
The choice of good InnoDB primary keys is a critical performance tuning decision. This post will guide you through the steps of choosing the best primary key depending on your workload.
As a principal architect at Percona, one of my main duties is to tune customer databases. There are many aspects related to performance tuning which make the job complex and very interesting. In this post, I want to discuss one of the most important one: the choice of good InnoDB primary keys. You would be surprised how many times I had to explain the importance of primary keys and how many debates I had around the topic as often people have preconceived ideas that translate into doing things a certain way without further thinking.
The choice of a good primary key for an InnoDB table is extremely important and can have huge performance impacts. When you start working with a customer using an overloaded x1.16xlarge RDS instance, with close to 1TB of RAM, and after putting a new primary in place they end up doing very well with a r4.4xlarge instance — it’s a huge impact. Of course, it is not a silver bullet –, you need to have a workload like the ones I’ll highlight in the following sections. Keep in mind that tuning comes with trade-offs, especially with the primary key. What you gain somewhere, you have to pay for, performance-wise, elsewhere. You need to calculate what is best for your workload.
InnoDB is called an index-organized storage engine. An index-organized storage engine uses the B-Tree of the primary key to stores the data, the table rows. That means a primary key is mandatory with InnoDB. If there is no primary key for a table, InnoDB adds a hidden auto-incremented 6 bytes counter to the table and use that hidden counter as the primary key. There are some issues with the InnoDB hidden primary key. You should always define explicit primary keys on your tables. In summary, you access all InnoDB rows by the primary key values.
An InnoDB secondary index is also a B-Tree. The search key is made of the index columns and the values stored are the primary keys of matching rows. A search by a secondary index very often results in an implicit search by primary key. You can find more information about InnoDB file format in the documentation. Jeremy Cole’s InnoDB Ruby tools are also a great way to learn about InnoDB internals.
A B-Tree is a data structure optimized for operations on block devices. Block devices, or disks, have a rather important data access latency, especially spinning disks. Retrieving a single byte at a random position doesn’t take much less time than retrieving a bigger piece of data like a 8KB or 16KB object. That’s the fundamental argument for B-Trees. InnoDB uses pieces of data — pages — of 16KB.
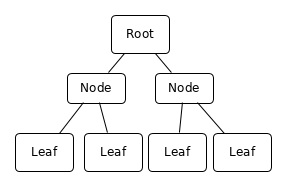
Let’s attempt a simplified description of a B-Tree. A B-Tree is a data structure organized around a key. The key is used to search the data inside the B-Tree. A B-Tree normally has multiple levels. The data is stored only in the bottom-most level, the leaves. The pages of the other levels, the nodes, only contains keys and pointers to pages in the next lower level.
When you want to access a piece of data for a given value of the key, you start from the top node, the root node, compare the keys it contains with the search value and finds the page to access at the next level. The process is repeated until you reach the last level, the leaves. In theory, you need one disk read operation per level of the B-Tree. In practice there is always a memory cache and the nodes, since they are less numerous and accessed often, are easy to cache.
