
In this blog post, we’ll look at how to navigate some of the complexities of multi-source GTID replication.
GTID replication is often a real challenge for DBAs, especially if this has to do with multi-source GTID replication. A while back, I came across a really interesting customer environment with shards where multi-master, multi-source, multi-threaded MySQL 5.6 MIXED replication was active. This is a highly complex environment that has both pros and cons, introducing risks as a trade-off for specific customer requirements.
This is the set up of part of this environment:
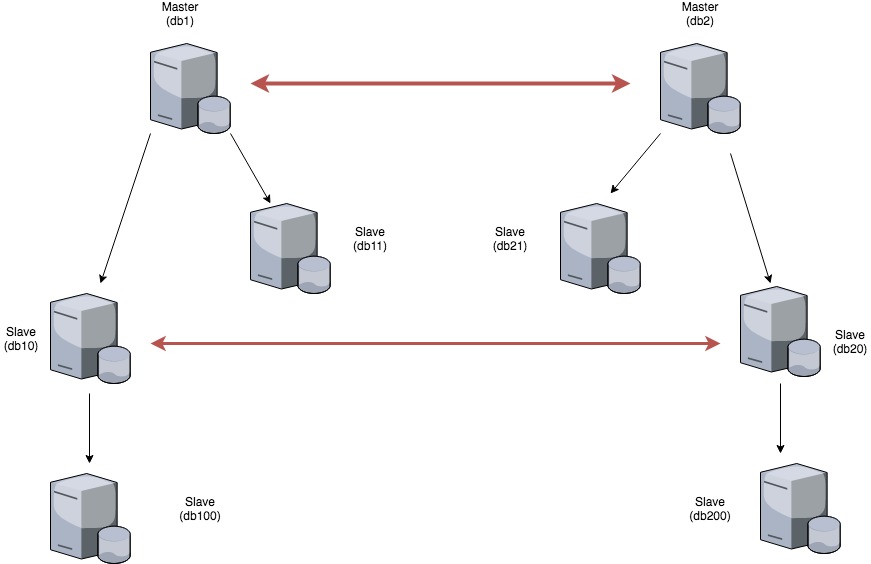
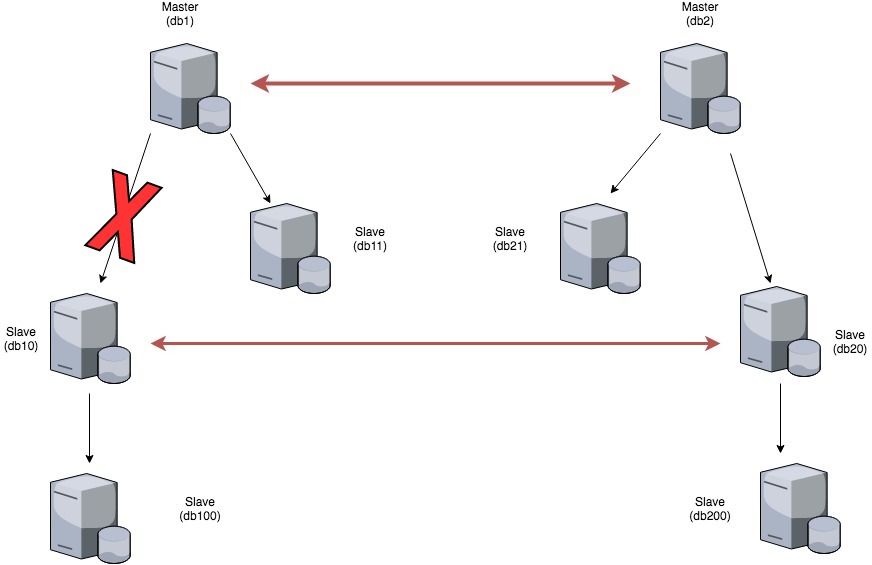
I started looking into this setup when a statement broke replication between db1 and db10. Replication broke due to a statement executed on a schema that was not present on db10. This also resulted in changes originating from db1 to not being pushed down to db100 as db10, as we stopped the replication thread (for db1 channel).
