
Over time, software evolves and it is important to stay up to date if you want to benefit from new features and performance improvements. Database engines follow the exact same logic and providers are always careful to provide an easy upgrade path. With MySQL, the mysql_upgrade tool serves that purpose.
A database upgrade process becomes more challenging in a managed environment like AWS RDS where you don’t have shell access to the database host and don’t have access to the SUPER MySQL privilege. This post is a collaboration between Fattmerchant and Percona following an engagement focused on the upgrade of the Fattmerchant database from Amazon Aurora MySQL 5.6 to Amazon Aurora MySQL 5.7. Jacques Fu, the CTO of Fattmerchant, is the co-author of this post. Our initial plan was to follow a path laid out previously by others but we had difficulties finding any complete and detailed procedure outlining the steps. At least, with this post, there is now one.
How do we normally upgrade a busy production server with minimal downtime? The simplest solution is to use a slave server with the newer version. Such a procedure has the side benefit of providing a “staging” database server which can be used to test the application with the new version. Basically we need to follow these steps:
If the new server was temporary, you’ll need to repeat most of the steps the other way around, this time starting from the new server and ending on the old one.
What we thought would be a simple task turned out to be much more complicated. We were preparing to upgrade our database from Amazon Aurora MySQL 5.6 to 5.7 when we discovered that there was no option for an in-place upgrade. Unlike a standard AWS RDS MySQL (RDS MySQL upgrade 5.6 to 5.7) at the time of this article you cannot perform an in-place upgrade or even restore a backup across the major versions of Amazon Aurora MySQL.
We initially chose Amazon Aurora for the benefits of the tuning work that AWS provided out of the box, but we realized with any set of pros there comes a list of cons. In this case, the limitations meant that something that should have been straightforward took us off the documented path.
Since we couldn’t use an RDS snapshot to provision a new Amazon Aurora MySQL 5.7 instance, we had to fallback to the use of a logical backup. The intended steps were:
Even those simple steps proved to be challenging.
First, the Amazon Aurora MySQL 5.6 write node must generate binary log files. The default cluster parameter group that is generated when creating an Amazon Aurora instance does not enable these settings. Our 5.6 write node was not generating binary log files, so we copied the default cluster parameter group to a new “replication” parameter group and changed the “binlog_format” variable to MIXED. The parameter is only effective after a reboot, so overnight we rebooted the node. That was a first short downtime.
At that point, we were able to confirm, using “show master status;” that the write node was indeed generating binlog files. Since our procedure involves a logical backup and restore, we had to make sure the binary log files are kept for a long enough time. With a regular MySQL server the variable “expire_logs_days” controls the binary log files retention time. With RDS, you have to use the mysql.rds_set_configuration. We set the retention time to two weeks:
|
1 |
CALL mysql.rds_set_configuration('binlog retention hours', 336); |
You can confirm the new setting is used with:
|
1 |
CALL mysql.rds_show_configuration; |
For the following step, we needed a mysqldump backup along with its consistent replication coordinates. The option --master-data of mysqldump implies “Flush table with read lock;” while the replication coordinates are read from the server. A “Flush table” requires the SUPER privilege and this privilege is not available in RDS.