Let’s consider the following sysbench table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
mysql> show create table sbtest1G *************************** 1. row *************************** Table: sbtest1 Create Table: CREATE TABLE `sbtest1` ( `id` int(11) NOT NULL AUTO_INCREMENT, `k` int(11) NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', PRIMARY KEY (`id`), KEY `k_1` (`k`) ) ENGINE=InnoDB AUTO_INCREMENT=3000001 DEFAULT CHARSET=latin1 1 row in set (0.00 sec) mysql> show table status like 'sbtest1'G *************************** 1. row *************************** Name: sbtest1 Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 2882954 Avg_row_length: 234 Data_length: 675282944 Max_data_length: 0 Index_length: 47775744 Data_free: 3145728 Auto_increment: 3000001 Create_time: 2018-07-13 18:27:09 Update_time: NULL Check_time: NULL Collation: latin1_swedish_ci Checksum: NULL Create_options: Comment: 1 row in set (0.00 sec) |
The primary key B-Tree size is Data_length. There is one secondary key B-Tree, the k_1 index, and its size is given by Index_length. The sysbench table was inserted in order of the primary key since the id column is auto-incremented. When you insert in order of the primary key, InnoDB fills its pages with up to 15KB of data (out of 16KB), even when innodb_fill_factor is set to 100. That allows for some row expansion by updates after the initial insert before a page needs to be split. There are also some headers and footers in the pages. If a page is too full and cannot accommodate an update adding more data, the page is split into two. Similarly, if two neighbor pages are less than 50% full, InnoDB will merge them. Here is, for example, a sysbench table inserted in id order:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
mysql> select count(*), TABLE_NAME,INDEX_NAME, avg(NUMBER_RECORDS), avg(DATA_SIZE) from information_schema.INNODB_BUFFER_PAGE -> WHERE TABLE_NAME='`sbtest`.`sbtest1`' group by TABLE_NAME,INDEX_NAME order by count(*) desc; +----------+--------------------+------------+---------------------+----------------+ | count(*) | TABLE_NAME | INDEX_NAME | avg(NUMBER_RECORDS) | avg(DATA_SIZE) | +----------+--------------------+------------+---------------------+----------------+ | 13643 | `sbtest`.`sbtest1` | PRIMARY | 75.0709 | 15035.8929 | | 44 | `sbtest`.`sbtest1` | k_1 | 1150.3864 | 15182.0227 | +----------+--------------------+------------+---------------------+----------------+ 2 rows in set (0.09 sec) mysql> select PAGE_NUMBER,NUMBER_RECORDS,DATA_SIZE,INDEX_NAME,TABLE_NAME from information_schema.INNODB_BUFFER_PAGE -> WHERE TABLE_NAME='`sbtest`.`sbtest1`' order by PAGE_NUMBER limit 1; +-------------+----------------+-----------+------------+--------------------+ | PAGE_NUMBER | NUMBER_RECORDS | DATA_SIZE | INDEX_NAME | TABLE_NAME | +-------------+----------------+-----------+------------+--------------------+ | 3 | 35 | 455 | PRIMARY | `sbtest`.`sbtest1` | +-------------+----------------+-----------+------------+--------------------+ 1 row in set (0.04 sec) mysql> select PAGE_NUMBER,NUMBER_RECORDS,DATA_SIZE,INDEX_NAME,TABLE_NAME from information_schema.INNODB_BUFFER_PAGE -> WHERE TABLE_NAME='`sbtest`.`sbtest1`' order by NUMBER_RECORDS desc limit 3; +-------------+----------------+-----------+------------+--------------------+ | PAGE_NUMBER | NUMBER_RECORDS | DATA_SIZE | INDEX_NAME | TABLE_NAME | +-------------+----------------+-----------+------------+--------------------+ | 39 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` | | 61 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` | | 37 | 1203 | 15639 | PRIMARY | `sbtest`.`sbtest1` | +-------------+----------------+-----------+------------+--------------------+ 3 rows in set (0.03 sec) |
The table doesn’t fit in the buffer pool, but the queries give us good insights. The pages of the primary key B-Tree have on average 75 records and store a bit less than 15KB of data. The index k_1 is inserted in random order by sysbench. Why is the filling factor so good? It’s simply because sysbench creates the index after the rows have been inserted and InnoDB uses a sort file to create it.
You can easily estimate the number of levels in an InnoDB B-Tree. The above table needs about 40k leaf pages (3M/75). Each node page holds about 1200 pointers when the primary key is a four bytes integer. The level above the leaves thus has approximately 35 pages and then, on top of the B-Tree is the root node (PAGE_NUMBER = 3). We have a total of three levels.
