
It’s a few weeks after AWS re:Invent 2018 and my head is still spinning from all of the information released at this year’s conference. This year I was able to enjoy a few sessions focused on Aurora deep dives. In fact, I walked away from the conference realizing that my own understanding of High Availability (HA), Disaster Recovery (DR), and Durability in Aurora had been off for quite a while. Consequently, I decided to put this blog out there, both to collect the ideas in one place for myself, and to share them in general. Unlike some of our previous blogs, I’m not focused on analyzing Aurora performance or examining the architecture behind Aurora. Instead, I want to focus on how HA, DR, and Durability are defined and implemented within the Aurora ecosystem. We’ll get just deep enough into the weeds to be able to examine these capabilities alone.
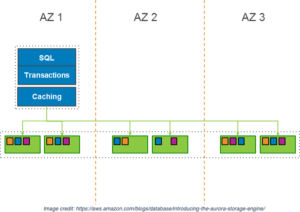
We’ll start with a simplified discussion of what Aurora is from a very high level. In its simplest description, Aurora MySQL is made up of a MySQL-compatible compute layer and a multi-AZ (multi availability zone) storage layer. In the context of an HA discussion, it is important to start at this level, so we understand the redundancy that is built into the platform versus what is optional, or configurable.
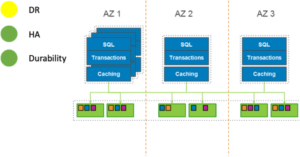
The Aurora Storage layer presents a volume to the compute layer. This volume is built out in 10GB increments called protection groups. Each protection group is built from six storage nodes, two from each of three availability zones (AZs). These are represented in the diagram above in green. When the compute layer—represented in blue—sends a write I/O to the storage layer, the data gets replicated six times across three AZs.
In addition to the six-way replication, Aurora employs a 4-of-6 quorum for all write operations. This means that for each commit that happens at the database compute layer, the database node waits until it receives write acknowledgment from at least four out of six storage nodes. By receiving acknowledgment from four storage nodes, we know that the write has been saved in at least two AZs. The storage layer itself has intelligence built-in to ensure that each of the six storage nodes has a copy of the data. This does not require any interaction with the compute tier. By ensuring that there are always at least four copies of data, across at least two datacenters (AZs), and ensuring that the storage nodes are self-healing and always maintain six copies, it can be said that the Aurora Storage platform has the characteristic of Durable by Default. The Aurora storage architecture is the same no matter how large or small your Aurora compute architecture is.
One might think that waiting to receive four acknowledgments represents a lot of I/O time and is therefore an expensive write operation. However, Aurora database nodes do not behave the way a typical MySQL database instance would. Some of the round-trip execution time is mitigated by the way in which Aurora MySQL nodes write transactions to disk. For more information on exactly how this works, check out Amazon Senior Engineering Manager, Kamal Gupta’s deep-dive into Aurora MySQL from AWS re:Invent 2018.
While durability can be said to be a default characteristic to the platform, HA and DR are configurable capabilities. Let’s take a look at some of the HA and DR options available. Aurora databases are deployed as members of an Aurora DB Cluster. The cluster configuration is fairly flexible. Database nodes are given the roles of either Writer or Reader. In most cases, there will only be one Writer node. The Reader nodes are known as Aurora Replicas. A single Aurora Cluster may contain up to 15 Aurora Replicas. We’ll discuss a few common configurations and the associated levels of HA and DR which they provide. This is only a sample of possible configurations: it is not meant to represent an exhaustive list of the possible configuration options available on the Aurora platform.
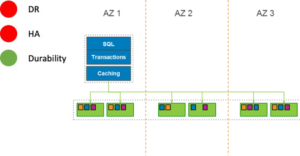
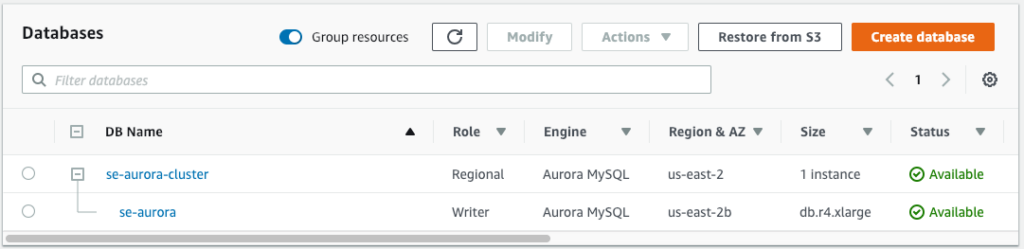
The most basic implementation of Aurora is a single compute instance in a single availability zone. The compute instance is monitored by the Aurora Cluster service and will be restarted if the database instance or compute VM has a failure. In this architecture, there is no redundancy at the compute level. Therefore, there is no database level HA or DR. The storage tier provides the same high level of durability described in the sections above. The image below is a view of what this configuration looks like in the AWS Console.