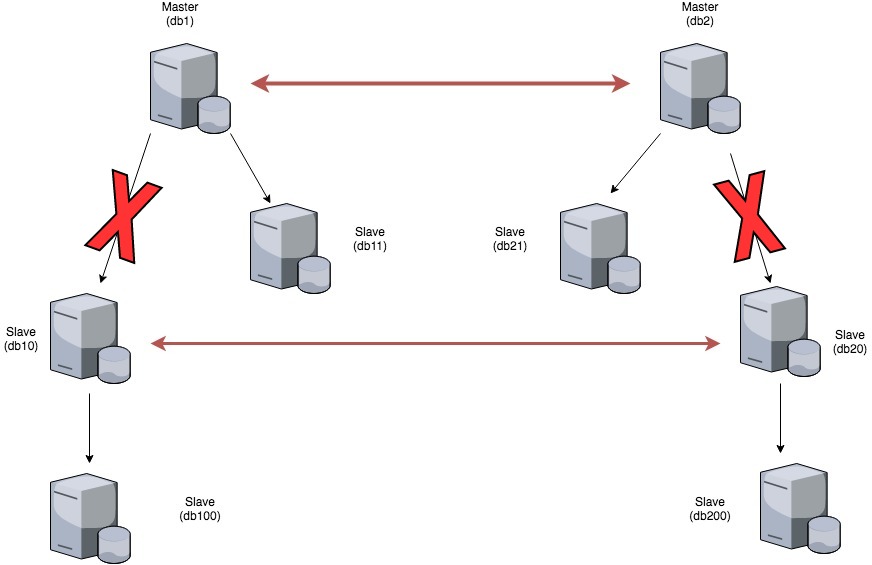
On the other hand, replication was not stopped on db2 because the schema in question was present on db2. Replication between db2 and db20 was broken as well because the schema was not present in db20.
In order to fix db1->db10 replication, four GTID sets were injected in db10.
Here are some interesting blog posts regarding how to handle/fix GTID replication issues:
After injecting the GTID sets, we started replication again and everything ran fine.
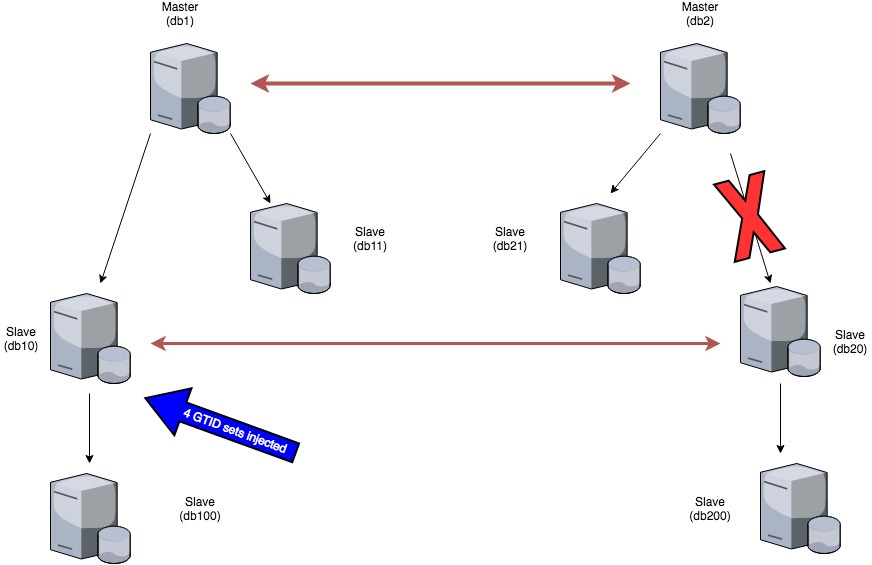
After that, we had to check the db2->db20 replication, which, as I’ve already said, was broken as well. In this case, injecting only the first GTID trx into db20 instead of all of those causing issues on db10 was enough!