Since we wanted to avoid downtime, it is out of question to pause the application for the time it would take to backup 100GB of data. The solution was to take a snapshot and use it to provision a temporary Amazon Aurora MySQL 5.6 cluster of one node. As part of the creation process, the events tab of the AWS console will show the binary log file and position consistent with the snapshot, it looks like this:
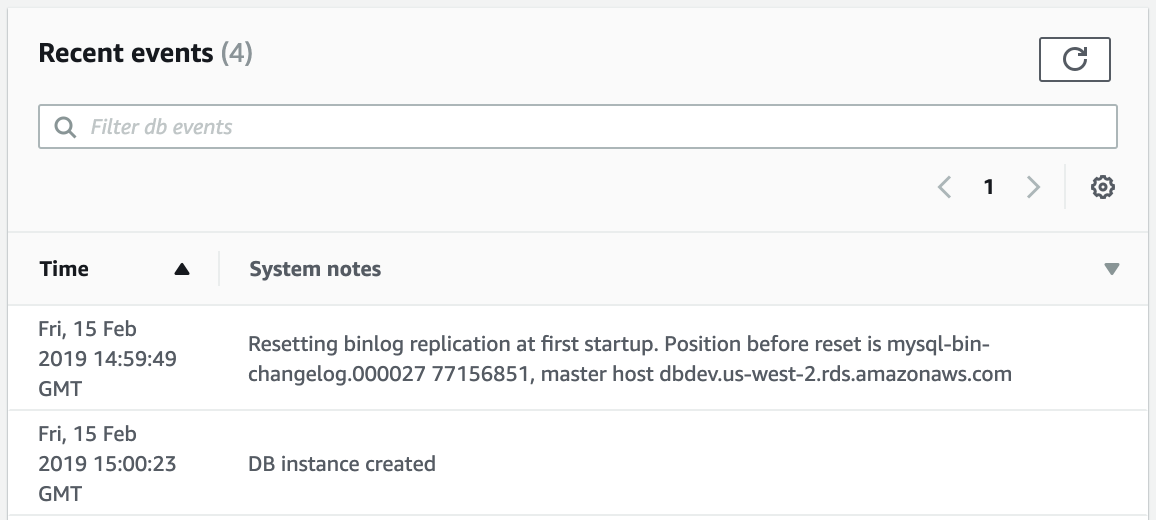
From there, the temporary cluster is idle so it is easy to back it up with mysqldump. Since our dataset is large we considered the use of MyDumper but the added complexity was not worthwhile for a one time operation. The dump of a large database can take many hours. Essentially we performed:
|
1 2 3 4 5 |
mysqldump -h entrypoint-temporary-cluster -u awsrootuser -pxxxx --no-data --single-transaction -R -E -B db1 db2 db3 > schema.sql mysqldump -h entrypoint-temporary-cluster -nt --single-transaction -u awsrootuser -pxxxx -B db1 db2 db3 | gzip -1 > dump.sql.gz pt-show-grants -h entrypoint-temporary-cluster -u awsrootuser -pxxxx > grants.sql |
The schema consist of three databases: db1, db2 and db3. We have not included the mysql schema because it will cause issues with the new 5.7 instance. You’ll see why we dumped the schema and the data separately in the next section.
With our backup done, we are ready to spin up a brand new Amazon Aurora MySQL 5.7 cluster and restore the backup. Make sure the new Amazon Aurora MySQL 5.7 cluster is in a subnet with access to the Amazon Aurora MySQL 5.6 production cluster. In our schema, there a few very large tables with a significant number of secondary keys. To speed up the restore, we removed the secondary indexes of these tables from the schema.sql file and created a restore-indexes.sql file with the list of alter table statements needed to recreate them. Then we restored the data using these steps:
|
1 2 3 4 |
cat grants.sql | mysql -h entrypoint-new-aurora-57 -u awsroot -pxxxx cat schema-modified.sql | mysql -h entrypoint-new-aurora-57 -u awsroot -pxxxx zcat dump.sql.gz | mysql -h entrypoint-new-aurora-57 -u awsroot -pxxxx cat restore-indexes.sql | mysql -h entrypoint-new-aurora-57 -u awsroot -pxxxx |
At this point, we have a new Amazon Aurora MySQL 5.7 cluster provisioned with a dataset at a known replication coordinates from the Amazon Aurora MySQL 5.6 production cluster. It is now very easy to setup replication. First we need to create a replication user in the Amazon Aurora MySQL 5.6 production cluster:
|
1 |
GRANT REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'repl_user'@'%' identified by 'agoodpassword'; |
Then, in the new Amazon Aurora MySQL 5.7 cluster, you configure replication and start it by:
|
1 2 3 |
CALL mysql.rds_set_external_master ('mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com', 3306, 'repl_user', 'agoodpassword', 'mysql-bin-changelog.000018', 65932380, 0); CALL mysql.rds_start_replication; |
The endpoint mydbcluster.cluster-123456789012.us-east-1.rds.amazonaws.com points to the Amazon Aurora MySQL 5.6 production cluster.