If you are a keen observer, you realized a direct consequence of inserting in random order of the primary key. The pages are often split, and on average the filling factor is only around 65-75%. You can easily see the filling factor from the information schema. I modified sysbench to insert in random order of id and created a table, also with 3M rows. The resulting table is much larger:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
mysql> show table status like 'sbtest1'G *************************** 1. row *************************** Name: sbtest1 Engine: InnoDB Version: 10 Row_format: Dynamic Rows: 3137367 Avg_row_length: 346 Data_length: 1088405504 Max_data_length: 0 Index_length: 47775744 Data_free: 15728640 Auto_increment: NULL Create_time: 2018-07-19 19:10:36 Update_time: 2018-07-19 19:09:01 Check_time: NULL Collation: latin1_swedish_ci Checksum: NULL Create_options: Comment: 1 row in set (0.00 sec) |
While the size of the primary key b-tree inserted in order of id is 644MB, the size, inserted in random order, is about 1GB, 60% larger. Obviously, we have a lower page filling factor:
|
1 2 3 4 5 6 7 8 9 |
mysql> select count(*), TABLE_NAME,INDEX_NAME, avg(NUMBER_RECORDS), avg(DATA_SIZE) from information_schema.INNODB_BUFFER_PAGE -> WHERE TABLE_NAME='`sbtestrandom`.`sbtest1`'group by TABLE_NAME,INDEX_NAME order by count(*) desc; +----------+--------------------------+------------+---------------------+----------------+ | count(*) | TABLE_NAME | INDEX_NAME | avg(NUMBER_RECORDS) | avg(DATA_SIZE) | +----------+--------------------------+------------+---------------------+----------------+ | 4022 | `sbtestrandom`.`sbtest1` | PRIMARY | 66.4441 | 10901.5962 | | 2499 | `sbtestrandom`.`sbtest1` | k_1 | 1201.5702 | 15624.4146 | +----------+--------------------------+------------+---------------------+----------------+ 2 rows in set (0.06 sec) |
The primary key pages are now filled with only about 10KB of data (~66%). It is a normal and expected consequence of inserting rows in random order. We’ll see that for some workloads, it is bad. For some others, it is a small price to pay.
It is always good to have a concrete model or analogy in your mind to better understand what is going on. Let’s assume you have been tasked to write the names and arrival time, on paper, of all the attendees arriving at a large event like Percona Live. So, you sit at a table close to the entry with a good pen and a pile of sheets of paper. As people arrive, you write their names and arrival time, one after the other. When a sheet is full, after about 40 names, you move it aside and start writing to a new one. That’s fast and effective. You handle a sheet only once, and when it is full, you don’t touch it anymore. The analogy is easy, a sheet of paper represents an InnoDB page.
The above use case represents an ordered insert. It is very efficient for the writes. Your only issue is with the organizer of the event: she keeps coming to you asking if “Mr. X” or “Mrs. Y” has arrived. You have to scan through your sheets to find the name. That’s the drawback of ordered inserts, reads can be more expensive. Not all reads are expensive, some can be very cheap. For example: “Who were the first ten people to get in?” is super easy. You’ll want an ordered insert strategy when the critical aspects of the application are the rate and the latency of the inserts. That usually means the reads are not user-facing. They are coming from report batch jobs, and as long as these jobs complete in a reasonable time, you don’t really care.
Now, let’s consider a random insertion analogy. For the next day of the event, tired of the organizer questions, you decide on a new strategy: you’ll write the names grouped by the first letter of the last name. Your goal is to ease the searches by name. So you take 26 sheets, and on top of each one, you write a different letter. As the first visitors arrive, you quickly realize you are now spending a lot more time looking for the right sheet in the stack and putting it back at the right place once you added a name to it.
At the end of the morning, you have worked much more. You also have more sheets than the previous day since for some letters there are few names while for others you needed more than a sheet. Finding names is much easier though. The main drawback of random insertion order is the overhead to manage the database pages when adding entries. The database will read and write from/to disk much more and the dataset size is larger.
The first step is to determine what kind of workload you have. When you have an insert-intensive workload, very likely, the top queries are inserts on some large tables and the database heavily writes to disk. If you repeatedly execute “show processlist;” in the MySQL client, you see these inserts very often. That’s typical of applications logging a lot of data. There are many data collectors and they all wait to insert data. If they wait for too long, some data may be lost. If you have strict SLA on the insert time and relaxed ones on the read time, you clearly have an insert oriented workload and you should insert rows in order of the primary key.
You may also have a decent insert rate on large tables but these inserts are queued and executed by batch processes. Nobody is really waiting for these inserts to complete and the server can easily keep up with the number of inserts. What matters for your application is the large number of read queries going to the large tables, not the inserts. You already went through query tuning and even though you have good indexes, the database is reading from disk at a very high rate.
When you look at the MySQL processlist, you see many times the same select query forms on the large tables. The only options seem to be adding more memory to lower the disk reads, but the tables are growing fast and you can’t add memory forever. We’ll discuss the read-intensive workload in details in the next section.
