
Over the last year, I have been pursuing a part time hobby project exploring ways to squeeze as much data as possible in MySQL. As you will see, there are quite a few different ways. Of course things like compression ratio matters a lot but, other items like performance of inserts, selects and updates, along with the total amount of bytes written are also important. When you start combining all the possibilities, you end up with a large set of compression options and, of course, I am surely missing a ton. This project has been a great learning opportunity and I hope you’ll enjoy reading about my results. Given the volume of results, I’ll have to write a series of posts. This post is the first of the series. I also have to mention that some of my work overlaps work done by one of my colleague, Yura Sorokin, in a presentation he did in Dublin.
You can also read part 2 of this series.
In many interesting cases, the ZFS experiments have been conducted with and without a SLOG.
In order to cover these solutions efficiently, I used a lot of automation and I restricted myself to two datasets. My first dataset consists of a set of nearly 1 billion rows from the Wikipedia access stats. The table schema is:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE `wiki_pagecounts` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `day` date NOT NULL, `hour` tinyint(4) NOT NULL, `project` varchar(30) NOT NULL, `title` text NOT NULL, `request` int(10) unsigned NOT NULL, `size` int(10) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `idx_time` (`day`,`hour`) ); |
and here’s a typical row:
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from wiki_pagecounts where id = 16G *************************** 1. row *************************** id: 16 day: 2016-01-01 hour: 0 project: aa title: 'File:Wiktionary-logo-en.png' request: 1 size: 10752 1 row in set (0.00 sec) |
The average length of the title columns is above 70 and it often has HTML escape sequences for UTF-8 characters in it. The actual column content is not really important but it is not random data. Loading this dataset in plain InnoDB results in a data file of about 113GB.
The second dataset is from the defunct Percona cloud tool project and is named “o1543”. Instead of a large number of rows, it is made of only 77M rows but this time, the table has 134 columns, mostly using float or bigint. The table definition is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE TABLE `query_class_metrics` ( `day` date NOT NULL, `query_class_id` int(10) unsigned NOT NULL, `instance_id` int(10) unsigned NOT NULL, `start_ts` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `end_ts` timestamp NOT NULL DEFAULT '1970-01-01 00:00:01', `query_count` bigint(20) unsigned NOT NULL, `lrq_count` bigint(20) unsigned NOT NULL DEFAULT '0', ... `Sort_scan_sum` bigint(20) unsigned DEFAULT NULL, `No_index_used_sum` bigint(20) unsigned DEFAULT NULL, `No_good_index_used_sum` bigint(20) unsigned DEFAULT NULL, PRIMARY KEY (`start_ts`,`instance_id`,`query_class_id`), KEY `start_ts` (`instance_id`) ); |
When loaded in plain InnoDB, the resulting data file size is slightly above 87GB.
The first test query is, of course, the inserts used to load the datasets. These are multi-inserts statements in primary key order generated by the mysqldump utility.
The second test query is a large range select. For the Wikipedia dataset I used:
|
1 2 3 4 |
select `day`, `hour`, max(request), sum(request), sum(size) from wikipedia_pagecounts.wiki_pagecounts where day = '2016-01-05' group by `day`,`hour`; |
while for the o1543 dataset, I used:
|
1 2 3 4 5 6 |
select query_class_id, sum(Query_time_sum) as Totat_time,sum(query_count), sum(Rows_examined_sum), sum(InnoDB_pages_distinct_sum) from o1543.query_class_metrics where start_ts between '2014-10-01 00:00:00' and '2015-06-30 00:00:00' group by query_class_id order by Totat_time desc limit 10; |
In both cases, a significant amount of data needs to be processed. Finally, I tested random access with the updates. I generated 20k distinct single row updates in random primary key order for the Wikipedia dataset like:
|
1 |
update wikipedia_pagecounts.wiki_pagecounts set request = request + 1 where id = 377748793; |
For the o1543 dataset, I used the following update statement:
|
1 2 |
update o1543.query_class_metrics set Errors_sum = Errors_sum + 1 where query_class_id = 472 and start_ts between '2014-10-01 00:00:00' and '2014-12-31 23:59:59'; |
which ends up updating very close to 20k rows, well spaced in term of primary key values.
In order to compare the compression options, I recorded key metrics.
/proc/$(pidof mysqld)/io./sys/block/$datadevice/stat. That matters a lot for flash devices that have a finite endurance. The amount of data written to the storage is the main motivation of Facebook with MyRocks.Even with these simple metrics, you’ll see there is quite a lot to discuss and learn.