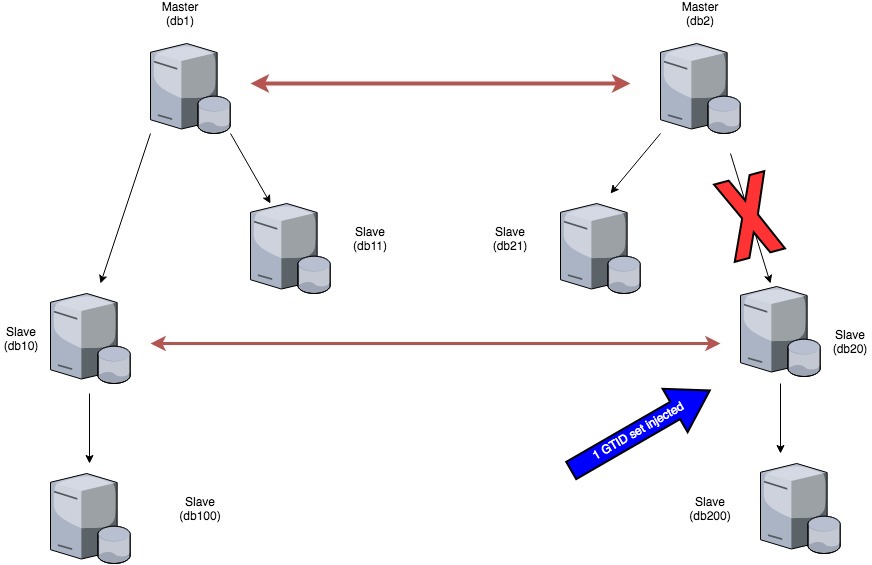
You may wonder how this is possible. Right? The answer is that the rest of them were replicated from db10 to db20, although the channel was not the same.
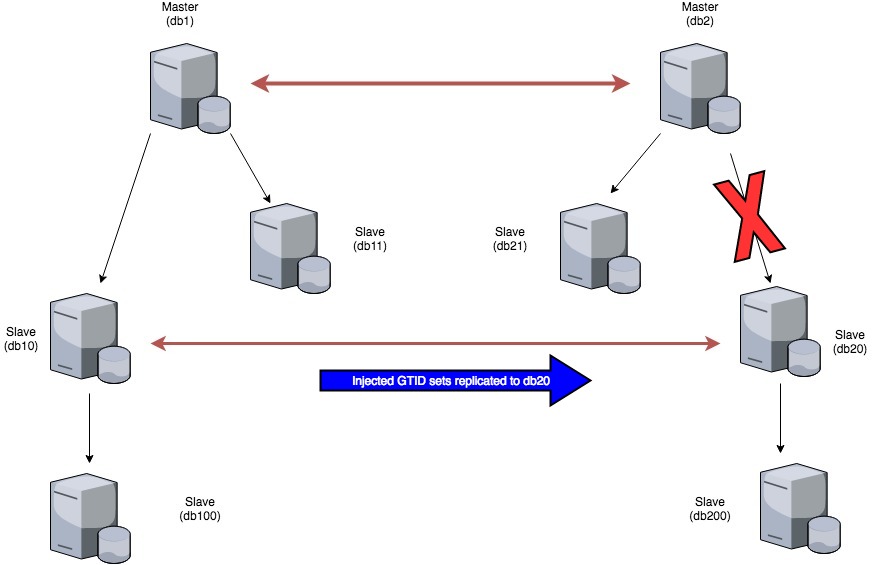
Another strange thing is the fact that although the replication thread for the db2->db20 channel was stopped (broken), checking the slave status on db20 showed that Executed_Gtid_Set was moving for all channels even though Retrieved_Gtid_Set for the broken one was stopped! So what was happening there?
This raised my curiosity, so I decided to do some further investigation and created scenarios regarding other strange things that could happen. An interesting one was about the replication filters. In our case, I thought “What would happen in the following scenario … ?”
Let’s say we write a row from db1 to db123.table789. This row is replicated to db10 (let’s say using channel 1) and to db2 (let’s say using channel2). On channel 1, we filter out the db123.% tables, on channel2 we don’t. db1 writes the row and the entry to the binary log. db2 writes the row after reading the entry from the binary log and subsequently writes the entry to its own binary log and replicates this change to db20. This change is also replicated to db10. So now, on db10 (depending on which channel finds the GTID first) it either gets filtered on channel1 and written to its own bin log at just start…commit with any actual DDL/DML removed, or if it is read first on channel2 (db1->db2 and then db20->db10) then it is NOT filtered out and executed instead. Is this correct? It definitely ISN’T!
You can find answers to the above questions in the points of interest listed below. Although it’s not really clear through the official documentation, this is what happens with GTID replication and multi-source GTID replication:
Executed_Gtid_Set is common for all channels. This means that regardless the originating channel, when a GTID transaction is executed it is recorded in all channels’ Executed_Gtid_Set. Although it’s logical (each database is unique, so if a trx is going to affect a database it shouldn’t be tightened to a single channel regardless of the channel it uses), the documentation doesn’t provide much info around this.