Now, if everything went well, the new Amazon Aurora MySQL 5.7 cluster will be actively syncing with its master, the current Amazon Aurora MySQL 5.6 production cluster. This process can take a significant amount of time depending on the write load and the type of instance used for the new cluster. You can monitor the progress with the show slave statusG command, the Seconds_Behind_Master will tell you how far behind in seconds the new cluster is compared to the old one. It is not a measurement of how long it will take to resync.
You can also monitor throughput using the AWS console. In this screenshot you can see the replication speeding up over time before it peaks when it is completed.
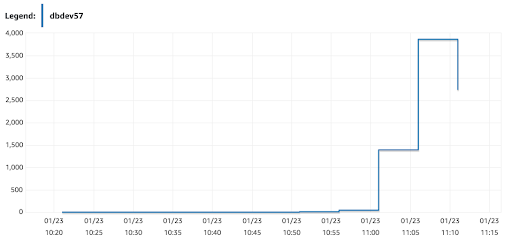
At this point, we have an Amazon Aurora MySQL 5.7 cluster in sync with the production Amazon Aurora MySQL 5.6 cluster. Before transferring the production load to the new cluster, you need to test your application with MySQL 5.7. The easiest way is to snapshot the new Amazon Aurora MySQL 5.7 cluster and, using the snapshot, provision a staging Amazon Aurora MySQL 5.7 cluster. Test your application against the staging cluster and, once tested, destroy the staging cluster and any unneeded snapshots.
Now that you have tested your application with the staging cluster and are satisfied how it behaves with Amazon Aurora MySQL 5.7, the very last step is to migrate the production load. Here are the last steps you need to follow:
Show master status; of the 5.6 cluster is no longer movingShow slave statusG in the 5.7 cluster the Master_Log_File and Exec_Master_Log_Pos match the output of the “Show master status;” from the 5.6 clusterCALL mysql.rds_stop_replication;CALL mysql.rds_reset_external_master;The application is down from steps 2 to 8. Although that might appear to be a long time, these steps can easily be executed within a few minutes.
So, in summary, although RDS Aurora doesn’t support an in place upgrade between Amazon Aurora MySQL 5.6 and 5.7, there is a possible migration path, minimizing downtime. In our case, we were able to limit the downtime to only a few minutes.

Jacques is CTO and co-founder at the fintech startup Fattmerchant, author of Time Hacks, and co-founder of the Orlando Devs, the largest developer meetup in Orlando. He has a passion for building products, bringing them to market, and scaling them.
Resources
RELATED POSTS





Thank you for the post. It’s a big effort to upgrade from 5.6 to 5.7 on Aurora. Would like to consider using Continuent Tungsten Clustering in AWS instead of Aurora. It’s quite easy to upgrade MySQL versions (5.6 to 5.7 or other versions) without taking down the Tungsten MySQL cluster. This is because the clustering software is designed to support mixing MySQL versions and allows various maintenance tasks to be performed without downtime.
The steps are quite simple:
1. Put cluster in maintenance mode
2. Shun (remove as a failover candidate) a slave
3. Upgrade MySQL on that slave (mysql binaries, mysql_upgrade script)
4. Recover the slave. Now replication happens from the MySQL 5.6 master to this MySQL 5.7 slave
5. Repeat steps 2-4 for remaining slaves.
6. Switch master to one of the upgraded slaves. Now master is MySQL 5.7, and old master is still 5.6, and replication is handled without issue
7. Perform steps 2-4 on old master.
8. Put cluster into automatic mode
9. Upgrade to MySQL 5.7 done.
No downtime!