For the benchmarks, I used a LXC virtual machine. My main goal was to simulate a dataset much larger than the available memory. I tried to limit the MySQL buffers to 128MB but in some cases, like with MyRocks, that was pretty unfair and it impacted the performance results. Basically, the procedure was:
du -hs the datadircat /proc/$(pidof mysqld)/iocat /sys/block/vdb/statdu -hs the datadircat /proc/$(pidof mysqld)/iocat /sys/block/vdb/statAs much as possible, I automated the whole procedure. On many occasions, I ran multiple runs of the same benchmark to validate unexpected behaviors.
In this first post of the series, I’ll report on the traditional “built-in” options which are InnoDB with Barracuda compression (IBC) and MyISAM with packing. I debated a bit the inclusion of MyISAM in this post since tables become read-only once packed but still, I personally implemented solutions using MyISAM packed a few times.
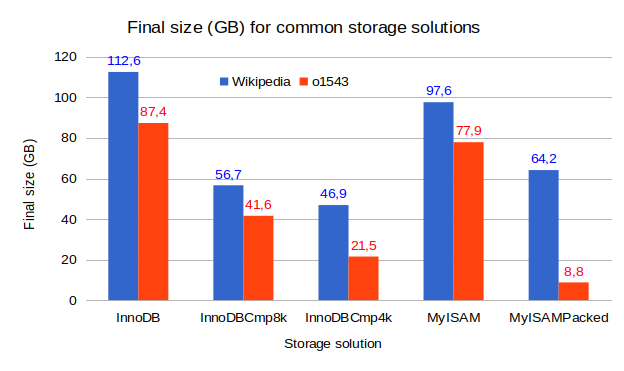
On the first figure (above), we have the final table sizes in GB for the different options we are considering in this first round of results. Over all the post series, we’ll use the plain InnoDB results as a reference. The Wikipedia dataset has a final size in InnoDB of 112.6GB while the o1543 dataset is slightly smaller, at 87.4GB.
The MyISAM sizes are smaller by 10 to 15% which is expected since InnoDB is page based, with page and row headers, and it doesn’t fully pack its pages. The InnoDB dataset size could have been up to twice as large if the data was inserted in random order of the primary key.
Adding Barracuda page compression with an 8KB block size (InnoDBCmp8k), both datasets shrink by close to 50%. Pushing to a block size of 4KB (InnoDBCmp4k), the Wikipedia dataset clearly doesn’t compress that much but, the o1543 dataset is very compressible, by more than 75%. Looking at the MyISAM Packed results, the o1543 dataset compressed to only 8.8GB, a mere 11% of the original MyISAM size. That means the o1543 could have done well with IBC using block size of 2KB. Such a compression ratio is really exceptional. I’ve rarely encountered a ratio that favorable in a production database.
With IBC, we know when the block size is too small for the compressibility of the dataset when the final size is no longer following the ratio of compressed block size over the original block size. For example, the Wikipedia dataset started at 112.6GB and a fourth (4KB/16KB) of this number is much smaller than the 46.9GB size of the InnoDB compression with 4k block size. You’ll also see a large number of compression failure in the innodb_cmp table of the information schema.
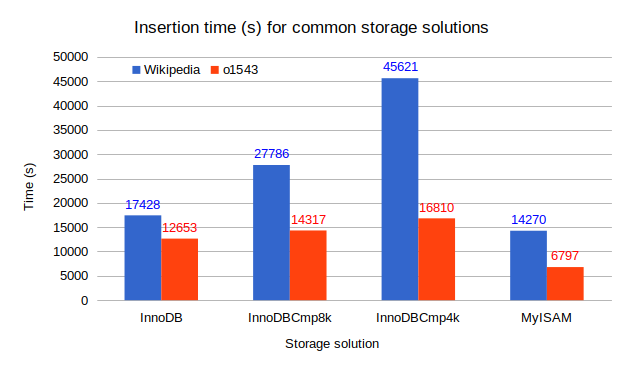
When the compression fails with IBC, InnoDB splits the page in two and recompresses each half. That process adds an overhead which can observed in the insertion time figure. While the insertion time of the Wikipedia dataset for the InnoDBCmp4k explodes to 2.6 times the uncompressed insertion time, the o1543 dataset takes only 30% more time. I suggest you do not take the times here too formally, the test environment I used was not fully isolated. View these times as trends.