If you couldn’t figure if you have an insert-heavy or read-heavy workload, maybe you just don’t have a big workload. In such a case, the default would be to use ordered inserts, and the best way to achieve this with MySQL is through an auto-increment integer primary key. That’s the default behavior of many ORMs.
I have seen quite a few read-intensive workloads over my consulting years, mostly with online games and social networking applications. On top of that, some games have social networking features like watching the scores of your friends as they progress through the game. Before we go further, we first need to confirm the reads are inefficient. When reads are inefficient, the top select query forms will the accessing a number of distinct InnoDB pages close to the number of rows examined. The Percona Server for MySQL slow log, when the verbosity level includes “InnoDB”, exposes both quantities, and the pt-query-digest tool includes stats on them. Here’s an example output (I’ve removed some lines):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# Query 1: 2.62 QPS, 0.00x concurrency, ID 0x019AC6AF303E539E758259537C5258A2 at byte 19976 # This item is included in the report because it matches --limit. # Scores: V/M = 0.00 # Time range: 2018-07-19T20:28:02 to 2018-07-19T20:28:23 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 48 55 # Exec time 76 93ms 637us 3ms 2ms 2ms 458us 2ms # Lock time 100 10ms 72us 297us 182us 247us 47us 176us # Rows sent 100 1.34k 16 36 25.04 31.70 4.22 24.84 # Rows examine 100 1.34k 16 36 25.04 31.70 4.22 24.84 # Rows affecte 0 0 0 0 0 0 0 0 # InnoDB: # IO r bytes 0 0 0 0 0 0 0 0 # IO r ops 0 0 0 0 0 0 0 0 # IO r wait 0 0 0 0 0 0 0 0 # pages distin 100 1.36k 18 35 25.31 31.70 3.70 24.84 # EXPLAIN /*!50100 PARTITIONS*/ select * from friends where user_id = 1234G |
The friends table definition is:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE `friends` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` int(10) unsigned NOT NULL, `friend_user_id` int(10) unsigned NOT NULL, `created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `active` tinyint(4) NOT NULL DEFAULT '1', PRIMARY KEY (`id`), UNIQUE KEY `uk_user_id_friend` (`user_id`,`friend_user_id`), KEY `idx_friend` (`friend_user_id`) ) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1 |
I built this simple example on my test server. The table easily fits in memory, so there are no disk reads. What matters here is the relation between “page distin” and “Rows examine”. As you can see, the ratio is close to 1. It means that InnoDB rarely gets more than one row per page it accesses. For a given user_id value, the matching rows are scattered all over the primary key b-tree. We can confirm this by looking at the output of the sample query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
mysql> select * from friends where user_id = 1234 order by id limit 10; +-------+---------+----------------+---------------------+--------+ | id | user_id | friend_user_id | created | active | +-------+---------+----------------+---------------------+--------+ | 257 | 1234 | 43 | 2018-07-19 20:14:47 | 1 | | 7400 | 1234 | 1503 | 2018-07-19 20:14:49 | 1 | | 13361 | 1234 | 814 | 2018-07-19 20:15:46 | 1 | | 13793 | 1234 | 668 | 2018-07-19 20:15:47 | 1 | | 14486 | 1234 | 1588 | 2018-07-19 20:15:47 | 1 | | 30752 | 1234 | 1938 | 2018-07-19 20:16:27 | 1 | | 31502 | 1234 | 733 | 2018-07-19 20:16:28 | 1 | | 32987 | 1234 | 1907 | 2018-07-19 20:16:29 | 1 | | 35867 | 1234 | 1068 | 2018-07-19 20:16:30 | 1 | | 41471 | 1234 | 751 | 2018-07-19 20:16:32 | 1 | +-------+---------+----------------+---------------------+--------+ 10 rows in set (0.00 sec) |
The rows are often apart by thousands of id values. Although the rows are small, about 30 bytes, an InnoDB page doesn’t contain more than 500 rows. As the application becomes popular, there are more and more users and the table size grows like the square of the number of users. As soon as the table outgrows the InnoDB the buffer pool, MySQL starts to read from disk. Worse case, with nothing cached, we need one read IOP per friend. If the rate of these selects is 300/s and on average, every user has 100 friends, MySQL needs to access up to 30000 pages per second. Clearly, this doesn’t scale for long.
