
In this blog post, we’ll look at how ZFS affects MySQL performance when used in conjunction.
ZFS and MySQL have a lot in common since they are both transactional software. Both have properties that, by default, favors consistency over performance. By doubling the complexity layers for getting committed data from the application to a persistent disk, we are logically doubling the amount of work within the whole system and reducing the output. From the ZFS layer, where is really the bulk of the work coming from?
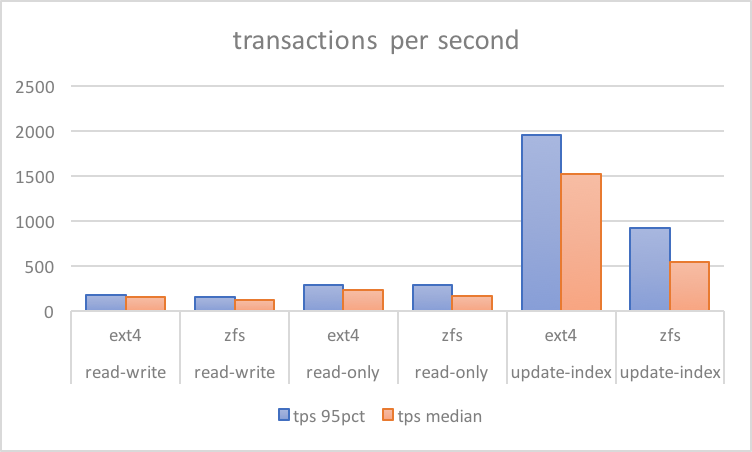
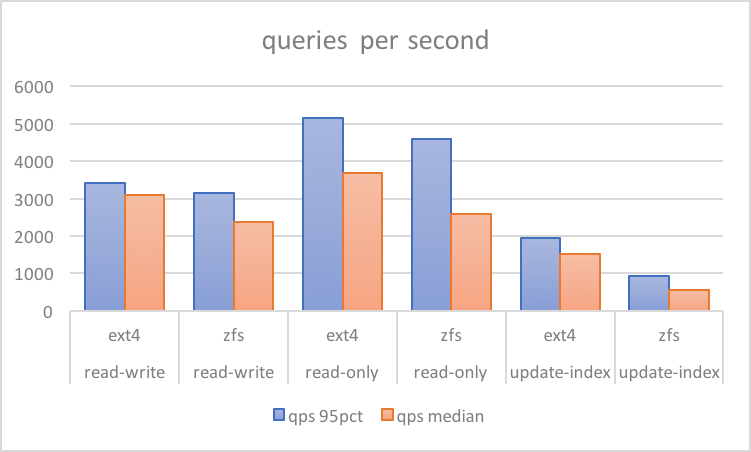
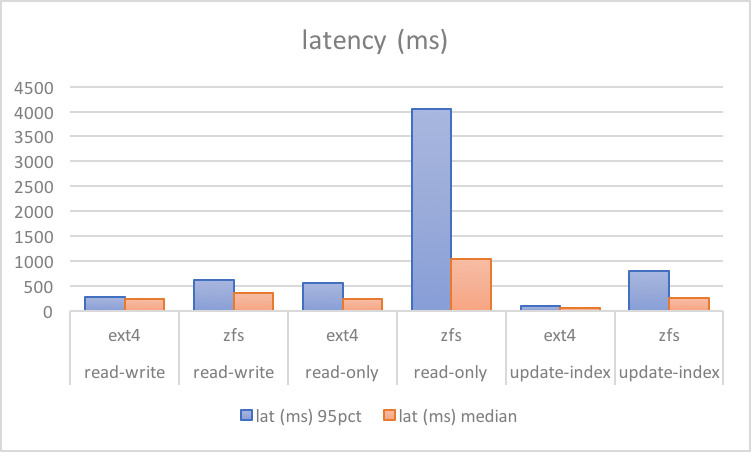
Consider a comparative test below from a bare metal server. It has a reasonably tuned config (discussed in separate post, results and scripts here). These numbers are from sysbench tests on hardware with six SAS drives behind a RAID controller with a write-backed cache. Ext4 was configured with RAID10 softraid, while ZFS is the same (striped three pairs of mirrored VDEvs).
There are a few obvious observations here, one being ZFS results have a high variance between median and the 95th percentile. This indicates a regular sharp drop in performance. However, the most glaring thing is that with write-only only workloads of update-index, overall performance could drop to 50%:
Looking further into the IO metrics for the update-index tests (95th percentile from /proc/diskstats), ZFS’s behavior tells us a few more things.
