime WHERE DepDelay>10 AND Year >= 2000 AND Year <= 2008 GROUP BY Carrier) a INNER JOIN ( SELECT Carrier, count(*) AS c2 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier ) b on a.Carrier=b.Carrier ORDER BY c3 DESC; |
| Q7 | SELECT Carrier, avg(DepDelay) * 1000 AS c3 FROM ontime WHERE Year >= 2000 AND Year <= 2008 GROUP BY Carrier; |
| Q8 | SELECT Year, avg(DepDelay) FROM ontime GROUP BY Year; |
| Q9 | select Year, count(*) as c1 from ontime group by Year; |
| Q10 | SELECT avg(cnt) FROM (SELECT Year,Month,count(*) AS cnt FROM ontime WHERE DepDel15=1 GROUP BY Year,Month) a; |
| Q11 | select avg(c1) from (select Year,Month,count(*) as c1 from ontime group by Year,Month) a; |
| Q12 | SELECT OriginCityName, DestCityName, count(*) AS c FROM ontime GROUP BY OriginCityName, DestCityName ORDER BY c DESC LIMIT 10; |
| Q13 | SELECT OriginCityName, count(*) AS c FROM ontime GROUP BY OriginCityName ORDER BY c DESC LIMIT 10; |
| Query Contains Joins | |
| Q14 | SELECT a.Year, c1/c2 FROM ( select Year, count(*)*1000 as c1 from ontime WHERE DepDelay>10 GROUP BY Year) a INNER JOIN (select Year, count(*) as c2 from ontime GROUP BY Year ) b on a.Year=b.Year ORDER BY a.Year; |
| Q15 | SELECT a."Year", c1/c2 FROM ( select "Year", count(*)*1000 as c1 FROM fontime WHERE "DepDelay">10 GROUP BY "Year") a INNER JOIN (select "Year", count(*) as c2 FROM fontime GROUP BY "Year" ) b on a."Year"=b."Year"; |
Table-1: Queries used in the benchmark
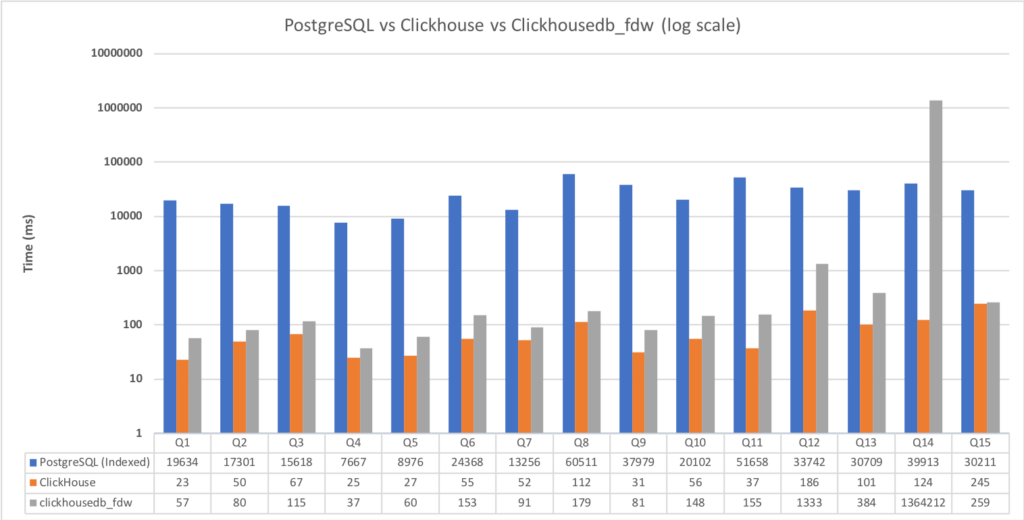
This graph shows the time taken by each query in PostgreSQL, ClickHouse, and Clickhusedb_fdw. You can clearly see that ClickHouse performs really well on its own while PostgreSQL doesn't. The benchmark has been done on a single node with multiple CPU cores and can scale with multiple nodes. But I think we can see enough performance as ClickHouse is almost 1000x faster in most of the queries. In a previous blog post, I went over some of the reasons why some queries do not perform well in clickhouse_fdw, if you would like to learn more.
The graph above proves my point that PostgreSQL is not fit for every type of workload and query. However, the beauty of PostgreSQL is its ability to use its foreign data wrappers to create a heterogeneous environment with other database systems, which can then optimally handle specific workloads.
The clickhousedb_fdw clearly gives users the power to use ClickHouse for much-improved performance for OLAP workloads whilst still interacting with PostgreSQL only. This has simplified client applications that don't need to interact with multiple database systems.
Resources
RELATED POSTS