We need to determine all the ways the table is accessed. For that, I use pt-query-digest and I raise the limit on the number of query forms returned. Let’s assume I found:
The above proportions are quite common. When there is a dominant access pattern, we can do something. The friends table is a typical example of a many-to-many table. With InnoDB, we should define such tables as:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE `friends` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `user_id` int(10) unsigned NOT NULL, `friend_user_id` int(10) unsigned NOT NULL, `created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `active` tinyint(4) NOT NULL DEFAULT '1', PRIMARY KEY (`user_id`,`friend_user_id`), KEY `idx_friend` (`friend_user_id`), KEY `idx_id` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1 |
Now, the rows are ordered, grouped, by user_id inside the primary key B-Tree but the inserts are in random order. Said otherwise, we slowed down the inserts to the benefit of the select statements on the table. To insert a row, InnoDB potentially needs one disk read to get the page where the new row is going and one disk write to save it back to the disk. Remember in the previous analogy, we needed to take one sheet from the stack, add a name and put it back in place. We also made the table bigger, the InnoDB pages are not as full and the secondary indexes are bigger since the primary key is larger. We also added a secondary index. Now we have less data in the InnoDB buffer pool.
Shall we panic because there is less data in the buffer pool? No, because now when InnoDB reads a page from disk, instead of getting only a single matching row, it gets up to hundreds of matching rows. The amount of read IOPS is no longer correlated to the number of friends times the rate of select statements. It is now only a factor of the incoming rate of select statements. The impacts of not having enough memory to cache all the table are much reduced. As long as the storage can perform more read IOPS than the rate of select statements, all is fine. With the modified table, the relevant lines of the pt-query-digest output are now:
|
1 2 3 4 |
# Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Rows examine 100 1.23k 16 34 23.72 30.19 4.19 22.53 # pages distin 100 111 2 5 2.09 1.96 0.44 1.96 |
With the new primary key, instead of 30k read IOPS, MySQL needs to perform only about 588 read IOPS (~300*1.96). It is a workload much easier to handle. The inserts are more expensive but if their rate is 100/s, it just means 100 read IOPS and 100 write IOPS in the worse case.
The above strategy works well when there is a clear access pattern. On top of my mind, here are a few other examples where there are usually dominant access patterns:
What can you do when you don’t have a dominant access pattern? One option is the use of a covering index. The covering index needs to cover all the required columns. The order of the columns is also important, as the first must be the grouping value. Another option is to use partitions to create an easy to cache hot spot in the dataset. I’ll discuss these strategies in future posts, as this one is long enough!
We have seen in this post a common strategy used to solve read-intensive workload. This strategy doesn’t work all the time — you must access the data through a common pattern. But when it works, and you choose good InnoDB primary keys, you are the hero of the day!
Troubleshooting crashes can be an arduous task, particularly when MySQL does not report the crash’s cause (as can be the case when MySQL runs out of memory). However, with new versions of MySQL (5.7+) and performance_schema, we can troubleshoot memory allocation more easily. Read our blog to learn where to begin troubleshooting MySQL memory leaks.
If your business is looking for an architecture that provides availability, data consistency, and a strong foundation for more advanced deployments capable of surviving disaster scenarios, consider an Amazon EC2 environment running Percona XtraDB Cluster. Read our solution brief to learn more about the benefits of this cloud architecture solution.






Yves, great article on what so many consider after they have placed a table in production. My only complaint is you have not written anything on how to choose the best primary key and it involves/requires knowledge of the data.
If more mysql or database technicians were to focus on this during the data modeling phase they would have far fewer problems. There are huge gains for those who best understand database modeling, normalization of data, and the relational model itself as invented by Ted Codd back in the 60’s era. The model is straight set theory and is easily, mathmatically proven to work well when adhered to.
I have to admit I am very surprised the database industry does not require you to specify a pk rather than default to an internal hidden useless to users approach. Force the dba/programmer/user to think what is the best access path to the data. Ted Codd (inventor of the relational model) use to say if you have not identified the table’s PK then you have not identified the tables purpose which I fully agree. The proof PK’s should be mandated is if you have a table without a PK, then how do your batch programs indentify which row should be updated. You might be able to view the data and make that determination, but a program can not.
