
TiDB is an open-source distributed database developed by PingCAP. This is a very interesting project as it is can be used as a MySQL drop-in replacement: it implements MySQL protocol, and basically emulates MySQL. PingCAP defines TiDB is as a “one-stop data warehouse for both OLTP (Online Transactional Processing) and OLAP (Online Analytical Processing) workloads”. In this blog post I have decided to see how TiDB performs on a single server compared to MySQL for both OLTP and OLAP workload. Please note, this benchmark is very limited in scope: we are only testing TiDB and MySQL on a single server – TiDB is a distributed database out of the box.
Short version: TiDB supports parallel query execution for selects and can utilize many more CPU cores – MySQL is limited to a single CPU core for a single select query. For the higher-end hardware – ec2 instances in my case – TiDB can be 3-4 times faster for complex select queries (OLAP workload) which do not use, or benefit from, indexes. At the same time point selects and writes, especially inserts, can be 5x-10x slower. Again, please note that this test was on a single server, with a single TiKV process.
Please note: the following setup is only intended for testing and not for production.
I installed the latest version of TiDB to take advantage of the latest performance improvements, at the time of writing:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
cat make-full-tidb-server #!/bin/bash set -x cd /tidb wget http://download.pingcap.org/tidb-v2.1.2-linux-amd64.tar.gz tar -xzf tidb-*.tar.gz cd tidb-*-linux-amd64/ ./bin/pd-server --data-dir=pd --log-file=pd.log & sleep 5 ./bin/tikv-server --pd="127.0.0.1:2379" --data-dir=tikv -A 127.0.0.1:20165 --log-file=tikv.log & sleep 5 cd ~/go/src/github.com/pingcap/tidb make server ./bin/tidb-server --store=tikv --path="127.0.0.1:2379" |
The normal installation process is described here (different methods are available).
The main purpose of this test is to compare MySQL to TiDB. As with any distributed database it is hard to design an “apples to apples” comparison: we may compare a distributed workload spanning across many servers/nodes (in this case TiDB) to a single server workload (in this case MySQL). To overcome this challenge, I decided to focus on “efficiency”. If the distributed database is not efficient – i.e. it may require 10s or 100s of nodes to do the same job as the non-distributed database – it may be cost prohibitive to use such database for a small or medium size DB.
