
Starting with PMM 1.13, PMM uses Prometheus 2 for metrics storage, which tends to be heaviest resource consumer of CPU and RAM. With Prometheus 2 Performance Improvements, PMM can scale to more than 1000 monitored nodes per instance in default configuration. In this blog post we will look into PMM scaling and capacity planning—how to estimate the resources required, and what drives resource consumption.
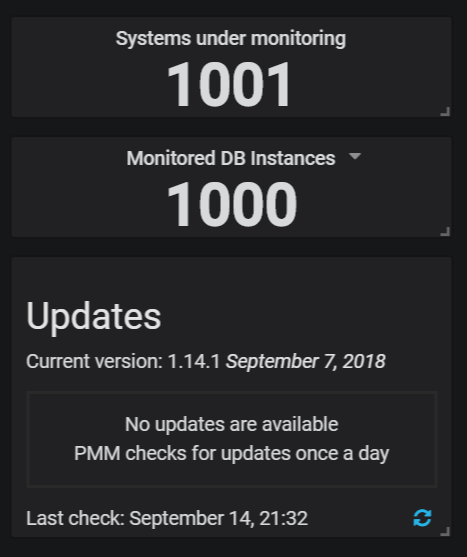
We have now tested PMM with up to 1000 nodes, using a virtualized system with 128GB of memory, 24 virtual cores, and SSD storage. We found PMM scales pretty linearly with the available memory and CPU cores, and we believe that a higher number of nodes could be supported with more powerful hardware.
Depending on your system configuration and workload, a single node can generate very different loads on the PMM server. The main factors that impact the performance of PMM are:
These specifically can be impacted by:
All these factors together may impact resource requirements by a factor of ten or more, so do your own testing to be sure. However, the numbers in this article should serve as good general guidance as a start point for your research.
On the system supporting 1000 instances we observed the following performance:

As you can see, we have more than 2.000 scrapes/sec performed, providing almost two million samples/sec, and more than eight million active time series. These are the main numbers that define the load placed on Prometheus.
Both CPU and memory are very important resources for PMM capacity planning. Memory is the more important as Prometheus 2 does not have good options for limiting memory consumption. If you do not have enough memory to handle your workload, then it will run out of memory and crash.
We recommend at least 2GB of memory for a production PMM Installation. A test installation with 1GB of memory is possible. However, it may not be able to monitor more than one or two nodes without running out of memory. With 2GB of memory you should be able to monitor at least five nodes without problem.
With powerful systems (8GB of more) you can have approximately eight systems per 1GB of memory, or about 15,000 samples ingested/sec per 1GB of memory.
To calculate the CPU usage resources required, allow for about 50 monitored systems per core (or 100K metrics/sec per CPU core).
One problem you’re likely to encounter if you’re running PMM with 100+ instances is the “Home Dashboard”. This becomes way too heavy with such a large number of servers. We plan to fix this issue in future releases of PMM, but for now you can work around it in two simple ways:
You can select the host, for example “pmm-server” in your home dashboard and save it, before adding a large amount of hosts to the system.
Or you can make some other dashboard of your choice and set it as the home dashboard.





Hi Peter, nice post!
You’ve tested monitoring a mix of Percona Server, RDS, XtraDB Cluster, etc or this tests was based just with a kind of database instance ?
This particular test was done on Percona Server 5.7 with recommended settings. You should have similar capacity with Percona XtraDB Cluster. RDS uses agent-less monitoring which places more load on the PMM Server though I know of installations having hundreds of Amazon Aurora instances monitored by single PMM server
If pmm does the alarm function, it will be even more powerful. Otherwise, we have to establish a separate monitoring system to make an alarm.(google translate)
Thank you for your feedback. At this point you can use Grafana Alerting with PMM which I admit is pretty basic. In the future versions we plan to simplify integration with Prometheus Alertmanager for more advanced Alerting functionality.
I’m very impressed with this article it’s very helpful! Thank you, Peter.