Did you consider using
mysqldump --innodb-optimize-keysinstead of restore-indexes.sql?That’s only available with the Percona version of the client tools, the jumpbox was using the regular Community client.
Hi, I dont know if I just missed it out but,
Sorry, this is my question.
continuing it, did you use the binlog file and position in the “Logs & events” tab of the 5.6 db which you got when you created the snapshot? I got confused with the different value in the screenshot and the one you used in CALL mysql.rds_set_external_master
thanks!
I have the same question. Your screenshot says
mysql.bin.changelog.000027
whereas your CALL mysql.rds_set_external_master uses
mysql-bin-changelog.000018
Should those be the same? Thanks!
Yes, it is a copy/paste from different runs. The way it is currently, it is difficult to edit the post once published.
Please for me ask question.
When I create Amazon Aurora(MySQL5.7) I must create new [Cluter Parameter Group] and [DB Parameter Group] because Aurora(MySQL5.7) not support parameter of Aurora(MySQL5.6).
But I compared value paramater of Aurora(MySQL5.6) and Amazon Aurora(MySQL5.7) it is not same.
Example :
Num Parameter Name auroracluster5.7 auroracluster5.6
1 binlog_format OFF MIXED
2 character_set_client 0
3 character-set-client-handshake utf8
4 character_set_connection utf8
5 character_set_database utf8
6 character_set_filesystem binary
7 character_set_results utf8
8 character_set_server utf8
9 collation_connection utf8_general_ci
10 collation_server utf8_general_ci
I run command [SHOW VARIABLES;] and compare value Aurora(MySQL5.6) and Amazon Aurora(MySQL5.7)
have a lot of item not same. But variable is GLOBAL can not change value.
For exam I run [SET GLOBAL max_connections = 1000] throw error follow
# Time Action Message Duration / Fetch
0 1 15:27:00 SET GLOBAL max_connections = 1000 Error Code: 1227. Access denied; you need (at least one of) the SUPER privilege(s) for this operation 0.000 sec
If you have best solution upgrade Aurora(MySQL5.6) to Amazon Aurora(MySQL5.7) with same setting value in [Cluter Parameter Group] and [DB Parameter Group] please show me. Thanks you so much.
Sorry for the late answer, I missed your question. You don’t necessarily need the exact same configuration for an upgrade. Of course, in RDS you can’t do “set global…” since SUPER is not granted, you have to change the parameter group.
“The solution was to take a snapshot and use it to provision a temporary Amazon Aurora MySQL 5.6 cluster of one node. As part of the creation process, the events tab of the AWS console will show the binary log file and position consistent with the snapshot, it looks like this:”
I have followed these instructions twice, and in each case Recent Events only displayed “DB instance created” and nothing else. A colleague of mine agreed that Recent Events does not reliably display info related to binlog position.
The page below says, “You can also get the binlog file name and position by checking the MySQL error log for the last MySQL binlog file position or for the DB_CRASH_RECOVERY_BINLOG_POSITION entry.
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraMySQL.Replication.MySQL.html#AuroraMySQL.Replication.MySQL.CreateSnapshot
This was helpful for me. I found three entries similar to this in the first two log files created after the restore. (for example, in the file named error/mysql-error-running.log.2020-03-31.13)
2020-03-31 12:13:50 12937 [Note] Crash recovery finished.
InnoDB: Last MySQL binlog file position 0 1020, file name mysql-bin-changelog.023827
I hope this info might help others.
Excuse me, but what is the meaning of restoring the snapshot to a 5.6 cluster, to mysqldump and restore to another 5.7 cluster?
I tried to restore the 5.6 snapshot directly to a 5.7 cluster and set up the replication. It seems working.