The preliminary results are: TiDB is much more efficient for SELECT (OLAP workload) but much less efficient for WRITES and typical OLTP workload. To overcome these limitations it is possible to use more servers.
For this test I was using two types of benchmarks:
Database size is 70Gb in MySQL and 30Gb in TiDB (compressed). The table has no secondary indexes (except the primary key).
I used the following four queries:
select count(*) from ontime;
select count(*), year from ontime group by year order by year;
select * from ontime where UniqueCarrier = 'DL' and TailNum = 'N317NB' and FlightNum = '2' and Origin = 'JFK' and Dest = 'FLL' limit 10;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
select SQL_CALC_FOUND_ROWS FlightDate, UniqueCarrier as carrier, FlightNum, Origin, Dest FROM ontime WHERE DestState not in ('AK', 'HI', 'PR', 'VI') and OriginState not in ('AK', 'HI', 'PR', 'VI') and flightdate > '2015-01-01' and ArrDelay < 15 and cancelled = 0 and Diverted = 0 and DivAirportLandings = '0' ORDER by DepDelay DESC LIMIT 10; |
I used five ec2 instances:
The following graph represents the results (bars represents the query response time, the smaller the better):
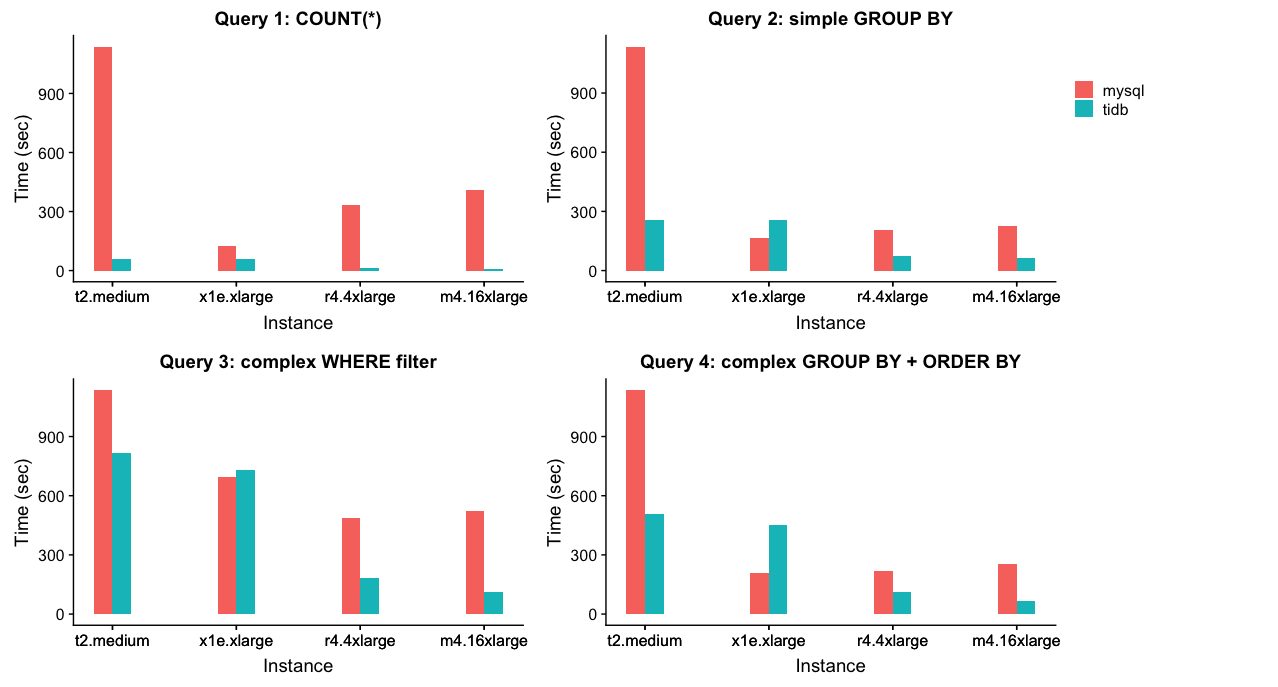
As we can see, TiDB scales very well increasing the number of CPU cores, as we go from lower to higher end instances. t2.medium and x1e.xlarge is interesting here thou:
All other instances have enough RAM to cache the database in memory, and with more CPU TiDB can take advantages of query parallelism and provide better response time.
Select test
I used point select (meaning select one row by primary key, threads ranges from 1 to 128) with Sysbench on an m4.16xlarge instance (memory bound: no disk reads). The results are here. The bars represent the number of transactions per second, the more the better:
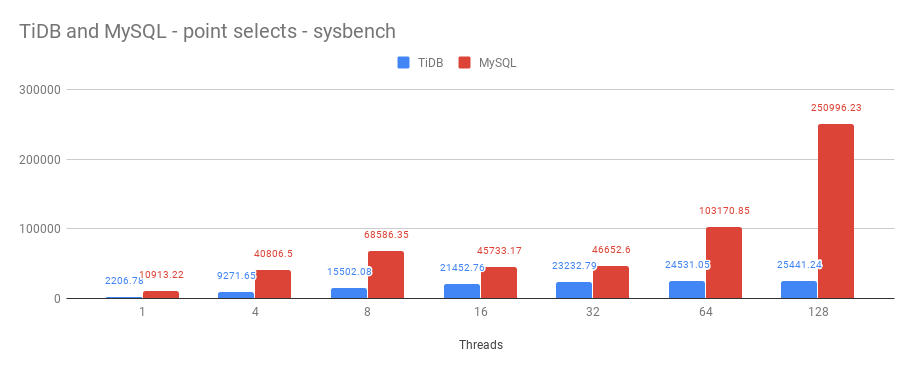 This workload is actually gives a great advantage to MySQL/InnoDB as it retrieves a single row based on the primary key. MySQL is significantly faster here: 5x to 10x faster. Unlike the previous workload – 1 single slow query – for “point select” queries MySQL scales much better than TiDB with more CPU cores.