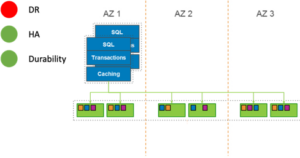 HA can be added to a basic Aurora implementation by adding an Aurora Replica. We increase our HA level by adding Aurora Replicas within the same AZ. If desired, the Aurora Replicas can be used to also service some of the read traffic for the Aurora Cluster. This configuration cannot be said to provide DR because there are no database nodes outside the single datacenter or AZ. If that datacenter were to fail, then database availability would be lost until it was manually restored in another datacenter (AZ). It’s important to note that while Aurora has a lot of built-in automation, you will only benefit from that automation if your base configuration facilitates a path for the automation to follow. If you have a single-AZ base deployment, then you will not have the benefit of automated Multi-AZ availability. However, as in the previous case, durability remains the same. Again, durability is a characteristic of the storage layer. The image below is a view of what this configuration looks like in the AWS Console. Note that the Writer and Reader are in the same AZ.
HA can be added to a basic Aurora implementation by adding an Aurora Replica. We increase our HA level by adding Aurora Replicas within the same AZ. If desired, the Aurora Replicas can be used to also service some of the read traffic for the Aurora Cluster. This configuration cannot be said to provide DR because there are no database nodes outside the single datacenter or AZ. If that datacenter were to fail, then database availability would be lost until it was manually restored in another datacenter (AZ). It’s important to note that while Aurora has a lot of built-in automation, you will only benefit from that automation if your base configuration facilitates a path for the automation to follow. If you have a single-AZ base deployment, then you will not have the benefit of automated Multi-AZ availability. However, as in the previous case, durability remains the same. Again, durability is a characteristic of the storage layer. The image below is a view of what this configuration looks like in the AWS Console. Note that the Writer and Reader are in the same AZ.
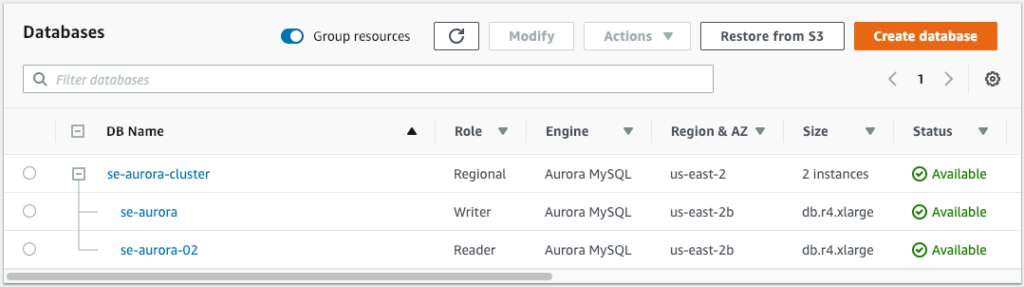
 Building on our previous example, we can increase our level of HA and add partial DR capabilities to the configuration by adding more Aurora Replicas. At this point we will add one additional replica in the same AZ, bringing the local AZ replica count to three database instances. We will also add one replica in each of the two remaining regional AZs. Aurora provides the option to configure automated failover priority for the Aurora Replicas. Choosing your failover priority is best defined by the individual business needs. That said, one way to define the priority might be to set the first failover to the local-AZ replicas, and subsequent failover priority to the replicas in the other AZs. It is important to remember that AZs within a region are physical datacenters located within the same metro area. This configuration will provide protection for a disaster localized to the datacenter. It will not, however, provide protection for a city-wide disaster. The image below is a view of what this configuration looks like in the AWS Console. Note that we now have two Readers in the same AZ as the Writer and two Readers in two other AZs.
Building on our previous example, we can increase our level of HA and add partial DR capabilities to the configuration by adding more Aurora Replicas. At this point we will add one additional replica in the same AZ, bringing the local AZ replica count to three database instances. We will also add one replica in each of the two remaining regional AZs. Aurora provides the option to configure automated failover priority for the Aurora Replicas. Choosing your failover priority is best defined by the individual business needs. That said, one way to define the priority might be to set the first failover to the local-AZ replicas, and subsequent failover priority to the replicas in the other AZs. It is important to remember that AZs within a region are physical datacenters located within the same metro area. This configuration will provide protection for a disaster localized to the datacenter. It will not, however, provide protection for a city-wide disaster. The image below is a view of what this configuration looks like in the AWS Console. Note that we now have two Readers in the same AZ as the Writer and two Readers in two other AZs.
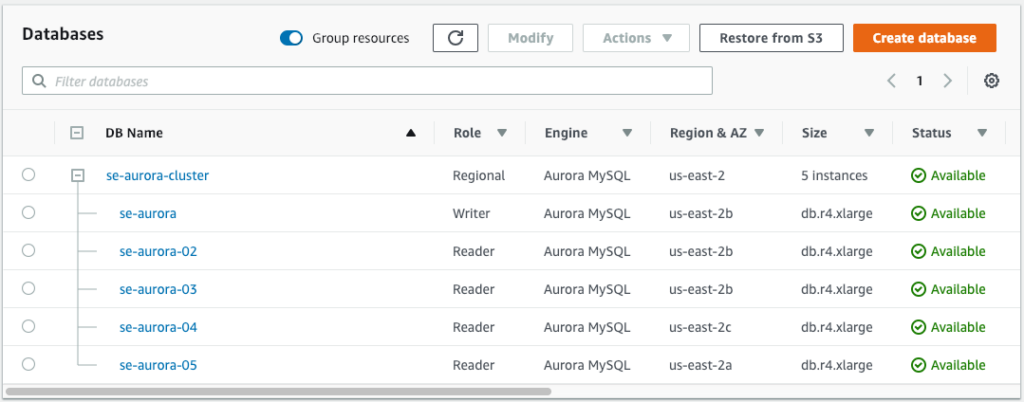
The three configuration types we’ve discussed up to this point represent configuration options available within an AZ or metro area. There are also options available for cross-region replication in the form of both logical and physical replication.
