
 Since the purpose of a database system is to store data, there is close relationship with the filesystem. As MySQL consultants, we always look at the filesystems for performance tuning opportunities. The most common choices in term of filesystems are XFS and EXT4, on Linux it is exceptional to encounter another filesystem. Both XFS and EXT4 have pros and cons but their behaviors are well known and they perform well. They perform well but they are not without shortcomings.
Since the purpose of a database system is to store data, there is close relationship with the filesystem. As MySQL consultants, we always look at the filesystems for performance tuning opportunities. The most common choices in term of filesystems are XFS and EXT4, on Linux it is exceptional to encounter another filesystem. Both XFS and EXT4 have pros and cons but their behaviors are well known and they perform well. They perform well but they are not without shortcomings.
Over the years, we have developed a bunch of tools and techniques to overcome these shortcomings. For example, since they don’t allow a consistent view of the filesystem, we wrote tools like Xtrabackup to backup a live MySQL database. Another example is the InnoDB double write buffer. The InnoDB double write buffer is required only because neither XFS nor EXT4 is transactional. There is one filesystem which offers nearly all the features we need, ZFS. ZFS is arguably the most advanced filesystem available on Linux. Maybe it is time to reconsider the use of ZFS with MySQL.
ZFS on Linux or ZoL (from the OpenZFS project), has been around for quite a long time now. I first started using ZoL back in 2012, before it was GA (general availability), in order to solve a nearly impossible challenge to backup a large database (~400 GB) with a mix of InnoDB and MyISAM tables. Yes, ZFS allows that very easily, in just a few seconds. As of 2017, ZoL has been GA for more than 3 years and most of the issues that affected it in the early days have been fixed. ZFS is also GA in FreeBSD, illumos, OmniOS and many others.
This post will hopefully be the first of many posts, devoted to the use of ZFS with MySQL. The goal here is not to blindly push for ZFS but to see when ZFS can help solve real problems. We will first examine ZFS and try to draw parallels with the architecture of MySQL. This will help us to better understand how ZFS works and behaves. Future posts will be devoted to more specific topics like performance, PXC, backups, compression, database operations, bad and poor use cases and sample configurations.
ZFS is a filesystem that was developed by Sun Microsystems and introduced for the first time in with OpenSolaris in 2005. ZFS is unique in many ways, let’s first have a look at its code base using the sloccount tool which provides an estimation of the development effort.
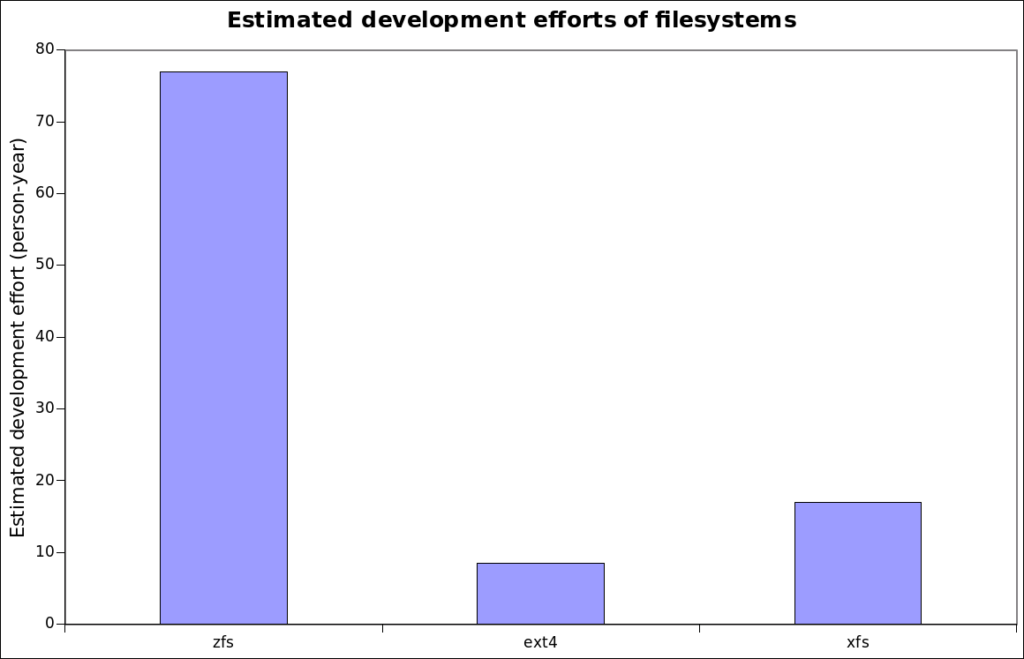
In term of code base complexity, it is approaching 10 times the complexity of EXT4, the above graphic shows the scale. To put things in perspective, the sloccount development effort for Percona-Server 5.7 which is based on MySQL community 5.7, is estimated at 680 person-years. The ZoL development is sponsored by the Lawrence Livermore National Laboratory and the project is very active.