This workload is actually gives a great advantage to MySQL/InnoDB as it retrieves a single row based on the primary key. MySQL is significantly faster here: 5x to 10x faster. Unlike the previous workload – 1 single slow query – for “point select” queries MySQL scales much better than TiDB with more CPU cores.
Write only test
I have used a write-only sysbench workload as well with threads ranging from 1 to 128. The instance has enough memory to cache full datast. Here are the results:
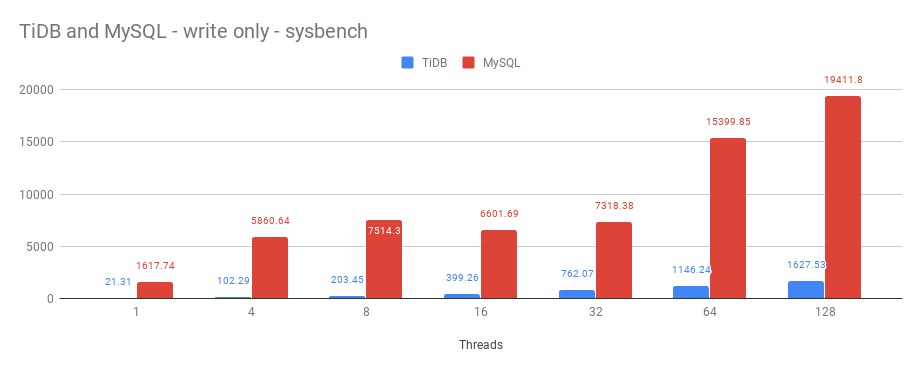 Here we can see that TiDB is also significatly slower than MySQL (for an in-memory workload).
Here we can see that TiDB is also significatly slower than MySQL (for an in-memory workload).
TiDB scales very well for OLAP / analytical queries (typically complex queries not able to take advantages of indexes) – this is the area where MySQL performs much worse as it does not take advantage of multiple CPU cores. At the same time, there is always a price to pay: TiDB has worse “efficiency” for fast queries (i.e. select by primary key) and writes. TiDB can scale across multiple servers (nodes). However, if we need to archive the same level of write efficiency as MySQL we will have to setup tens of nodes. In my opinion, TiDB can be a great fit for an analytical workload when you need almost full compatibility with MySQL: syntax compatibility, inserts/updates, etc.





Thank you for trying out TiDB! As you note, TiDB is well suited for analytics, but the performance numbers you experienced for the write-only test are lower than expected. This is great feedback, and something we are working on improving in our upcoming 3.0 release.
Hi Alexander,
Thanks for sharing this study! What version of MySQL where you using?
I find it a bit strange that MySQL will use more time for the simple count query on the larger machines than on x1e.xlarge. Why should the number of cores matter for single-thread executions? Do you have any explanation for that?
Also, it seems the group by queries uses less time that the simple count on these larger machines. That seems strange to me.
I’m interested about the results of PXC & MGR & TiDB on OLTP workload,such as sysbench oltp.
I think the result is misleading.
Some result is even contradict as Øystein Grøvlen pointed out.
What’s more, you don’t show the query execution plan. Maybe there is much room for MySQL to optimize.
TiDB is not suited for OLAP at all, they recommend TiSpark to query complex SQL instead.
As for OLTP, TiDB is no sense.
These benchmarks are interesting but they are kind of Apples to Oranges. That MySQL will win on any write heavy tasks is a sure thing, as both DBs are written with different designs. It will have been nice if you also included a replicated mysql cluster vs TiDB cluster in the results, to see a more real world view. Nobody in there right minds runs a single database instants ( unless you love the risk to lose data)? Another detail left out, … Databases like TiDB, CRDB are more tolerant to run on cheaper / lighter machines thanks to this build in default replication, where as your more or less forced to go with a very reliable ( aka expensive ) server, when faced with a single mysql instance. The lack of a downtime buffer is always present on a single instance mysql server.
shouldn’t be rocksdb vs tidb, instead of innodb vs tidb?
What I really miss from these kind of benchmarks are the real world situations. In the real world it’s uncommon to use a database for just inserting/reading some rows. You use a database at least for months, or maybe mor typically years.
It would be nice to have some benchmarks which take this into account: ie they run for months and show how badly these numbers age with that.