
In this blog post, we will discuss how to use Percona Monitoring and Management for MongoDB monitoring, and how to get some key graphs to monitor your MongoDB database.
All production environments need metrics and historical data for easy and fast comparison of performance, throughput in the time.
Percona Monitoring and Management (PMM) can help your company with that. PMM does have a client in each instance and a server, and every second the server connects to the client to capture data and plot this data into easily-understood graphs.
Most of the data captured comes from the following administrative commands/stats:
For this blog, I’m using a three-instance replica set configured, which is the most common architecture.
We are going to use the MongoDB Overview and MongoDB Replicaset dashboards in PMM 1.7 to demonstrate how to interpret metrics proactively.
PMM does come with a few MongoDB dashboards, the first one we are going to use is MongoDB Overview. This Dashboard gives us an overview of a single instance and can be very useful to find instance isolated issues.

The number of operations the database is receiving. If the instance is a primary the possible values are: insert, delete, query or getmore. For secondaries, these values can be repl_insert, repl_delete, query and getmore.
MongoDB command:
|
1 2 |
db.serverStatus().opcounters db.serverStatus().opcountersRepl |


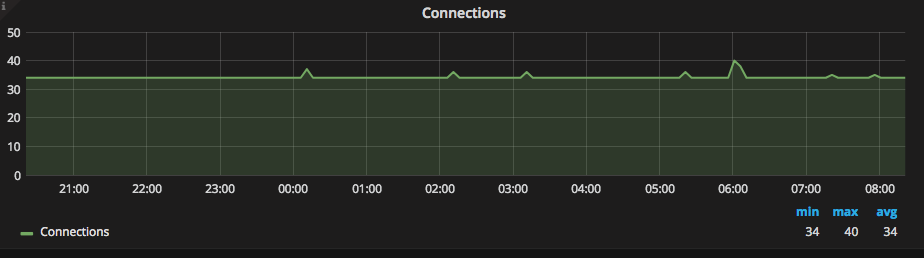
Rapidly increasing the number of connections can be a possible issue. With the connections graph we can see the connection pattern. This graph is valid for both primary and secondaries.
MongoDB command:
|
1 |
db.serverStatus().connections |
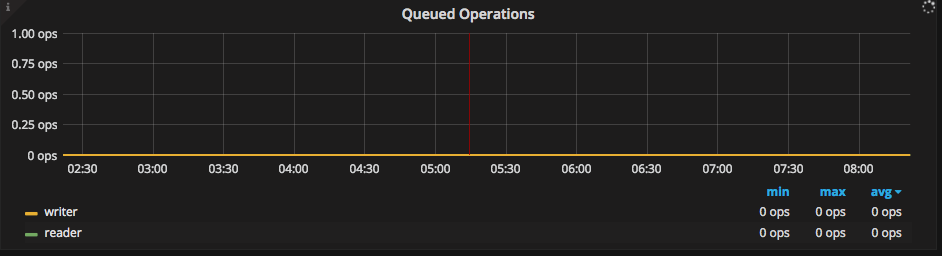
If this value is different than 0 means there is/was a query that had to wait before to run. This graph must be as close to 0 as possible, a high number of queued operations means the database is under a high load. Queues can be either read or writes, both are bad.
MongoDB command:
|
1 |
db.serverStatus().globalLock.currentQueue |
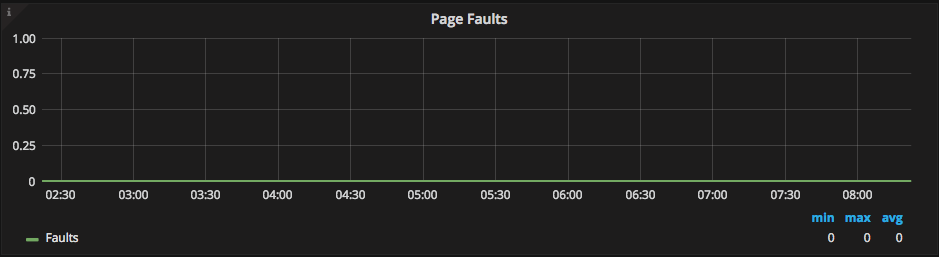
If your database size is bigger than the RAM, it is very probable (and OK) to have page faults. If this graph is always high, you may need to consider upgrading the memory.
MongoDB command:
|
1 |
db.serverStatus().extra_info.page_faults |
With those graphs, we can see what each instance is doing. But PMM does offer a better view for a replica set. So we can see what the database is doing in a wide view.