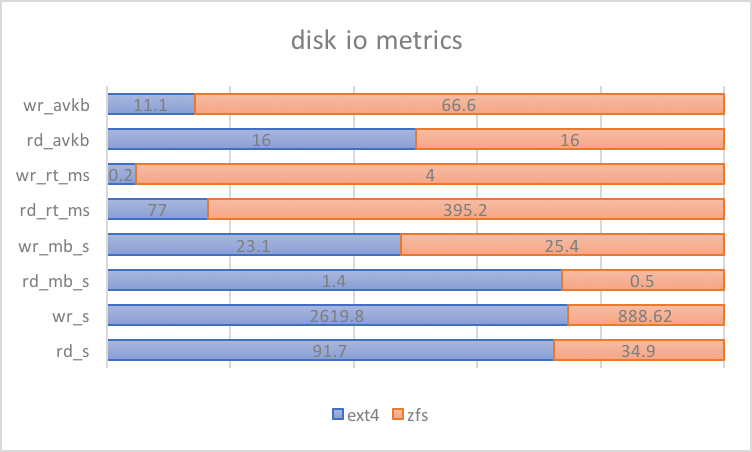
If we focus on observation #2, there are a number of possible sources of random reads:
This means that for updates on cold InnoDB records, multiple random reads are involved that are not present with filesystems like ext4. While ZFS has some tunables for improving synchronous reads, tuning them can be touch and go when trying to fit specific workloads. For this reason, ZFS introduced the use of L2ARC, where faster drives are used to cache frequently accessed data and read them in low latency.
We’ll look more into the details how ZFS affects MySQL, the tests above and the configuration behind them, and how we can further improve performance from here in upcoming posts.





ZFS has lot to improve from the stability perspective before it can really be used for MySQL data storage at scale.
This benchmark really is not in favour of ZFS. It‘s best practise to have a separate SSD ZFS ZIL device to have good write performance.
This benchmark is doing two disk writes for every mysql write because the data is first written to the zfs intent log snd later to the real blocks in the filesystem – sinply to have the crashsafe durable semantics of zfs. No wonder writes are 50% slower with zfs than ext4.
Yeaaa, this benchmark process is horribly thought out and misinformed. You should probably reach out to some real ZFS experts.
Indeed, i would like to see benchmark test tuned zfs vs. xfs vs. ext4. When using zfs, you can disable innodb double writes.
I know this is an old post, but I think I have to share where I think your results are coming from. I’m an old Solaris ZFS hand currently managing a cloud rollout of ZFSonLinux for latency-critical databases.
Most of the issues you mention here are due to pathologies in your configuration. The slow update-index writes are a result of the combination of compression and logbias=throughput on your data volume. logbias=throughput causes all sync writes to be indirect, which causes them to go through any RMW needed and compression *inline* with the write request. The result is that you only get one CPU’s worth of compression and the time needed to complete a sync write can be dramatically increased. This is actually nice for some databases, like MongoDB, where dbdata writes are essentially irrelevant to performance and actually benefit from being slowed down.
The read fragmentation is in large part due to the use of indirect sync writes as well. With normal (direct, on-disk ZIL or SLOG) sync writes, they are collected in the dirty data for the pool and when TxG commit occurs, each data block and each metadata block tends to be written sequentially if possible. One read is sufficient to pick them both up.
With logbias=throughput, the data itself is RMW/compressed/written inline with the write call. Then later, at TxG commit time, the metadata for this data is written out to the pool. The result is more fragmentation and potentially twice the IOPs necessary to fetch a block.
Small blocks are particularly painful for ZFS due to per-block metadata overhead. The cost of handling a 32K block is not significantly greater than that of handling a 16K one in many cases, and allows you to preserve more spatial locality. The combination of small blocks and indirect writes is the worst of all worlds, causing the most fragmentation and the poorest preservation of locality.
I would strongly recommend a configuration for your data volume along the lines of:
recordsize=32k
logbias=latency
primarycache=all
zfs_vdev_read_gap_limit=49152
It is rare that “primarycache=metadata” will be beneficial, even with workloads you wouldn’t think would gain anything from the caching. I’d highly recommend avoiding it while you dial in a configuration. You should not usually need to keep your ARC completely clean so that metadata can fill it.
Set zfs_immediate_write_sz=65536 or so to cause no writes to be done with indirect sync.
If you get problems with excessive RMW during TxG commit, rate limit it with zfs_sync_taskq_batch_pct.
Hope this helps and that you give this a try.
Janet,
This is interesting, thank you! I had a different understanding of logbias where latency is ideal only when you have an SLOG. I might have also tested this in the past but I have to double check. I will look into the rest of your recommendations as time permits and update this blog.
I’m glad it may help.
Basically, the downside to logbias=latency with ZIL blocks in your main disk is that you “double write” onto the same storage, potentially decreasing possible throughput etc.
However, this is often portrayed as worse than it is. Compression reduces the size of data written out, and data is refactored into recordsize blocks so while it’s kind of “double write”…it’s far far away from “double IOP”. The TxG commit writes are relatively low priority and easily shape themselves around other I/O.
The fact is, if you’re doing something throughput-intensive, you shouldn’t be doing it fully synchronously. It’s rare that you run into that need. The reason that logbias=throughput exists is really for large systems with plenty of disks and a SLOG, so if they have a badly behaved application that doesn’t need to be fast, it can be contained and not trash SLOG responsiveness for everyone else.