As most already know, know a Primary Key must be unique and can not contain nulls, otherwise you have not identified the row so to start you first identify all possible candidate keys, ie, those that are unique and dont allow nulls. Second choose the better of the candidate keys.
An example, best explains. Usually in most mysql shops you see lazy choices of auto incremented PKs proliferating the design and at the same time you see the most common secondary indexes that should have/ could have been the primary key. The point is improper choice of the PK always results in additional unnecessary secondary indexes which further slows inserts/updates/deletes. The pattern that shows is usually in the WHERE clauses where since the application did not know the value of the PK but it did know a name or a description it searched by the secondary key to then identify the PK. Note the similar pattern where Mysql includes the pk in all secondary indexes. Quite often the main secondary index assuming unique outweighs the choice of the autoincrement, not thought through key.
Then question the impact of single attribute PK’s like autoincrement verses a key that better represents the business but is perhaps a two attribute PK. If your model table hierarchy is only 2 to 3 deep then a multi-attribute key is manageable. If much deeper then it becomes problematic writing code since the lower levels of the hierarchy have to add an additional attribute that presents the next level. Also question the order of the attributes in the PK where your WHERE clauses must reference the first order attributes to even use the index. Also question the distinct cardinality of an attribute because the higher the distinct cardinality of an attribute the better it is in an index. Example, if an index’s first attribute has low cardinality, number of distinct values, then the index has to read/lock more similar rows to answer the questions quickly.
I believe the above process is why DBA’s, developers, implementors get lazy because they dont understand their data as well as they should. If they did understand the above becomes a very easy process to identify the best PK.
In summary I always inform our teams, choose the candidate key that best presents the business, the one you will search by, and most likely order by, group by since the PK is typically the clustered, physically sorted already index. Finally, for shops with huge write volumes as in 100’s of thousands of queries per second and more, Always, always, always UPDATE VIA the PK, never allow updates or deletes that are not PK based. Even if your volumes are lower “Design for millions of transactions per second” by only taking ONE ROW based update/delete locks as opposed to locking many rows. If you dont know the PK to update or delete by, then read in non locking mode to obtain the lists of PKs and then update or delete by the list.
I have used the above techniques for the last 37 plus years and they have never failed to produced significantly improved performance results. The above logic applies to every database I have ever worked on (IDMS, IMS, DB2, Oracle, MySQL, ObjectStar, CouchDB, MongoDB, other NOSQL db’s, and several CloudDBs), not just innodb engine tables.
Loved the article, keep up the good work.
If there is no primary key for a table, InnoDB adds a hidden auto-incremented 6 bytes counter to the table and use that hidden counter as the primary key.
I remember is 8 bytes.
If there is no primary key for a table, InnoDB adds a hidden auto-incremented 6 bytes counter to the table and use that hidden counter as the primary key.
I remember is 8 bytes.
From https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
“The row ID is a 6-byte field that increases monotonically as new rows are inserted.”
Hi,
The question seems to be stupid.
What about the choice of using a varchar column as a PRIMARY KEY ? Is there any limit concerning the maximum length of a varchar column used as PRIMARY KEY for Innodb table?
Someone has suggested, as alternative to int or a bingint columns, the use of MD5 or an UUID as a PRIMARY key for innodb.
Stofa.
Thanks.
Varchar are slow to compare, it is one byte at a time and use the charset and collation code. Integer types, other than mediumint, are compared by the CPU directly. MD5 and UUIDs are huge and random. All the secondary keys will be inflate by the huge PK. Maybe it is a good idea for developers but it is bad for InnoDB. When I have a customer stuck with suck PKs, we have to struggle to improve performance. I have an upcoming blog post on that topic.
Thanks for you post
Why not to create ‘friends’ table like this:
CREATE TABLE
friends(idint(10) unsigned NOT NULL AUTO_INCREMENT,user_idint(10) unsigned NOT NULL,friend_user_idint(10) unsigned NOT NULL,createdtimestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,activetinyint(4) NOT NULL DEFAULT ‘1’,PRIMARY KEY (
id),KEY
idx_friend(friend_user_id,’user_id’)) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1
– PK is autoincrement ( so, inserts are ordered , better for selecting write page )
– only one secondary index. It supports searches by (friend_user_id) and (friend_user_id,user_id)
Regards
because 93% of queries are by user_id. your schema would perform very poorly for these queries.
