
This post was originally published in March 2019 and was updated in February 2025.
Planning a PostgreSQL upgrade but not sold on pg_upgrade? You’re not alone.
If pg_upgrade feels too risky or limiting, pg_dump and pg_restore give you something better: full control. You can move across major versions, make schema changes, and leave storage format headaches behind. But flexibility comes at a cost: you have to get every step right.

This guide walks through the whole process: what to do, what to watch for, and how to avoid the mistakes that trip up even experienced teams.
This post is part of our series on Upgrading or Migrating Your Legacy PostgreSQL to Newer PostgreSQL Versions.
Think of pg_dump as your go-to tool for extracting a database, piece by piece, in a format that works across major PostgreSQL versions. It’s especially handy for big version jumps or when you want to rethink your schema layout along the way.
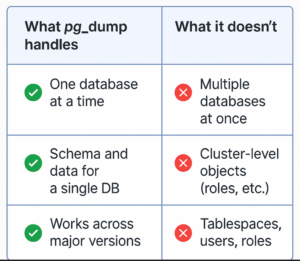
But it doesn’t cover everything. It only handles one database at a time, and skips over global objects like users, roles, and tablespaces. To fully replicate your environment, you’ll also need pg_dumpall to fill the gaps, and we’ll walk through that step first when we get into the upgrade process.
Before you run pg_dump, you’ll need to decide how you want the output structured. PostgreSQL gives you a few options, but the two most common are:
Plain Text Format: Generates a .sql file containing SQL commands. This dump can be restored using the psql client.
Pros: Human-readable, easily editable (though caution is advised).
Cons: Generally larger file size, less flexible for selective restores (e.g., restoring only specific tables is difficult).
Custom Format (-Fc): Creates a compressed, binary format dump. This must be restored using the pg_restore utility.
Pros: Compressed (smaller file size), allows for parallel restore (pg_restore -j), enables selective restoration of specific tables or objects, generally preferred for upgrades.
Cons: Not human-readable.
The choice depends on your needs. If you need to modify the schema significantly before restore or require selective object restoration, the custom format (-Fc) combined with pg_restore is usually the better option for a PostgreSQL upgrade.
A crucial point for any PostgreSQL upgrade using pg_dump/pg_restore is that both the dump and restore operations should ideally be performed using the binaries from the newer (target) PostgreSQL version. For example, when upgrading from PostgreSQL 9.3 to 11, use the pg_dump binary from version 11 to connect to the 9.3 source database.
When multiple versions are installed, specify the full path:
|
1 |
/usr/lib/postgresql/11/bin/pg_dump <connection_info_of_source_system> <options> |
PostgreSQL users/roles are global across the database cluster. These must be migrated first, as subsequent schema definitions (DDL) often contain GRANT statements referencing these roles. Use pg_dumpall -g (globals only) to export them.
|
1 2 3 4 5 6 7 8 9 |
# Dump globals to a file for review /usr/lib/postgresql/11/bin/pg_dumpall -g -p 5432 > /tmp/globals_only.sql # Restore globals using psql (after review) psql -p <destination_port> -d <destination_db> -f /tmp/globals_only.sql # Or, pipe directly if no modifications needed (local upgrade example) /usr/lib/postgresql/11/bin/pg_dumpall -g <source_connection_info> | psql -p <destination_connection_info> # Add -h for remote hosts |
Next, migrate the database schema (table definitions, views, functions, etc.). If you plan schema modifications (like partitioning or moving objects to different tablespaces) as part of the PostgreSQL upgrade, dump the schema to a plain text file using pg_dump -s (schema only) for editing.
|
1 2 3 4 |
# Dump schema only to a file for modification /usr/lib/postgresql/11/bin/pg_dump -s -d databasename -p 5432 > /tmp/schema_only.sql # Edit the file, then restore with psql psql -p <dest_port> -d <dest_db> -f /tmp/schema_only.sql |
If no schema changes are needed for a specific database, you can pipe the schema directly:
|
1 2 |
# Pipe schema directly if no changes needed /usr/lib/postgresql/11/bin/pg_dump -s -d databasename <source_connection> | psql -d database <destination_connection> |

This is where most of the time goes. Migrating your table data is the heaviest lift in the pg_dump/pg_restore upgrade process, especially for large databases.
To export just the data, use the -a (data only) flag with pg_dump. If you’re working with a custom format (-Fc), you’ll restore that data using pg_restore, which also unlocks parallel restore with the -j option. That’s a big win for performance when you’re dealing with a lot of data.
Using the plain format instead? Your data will come through as COPY commands in the dump file, which you’ll restore with psql.