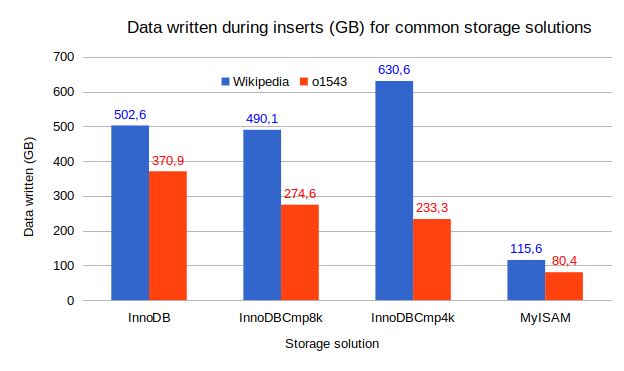
The amount of data written during the inserts, shown on the above figure, has bugged me for a while. Let’s consider, for example, the amount of writes needed to insert all the rows of the Wikipedia dataset in plain InnoDB. The total is 503GB for a dataset of 113GB. From the MySQL status variables, I have 114GB written to the data files (innodb_pages_written * 16kb), 114GB written to the double write buffer (Inndb_dblwr_pages_written * 16kb) and 160GB written to the InnoDB log files (innodb_os_log_written). If you sum all these values, you have about 388GB, a value short by about… 114GB, too close to the size of the dataset to be an accident. What else is written?
After some research, I finally found it! When a datafile is extended, InnoDB first writes zeros to allocate the space on disk. All the tablespaces have to go through that initial allocation phase so here are the missing 114GB.
Back to the data written during the inserts figure, look at the number of writes required for the Wikipedia dataset when using InnoDBCmp4k. Any idea why it is higher? What if I tell you the double write buffer only writes 16KB pages (actually, it depends on innodb_page_size)? So, when the pages are compressed, they are padded with zeros when written to the double write buffer. We remember that, when compressing to 4KB, we had many compression misses so we ended up with many more pages to write. Actually, Domas Mituzas filed a bug back in 2013 about this. Also, by default (innodb_log_compressed_pages), the compressed and uncompressed versions of the pages are written to the InnoDB log files. Actually, only the writes to the tablespace are reduced by IBC.
MyISAM, since it is not a transactional engine, cheats here. The only overhead are the writes to the b-trees of the index. So, to the expense of durability, MyISAM writes much less data in this simple benchmark.
So great, we have now inserted a lot of rows in our tables. How fast can we access these rows? The following figure presents the times to perform large range scans on the datasets. In InnoDB, the times are “fairly” stable. For the Wikipedia dataset, InnoDB compression improves the select performance, the time to decompress a page is apparently shorter than the time to read a full page. MyISAM without compression is the fastest solution but, once again, the benchmark offers the most favorable conditions to MyISAM. MyISAMPacked doesn’t fare as well for the large range select, likely too much data must be decompressed.

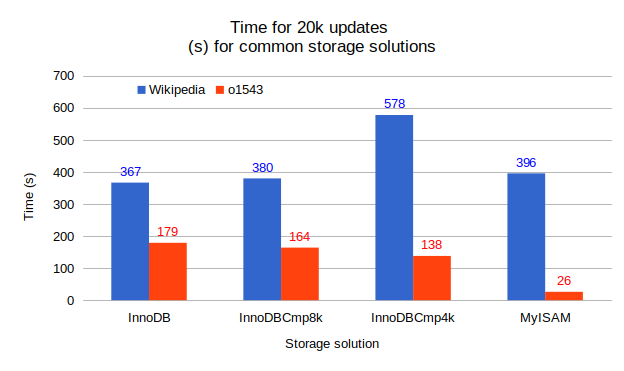
Going to the updates, the time required to perform 20k updates by a single thread is shown on the above figure. For both datasets, InnoDB and InnoDBCmp8k show similar times. There is a divergence with Wikipedia dataset stored on InnoDBCmp4k, the execution time is 57% larger, essentially caused by a large increase in the number of pages read. MyISAM is extremely efficient dealing with the updates of the o1543 dataset since the record size is fixed and the update process is single-threaded.