Why does ZFS need such a large code base? Well, in Linux, it functionally replaces MD (software raid), LVM (volume manager) and the filesystem. ZFS is really a transactional database designed to support filesystem operations. Let’s review the ZFS main features.
That’s huge! According to Jeff Bonwick, the rest energy of such a storage device would be enough to boil the oceans. It seems inconceivable that we’d ever need a larger filesystem.
When ZFS needs to update a record it does not overwrite it. Instead, it writes a new record, change the pointers and then frees up the old one if it is no longer referenced. That design is at the core of ZFS. It allows for features like free snapshots and transactions.
ZFS supports snapshots, and because of its COW architecture taking a snapshot is merely a matter of recording a transaction number and telling ZFS to protect the referenced records from its garbage collector. This is very similar to the InnoDB MVCC. If a read view is kept open, InnoDB keeps a copy of each of the rows that changed in the undo log, and those rows are not purged until the transaction commits.
A ZFS snapshot can be cloned and then written too. At this point, the clone is like a fork for the original data. There is no equivalent feature in MySQL/InnoDB.
All the ZFS records have a checksum. This is exactly like the page checksums of InnoDB. If a record is found to have an invalid checksum, it is automatically replaced by a copy, provided one is available. It is normal to define a ZFS production with more than one copy of the data set. With ZFS, we can safely disable InnoDB checksums.
ZFS records can be compressed transparently. The most common algorithms are gzip and lz4. The data is compressed per record and the recordsize is an adjustable property. The principle is similar to transparent InnoDB page compression but without the need for punching holes. In nearly all the ZFS setups I have worked with, enabling compression helped performance.
ZoL doesn’t support transparent encryption of the records yet, but the encryption code is currently under review. If all goes well, the encryption should be available in a matter of a few months. Once there, it will offer another option for encryption at rest with MySQL. That feature compares very well with InnoDB tablespace encryption.
An fsync on ZFS is transactional. This comes mainly from the fact that ZFS uses COW. When a file is opened with O_SYNC or O_DSYNC, ZFS behaves like a database where the fsync calls represent commits. The writes are atomic. The fsync calls return as soon as ZFS has written the data to the ZIL (ZFS Intent Log). Later, a background process flushes the data accumulated in the ZIL to the actual data store. This flushing process is called at an interval of txg_timeout. By default, txg_timeout is set to 5s. The process is extremely similar to the way InnoDB flushes pages. A direct benefit for MySQL is the possibility of disabling the InnoDB doublewrite buffer. The InnoDB doublewrite buffer is often a source of contention in a heavy write environment, although the latest Percona Server releases have parallel doublewrite buffers that relieve most of the issue.
The transactional support in ZFS bears a huge price in term of latency, since the synchronous writes and fsyncs involve many random write IO operations. Since ZFS is transactional, it needs a transactional journal, the ZIL. ZIL stands for ‘ZFS Intent Log’. There is always a ZIL. The ZIL serves a purpose very similar to the InnoDB log files. The ZIL is written to sequentially, is fsynced often, and read from only for recovery after a crash. The goal is to delay random write IO operations by writing sequentially pending changes to a device. By default the ZIL delays the actual writes by only 5s (zfs_txg_timeout) but that’s still very significant. To help synchronous write performance, ZFS has the possibility of locating the ZIL on a Separate Intent Log (SLOG).
The SLOG device doesn’t need to be very large, a few GB is often enough, but it must be fast for sequential writes and fast for fsyncs. A fast flash device with good write endurance or spinners behind a raid controller with a protected write cache are great SLOG devices. Normally, the SLOG is on a redundant device like a mirror since losing the ZIL can be dramatic. With MySQL, the presence of a fast SLOG is extremely important for performance.
The ARC is the ZFS file cache. It is logically split in two parts, the ARC and the L2ARC. The ARC is the in memory file cache, while the L2ARC is an optional on disk cache that stores items that are evicted from the ARC. The L2ARC is especially interesting with MySQL because it allows the use of a small flash storage device as a cache for a large slow storage device. Functionally, the ARC is like the InnoDB buffer pool while the L2ARC is similar to tools like flashcache/bcache/dm-cache.
ZFS has its own way of dealing with disk. At the lowest level, ZFS can use the bare disks individually with no redundancy, a bit like JBOD devices used with LVM. Redundancy can be added with a mirror which is essentially a software RAID-1 device. These mirrors can then be striped together to form the equivalent of a RAID-10 array. Going further, there are RAIDZ-1, RAIDZ-2 and RAIDZ-3 which are respectively the equivalent of RAID-5, RAID-6 and RAID… Well, an array with 3 parities has no standard name yet. When you build a RAID array with Linux MD, you could have the RAID-5+ write hole issue if you do not have a write journal. The write journal option is available only in recent kernels and with the latest mdadm packages. ZFS is not affected by the RAID-5 write hole.