Thanks for your post
Why not to create ‘friends’ table like this:
CREATE TABLE
friends(idint(10) unsigned NOT NULL AUTO_INCREMENT,user_idint(10) unsigned NOT NULL,friend_user_idint(10) unsigned NOT NULL,createdtimestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,activetinyint(4) NOT NULL DEFAULT ‘1’,PRIMARY KEY (
id),KEY
idx_friend(friend_user_id,’user_id’)) ENGINE=InnoDB AUTO_INCREMENT=144002 DEFAULT CHARSET=latin1
– PK is autoincrement ( so, inserts are ordered , better for selecting write page )
– only one secondary index. It supports searches by (friend_user_id) and (friend_user_id,user_id)
Regards
You basically have a covering index, it will work great for searches by friend_user_id and the innodb change buffer will limit the impacts of the index maintenance.
I see a few issues.
– You cannot search by user_id
– You don’t have unicity for the pair (user_id,friend_user_id)
– Query forms like: “select friends_user_id from friends where user_id=1234 and active = 1;” are very bad because the index doesn’t provide “active”. The primary key b-tree must be queried.
My table works fine in all cases.
Great article on tuning ideology.
Just a random question, is there any specific need of ID column “
idint(10) unsigned NOT NULL AUTO_INCREMENT” afterwards you’ve shifted primary key to “PRIMARY KEY (user_id,friend_user_id)”?Is there any use-case to keep
Column :
idint(10) unsigned NOT NULL AUTO_INCREMENT andKey :
idx_id(id) ?Thanks for such informative post.
Just a random question. Is there any particular reason you’ve kept column (
idint(10) unsigned NOT NULL AUTO_INCREMENT) and index (KEYidx_id(id)) ? Since you’ve already set new PRIMARY KEY (user_id,friend_user_id), do you still need ID column and with index on it?!Just because removing it means modifying the application, some ORMs are stubborn in their will of having an “id” column. If it can be modified to use the new primary key, then yes, the id column and idx_id index can be removed.
Very informative. What is the relationship between primary key vs. partition key and their impact on performance? For example, I’d like to use ‘id’ as primary key because they are unique. id is also incrementally generated, so storing them together generally provide grouping of items that are relatively close in incoming timestamp. However, search is usually done with timestamp since I do not know id in advance. I am thinking a primary key index as such (id, timestamp). Since the tables are usually well over 100G, I would like to partition as well but on timestamp.
‘@john
If you search mainly by timestamp, it would be logical to have the primary key defined as (timestamp,id) and secondary key on (id) to support the auto_increment. Partitions by range of timestamp could still be useful to prune older data.
Yves, thanks for this very helpful article! I have a question regarding the concepts you explained: when having e.g. document data in a InnoDB table in a multi-tenant database used for multiple customer accounts, would it make sense / be wise to “preface” the primary key with the account ID? (Access pattern would be to retrieve e.g. the newest documents for a specific account.)
So instead of
CREATE TABLE documents (
doc_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
doc_account MEDIUMINT UNSIGNED NOT NULL,
doc_title VARCHAR(128) NOT NULL,
doc_date DATE NOT NULL,
…
PRIMARY KEY (doc_id),
INDEX (doc_account, doc_date)
)
it would be better to do this
CREATE TABLE documents (
doc_id INT UNSIGNED NOT NULL AUTO_INCREMENT,
doc_account MEDIUMINT UNSIGNED NOT NULL,
doc_title VARCHAR(128) NOT NULL,
doc_date DATE NOT NULL,
…
PRIMARY KEY (doc_account, doc_id),
INDEX (doc_account, doc_date)
)
? Would I leave the secondary index just as it is? Any help is highly appreciated!
‘@H, yes, it would make perfect sense to prefix the primary with doc_account. You need an additional index for the auto_increment doc_id column though. The secondary index is not bad at all. Remember InnoDB adds the primary key to the index columns. Naively, this gives (doc_account, doc_date, doc_account,doc_id) but, InnoDB is wise enough to avoid repeating columns so you really have (doc_account, doc_date,doc_id) for the secondary key.