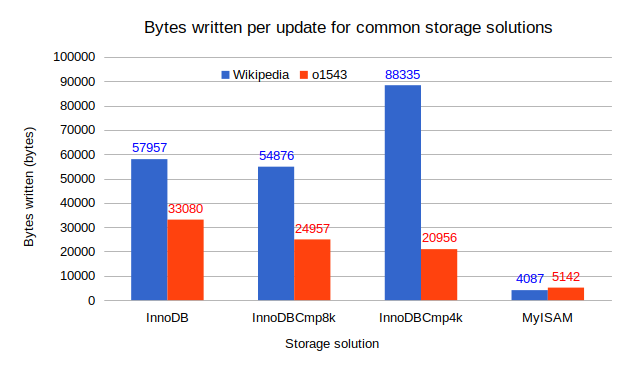
Finally, let’s examine the number of bytes written per updates as shown on the figure above. I was naively expecting about two pages written per update statement, one for the double write buffer and one for the tablespace file. The Wikipedia dataset shows more like three pages written per update while the o1543 dataset fits rather well with what I was expecting. I had to look at the file_summary_by_instance table of the Performance schema and the innodb_metrics table to understand. Actually, my updates to the Wikipedia dataset are single row updates executed in autocommit mode, while the updates to the o1543 dataset are from a single statement updating 20k rows. When you do multiple small transactions, you end up writing much more to the undo log and to the system tablespace. The worse case is when the updates are in separate transactions and a long time is allowed for MySQL to flush the dirty pages.
Here are the writes associated with 30 updates, in autocommit mode, 20s apart:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> select NAME, COUNT_RESET from innodb_metrics where name like '%writt%' and count_reset > 0 ; +---------------------------------+-------------+ | NAME | COUNT_RESET | +---------------------------------+-------------+ | buffer_pages_written | 120 | | buffer_data_written | 2075136 | | buffer_page_written_index_leaf | 30 | | buffer_page_written_undo_log | 30 | | buffer_page_written_system_page | 30 | | buffer_page_written_trx_system | 30 | | os_log_bytes_written | 77312 | | innodb_dblwr_pages_written | 120 | +---------------------------------+-------------+ 8 rows in set (0.01 sec) |
The index leaf write is where the row is stored in the tablespace, 30 matches the number of rows updated. Each update has dirtied one leaf page as expected. The undo log is used to store the previous version of the row for rollback, in the ibdata1 file. I wrongly assumed these undo entries would not be actually written to disk, and would only live in the buffer pool and purged before they needed to be flushed to disk. I don’t clearly enough understand what is written to the system page and trx system to attempt a clear explanation for these ones. The sum of pages to write is 120, four per update but you need to multiply by two because of the double write buffer. So, in this worse case scenario, a simple single row update may cause up to eight pages to be written to disk.
Grouping the updates in a single transaction basically removes the pages written to the system_page and trx_system as these are per transaction.
Here is the result for the same 30 updates, send at a 20s interval, but this time in a single transaction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> select NAME, COUNT_RESET from innodb_metrics where name like '%writt%' and count_reset > 0 ; +---------------------------------+-------------+ | NAME | COUNT_RESET | +---------------------------------+-------------+ | buffer_pages_written | 63 | | buffer_data_written | 1124352 | | buffer_page_written_index_leaf | 30 | | buffer_page_written_undo_log | 31 | | buffer_page_written_system_page | 1 | | buffer_page_written_trx_system | 1 | | os_log_bytes_written | 60928 | | innodb_dblwr_pages_written | 63 | +---------------------------------+-------------+ |
The write load, in terms of the number of pages written, is cut by half, to four per update. The most favorable case will be a single transaction with no sleep in between.
For 30 updates in a single transaction with no sleep, the results are:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> select NAME, COUNT_RESET from innodb_metrics where name like '%writt%' and count_reset > 0 ; +---------------------------------+-------------+ | NAME | COUNT_RESET | +---------------------------------+-------------+ | buffer_pages_written | 33 | | buffer_data_written | 546304 | | buffer_page_written_index_leaf | 30 | | buffer_page_written_undo_log | 1 | | buffer_page_written_system_page | 1 | | buffer_page_written_trx_system | 1 | | os_log_bytes_written | 4608 | | innodb_dblwr_pages_written | 33 | +---------------------------------+-------------+ 8 rows in set (0.00 sec) |
Now, the undo log is flushed only once and we are down to approximately two page writes per update. This is what I was originally expecting. The other results falls well into place if you keep in mind that only the index_leaf writes are compressed. The InnoDBCmp4k results for the Wikipedia dataset are higher, essentially because it took much more time and thus more page flushing occurred.
Everything can be a pretext to explore and learn. Just to summarize, what have we learned in this post?
Not bad in term of collateral learning…
In this post, we reviewed the traditional data compression solutions available with MySQL. In future posts, we’ll start looking at the alternatives. In the next one, I will evaluate InnoDB Transparent page compression with punch hole, a feature available since MySQL 5.7.





cool article!
Waiting for the second part!