Aurora supports replication to up to five additional regions with logical replication. It is important to note that, depending on the workload, logical replication across regions can be notably susceptible to replication lag.
 One of the many announcements to come out of re:Invent 2018 is a product called Aurora Global Database. This is Aurora’s implementation of cross-region physical replication. Amazon’s published details on the solution indicate that it is storage level replication implemented on dedicated cross-region infrastructure with sub-second latency. In general terms, the idea behind a cross-region architecture is that the second region could be an exact duplicate of the primary region. This means that the primary region can have up to 15 Aurora Replicas and the secondary region can also have up to 15 Aurora Replicas. There is one database instance in the secondary region in the role of writer for that region. This instance can be configured to take over as the master for both regions in the case of a regional failure. In this scenario the secondary region becomes primary, and the writer in that region becomes the primary database writer. This configuration provides protection in the case of a regional disaster. It’s going to take some time to test this, but at the moment this architecture appears to provide the most comprehensive combination of Durability, HA, and DR. The trade-offs have yet to be thoroughly explored.
One of the many announcements to come out of re:Invent 2018 is a product called Aurora Global Database. This is Aurora’s implementation of cross-region physical replication. Amazon’s published details on the solution indicate that it is storage level replication implemented on dedicated cross-region infrastructure with sub-second latency. In general terms, the idea behind a cross-region architecture is that the second region could be an exact duplicate of the primary region. This means that the primary region can have up to 15 Aurora Replicas and the secondary region can also have up to 15 Aurora Replicas. There is one database instance in the secondary region in the role of writer for that region. This instance can be configured to take over as the master for both regions in the case of a regional failure. In this scenario the secondary region becomes primary, and the writer in that region becomes the primary database writer. This configuration provides protection in the case of a regional disaster. It’s going to take some time to test this, but at the moment this architecture appears to provide the most comprehensive combination of Durability, HA, and DR. The trade-offs have yet to be thoroughly explored.
Amazon is in the process of building out a new capability called Aurora Multi-Master. Currently, this feature is in preview phase and has not been released for general availability. While there were a lot of talks at re:Invent 2018 which highlighted some of the components of this feature, there is still no affirmative date for release. Early analysis points to the feature being localized to the AZ. It is not known if cross-region Multi-Master will be supported, but it seems unlikely.
As a post re:Invent takeaway, what I learned was that there is an Aurora configuration to fit almost any workload that requires strong performance behind it. Not all heavy workloads also demand HA and DR. If this describes one of your workloads, then there is an Aurora configuration that fits your needs. On the flip side, it is also important to remember that while data durability is an intrinsic quality of Aurora, HA and DR are not. These are completely configurable. This means that the Aurora architect in your organization must put thought and due diligence into the way they design your Aurora deployment. While we all need to be conscious of costs, don’t let cost consciousness become a blinder to reality. Just because your environment is running in Aurora does not mean you automatically have HA and DR for your database. In Aurora, HA and DR are configuration options, and just like the on-premise world, viable HA and DR have additional costs associated with them.
Resources
RELATED POSTS





Brian, this was an interesting article. Have you done any cost comparisions using EC2 instances and native MySQL, for example using r5.2xlarge or r5.4xlarge instances? How much extra does the Aurora add?
BTW, if there is need for cross-regional multi-master deployment, Continuent Tungsten would be an ideal solution. There was an interesting talk at Re:Invent by Tyler Turk of Riot Game to descibe how they created global backend for their 80 million League of Legends player accounts (https://www.youtube.com/watch?v=MJpZZm62ZKw).
Thanks Eero. Thanks for the comment. I have not done any comparison testing myself. One thing to note is that it is difficult to get apples-to-apples comparisons. This is due to the way Aurora writes transactions. It basically bypasses transactional logging. Therefore the I/O characteristics between Aurora and a DIY EC2 instance are going to be very dissimilar. This becomes significant when attempting to perform any sort of cost-per-performance analysis. If anyone is curious about how transactions are handled then I encourage taking a look at the deep dive session from re:Invent. It is very informative. https://www.youtube.com/watch?v=U42mC_iKSBg
Its really great site to visit, I really want to appropriate you for your great posting especially about AWS Aurora MySQL.
Great article Brian! Question about the Multi-AZ Options. Did you try this with r5 instances as well? For some reason it’s not working for us (tried with large and xlarge sizes). All Reader got created in the same AZ even if I explicitly select different zones.