In this post, we’ll look at updating and deleting rows with ClickHouse. It’s the first of two parts.
You can see Part 2 of this post here.
ClickHouse is fast
Blazing fast! It’s quite easy to pick up, and with ProxySQL integrating with existing applications already using MySQL, it’s way less complex than using other analytics options. However, ClickHouse does not support UPDATE/DELETE (yet). That entry barrier can easily dissuade potential users despite the good things I mentioned.
If there is a will, there is a way! We have so far taken advantage of the new feature that supports more granular partitioning strategy (by week, by day or something else). With more granular partitions, and knowing what rows have changed, we can drop partitions with modified/deleted data and re-import them from MySQL. It is worth noting that this feature is still marked as experimental. It is nevertheless a very important feature.
To better demonstrate it, let’s say I have the hits table below and want to import it into ClickHouse for analysis:
|
|
CREATE TABLE `hits` ( `id` int(11) NOT NULL AUTO_INCREMENT, `type` varchar(100) DEFAULT NULL, `user_id` int(11) NOT NULL, `location_id` int(11) NOT NULL, `created_at` datetime DEFAULT NULL PRIMARY KEY (`id`), KEY `created_at` (`created_at`) ) ENGINE=InnoDB; |
Below is the corresponding ClickHouse table structure.
|
|
CREATE TABLE hits ( id Int32, created_day Date, type String, user_id Int32, location_id Int32, created_at Int32 ) ENGINE = MergeTree PARTITION BY toMonday(created_day) ORDER BY (created_at, id) SETTINGS index_granularity = 8192; |
Here’s a workflow diagram of how this works.
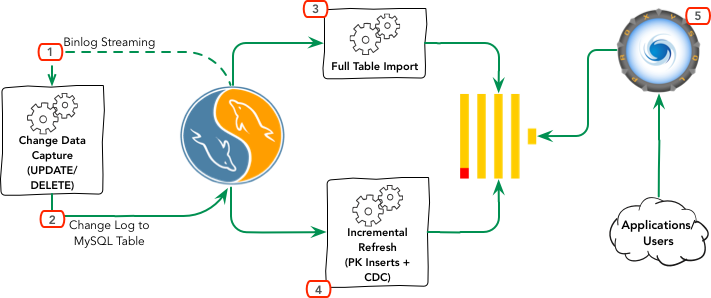
-
- The first step is to make sure we capture changes from the table(s). Because we technically cannot tell if a DELETE occurred unless it is actually an INSERT with some indication that the data should be invisible. Support for this means changing a lot of existing tables to an INSERT only model. Therefore we use a separate application to capture changes from the binary logs instead.
-
- Once we have established a tap to the source-MySQL-server’s binary logs, we filter the changes we need to record. In this case, UPDATE and DELETE. For each matching modified or deleted row, we create a record that indicates which partition it affects from the corresponding ClickHouse table. From the example table above, we simply convert the “created_at” column into a valid partition value based on the corresponding ClickHouse table. Examples here.
-
- Before we can consume the changelog, we’d have to import our table in full. The common use case is a simple import from MySQL to ClickHouse with one-to-one column mapping (except maybe for the partitioning key). In other cases, we’d also have to do transformations on the columns if needed.
-
- Once we have the table fully imported and our changelog captured continuously, we can then rebuild this table continuously:
-
- This process consults our changelog table to determine which partitions need to be updated. It would then dump the subset of that data from MySQL, drop the partition on ClickHouse and import the new data.
-
- Based on the PRIMARY KEY value from the source MySQL table, we can also determine what new rows we need to dump from the source table and INSERT to ClickHouse. If the partition where new INSERTs go has already been updated, we skip this part.
-
- Continue repeating the incremental process as frequent as needed.
-
- Your application should now be ready to use ProxySQL to connect to the ClickHouse backend and start running analytics queries.
Some footnotes:
-
- There is a simpler way to do this if you have a table with an INSERT only workload, and a qualified partitioning key already exists. See this blog post.
-
- Because this is not real-time, before each iteration of the incremental refresh a query on the target table from ClickHouse may have inconsistencies, especially if this happens when a partition is currently dropped. Some coordination between the incremental refresh and the querying application helps avoid this.
-
- The partitioning key is based on weekly data. This is fine in our example, given the compromise between how much data we need to keep (ALL vs. one year), how much average data per week (if this affects regular DROP of partition and import) and how many total partitions would be the result.
In the second part of this series, we’ll show the actual process and example codes!
You May Also Like
ProxySQL is regarded as a powerful and user-friendly tool that scales well. What’s more, you can use ProxySQL to achieve a significant boost in performance by using the proxy’s query caching mechanism. Our blog will show you how to set up the right configuration to attain improved performance. For AWS Aurora users, learn how to implement ProxySQL in your environment and reap the benefits of cluster access with more options and controls.






nice article and demonstration
The approach to delete by dropping partitions is a good approach. It is something that I have identified when trying to update Cloudera/Impala systems.
I would say though, that your approach follows a standard ‘refresh’ mechanism of an ETL process. If you view it as an ETL process then it is much easier to conceptually wrap your head around the mechanisms needing to maintain the system. You will also have access to available tools that can do this for you as well as add a layer of monitoring and error handling.