Want to speed things up even more? If your schema and dependencies allow for it, you can group tables and restore them in parallel. This requires some upfront planning or scripting, but it’s worth it if time is tight.
If schema changes require reloading only specific tables after modifications, use pg_dump -t schema.tablename combined with the -a flag:
|
1 2 3 4 5 6 7 8 |
# Dump data for a single table and pipe to restore /usr/lib/postgresql/11/bin/pg_dump <sourcedb_connection_info> -d <database> -a -t schema.tablename | psql <destinationdb_connection_info> <databasename> ```For partial data migration (e.g., time-series data), use the `COPY` command with a `WHERE` clause directly via `psql`: ```bash # Copy selected data using COPY command /usr/lib/postgresql/11/bin/psql <sourcedb_connection_info> -c "COPY (SELECT * FROM <table> WHERE <filter_condition>) TO STDOUT" > /tmp/selected_table_data.sql # Restore using psql copy psql <destinationdb_connection_info> <databasename> -c "copy <table> FROM '/tmp/selected_table_data.sql'" |
Upgrading PostgreSQL with pg_dump and pg_restore might take a little more time and care than some other methods, but it gives you something most shortcuts don’t: control. You can refactor your schema, sweep out old bloat, and be confident that what you’re building on is solid.
That flexibility is exactly why teams use this method.
But if you’re looking beyond the upgrade and at what it really takes to run PostgreSQL at scale, we’ve pulled together everything you need in one place. From understanding the true cost of DIY PostgreSQL to knowing when a “free” solution becomes more expensive than you think, these resources are built to help you stay in control, cut costs, and avoid vendor lock-in.

Q1: What type of backup does pg_dump create?
A: pg_dump creates a logical backup, not a copy of the raw data files, but rather a snapshot of your database in the form of SQL commands or COPY statements. It’s like rebuilding your database from instructions, which makes it great for upgrades and migrations.
Q2: When should I use pg_dump/pg_restore for a PostgreSQL upgrade instead of pg_upgrade?
A: If you’re crossing major versions, cleaning up schema bloat, changing architectures (like 32-bit to 64-bit), or planning to make schema changes along the way, pg_dump/pg_restore is the better fit. Just know it comes with more downtime than pg_upgrade, so you’ll want a solid plan in place.
Q3: Which pg_dump format is best for upgrades?
A: Go with the custom format (-Fc). It’s smaller, faster to restore (especially with parallel jobs), and gives you the option to restore specific tables or objects if needed. It’s the format most teams use when upgrading PostgreSQL with minimal hassle.
Q4: Do I need downtime for a PostgreSQL upgrade using pg_dump/pg_restore?
A: Yes, expect some downtime. You’ll need to pause writes to the source database before the final dump to keep everything consistent, and the restore process can take a while depending on the size of your data. Want to reduce that window? Consider using logical replication alongside this method for smoother handoffs.
Q5: Why should I use the newer version’s pg_dump binary?
A: Because it knows what the new version expects. Using the newer binary to dump your old database ensures the output will restore cleanly. Stick with the old version’s pg_dump, and you might hit compatibility issues.
Resources
RELATED POSTS





“A dump taken in plain text format may be slightly larger in size when compared to a custom format dump.”
FYI, a dump of one of my clients’ databases has the following sizes:
text format: 131MB
custom format: 29M
Usually, I see text format being between 4x to 7x larger (or 100x larger on extreme cases) than custom format for a database with lots of tables and rows. Nevertheless, text formats that size make a difference when restoring because it takes a much longer time to replay all the commands.
Thank you Edward for this feedback.
On the rush, I didn’t congratulate you guys for the nice article. Thanks for sharing!