The first lines give a detailed explanation about the instance, such as what is the state of the instance, when was the last elections, the storage engine and the number of members in the replica set.
Most of the graphs do have a line per instance. Others require us to choose the instance at the top. In this case, I’m using node1 as an example and this instance is the primary in the replica.
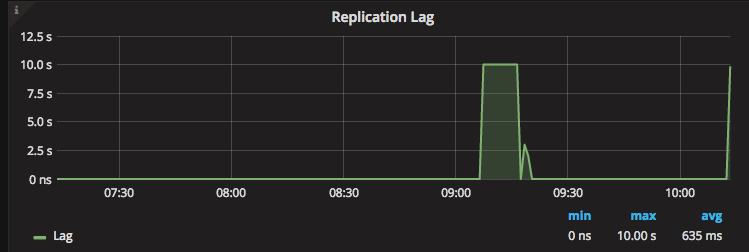
In a replica set, the most common and necessary metrics to view are Replication Lag.
This is how many seconds a secondary is behind its primary. Usually, a few seconds (such as 0 to 3) is OK considering that MongoDB replication is asynchronous. There is no strict value: 10 seconds or 30 seconds can be an issue, but it really changes for business to business.
MongoDB command:
|
1 |
db.printSlaveReplicationInfo() |
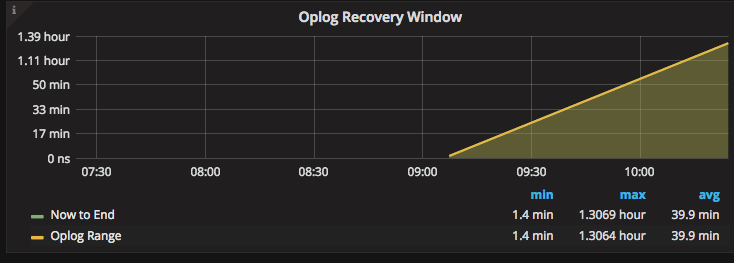
Replica sets need the oplogs to replicate their data for the other members. The oplog.rs is a capped collection that can only handle a fixed amount of data. The difference between the first and the last timestamp in the oplog.rs collection is called oplog window. This is the amount of time a secondary can be offline before an initial sync is needed to sync the instance.
MongoDB command:
|
1 |
db.printReplicationInfo() |
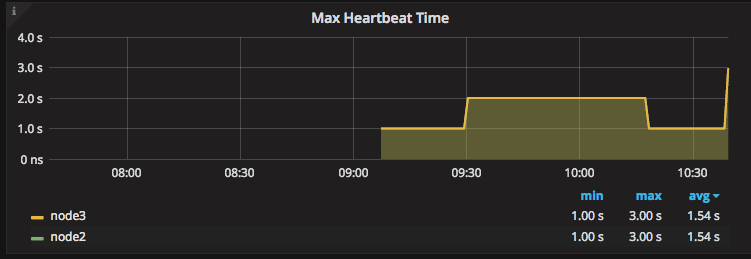
How long are the servers taking to confirm they are alive? A high number can mean the clocks are different or there is a serious network issue.
MongoDB command:
|
1 |
rs.status() |
There are a couple of other graphs available, check our online demo for more information:
https://pmmdemo.percona.com/graph/dashboard/db/mongodb-overview
I hope you find this article about Percona Monitoring and Management for MongoDB useful! Please feel free to contact me @AdamoTonete or @percona on Twitter anytime!