I already touched on this feature when I talked about the checksums. If more than one copy of a record is available and one of the copies is found to be corrupted, ZFS will return only a valid copy and will repair the damaged record. You can trigger a full check with the scrubcommand.
Not only can ZFS manage filesystems, it can also offer block devices. The block devices, called ZVOLs, can be snapshotted and cloned. That’s a very handy feature when I want to create a cluster of similar VMs. I create a base image and then snaphot and create clones for all the VMs. The whole image is stored only once, and each clone contains only the records that have been modified since the original clone was created.
ZFS allows you to send and receive snapshots. This feature is very useful to send data between servers. If there is already a copy of the data on the remote server, you can also send only the incremental changes.
ZFS can automatically hardlink together files (or records) that have identical content. Although interesting, if you have a lot of redundant data, the dedup feature is very intensive. I don’t see a practical use case of dedup for databases except maybe for a backup server.
This concludes this first post about ZFS, stay tuned for more.
Resources
RELATED POSTS





When I was running my primary DB on a Solaris 10 box, I used ZFS to perform my MySQL backups. The process was very simple:
1. Flush tables with read lock
2. Snapshot the DB data filesystem
3. Release the read lock
4. Clone the snapshot
5. Mount the clone
6. Perform file-level backup of the cloned snapshot
7. Unmount the cloned snapshot
8. Free the snapshot and clone
Steps 1-3 took literally a couple of seconds.
How often do you test restores from that? Have you used those backups to create additional async replicas?
I did a number of test restores with good results. It did trigger an InnoDB crash recovery because the files were captured in unclean state, but before-and-after verification showed no data was lost.
However, I’m no longer using that backup method because I’m no longer running a DB node on Solaris. Currently I’m running a three-node Galera cluster and backing it up using mydumper.
Cool, when I was still doing this stuff, we used xtrabackup and mydumper to get consistent restorable data. We had a fully automated system that would allow async nodes to be bootstrapped by an automated provisioning system that would restore the xtrabackup data from HDFS.
We had a manual process for doing the mydumper restores.
Be careful with mydumper and galera, we had too many issues with read pressure causing write stalls. We ended up using async (GTID) nodes for doing SQL dump backups even with galera.
The comparison is limited to a memory cache…
Like a thousand times 🙂 My scripts are in https://github.com/y-trudeau/Yves-zfs-tools. The mysql-zfs-snap.sh creates a snapshot with the master position in a file in the snapshot. The mk-mysql-clone.sh creates clone based MySQL slaves from the snapshots created by the previous script. Both script have run for a long time under cron.
Nice, that’s pretty good.
Although, the shell code isn’t bad, the GREP=
which greppattern you’re using is oddly unnecessary. If you’re relying on the PATH to find grep, just call grep.This is a nice first post. I look forward to more.
Very interesting! The next posts will definitely attract my attention!
Mysql on ZFS+SSD is amazing as well, one can use lz4 compression on ZFS, and raidzX is fast enough compared to have to use raid10 with mechanical disks for most use cases. This allows upgrading from mechanical disks to a full ssd setup with more capacity and lower cost, but 10x more performance.
nice post thanks! I can hardly wait for the next.
How can we compare the ARC to the innodb buffer pool in such a setup? Most of the tutorials on the web would favor innodb buffer pool and assign it the lion’s share of RAM. However the ARC is more advanced and is not a simple LRU cache, and this can be beneficial for servers with several databases so that rows touched once do not evict ones used frequently. Do you have an opinion on this topic?
Dont forget arc is compressed now as well
Transparent/native filesystem compression and of course no doublewrite buffering need are nice tangible wins which are readily seen/appreciated in a production environment. There is the downside of no O_DIRECT support (I assume fcntl(fd, F_SETFL, O_DIRECT) is still not supported?). From a practical point of view these days, mysql seems to be able to take the option (at least the environments I’ve been in), but will eventually lead to a corrupted instance which I assume is due to that lack of support.
Would be interesting to explore, or hear from someone, the tradeoffs more in depth and whether ZFS being COW makes lack of O_DIRECT support less (or maybe more) of a downside (with various workloads) for applications with their own buffering management like mysql.
The only reason to use O_DIRECT is to avoid double buffering. With ZFS, if you limit the size of the ARC or runs the filesystem where the InnoDB data is located with primarycache=metadata, you do limit the double buffering.
good information, would be great to see some benchmarks playing with a few different options and workloads.
thank you for your nice post!
I’d like to introduce this article for users in Japan by translating this article into Japanese.
Would you mind if I publish translation?