
This blog was originally published in October 2017 and was updated in March 2025.
Is your MongoDB database struggling with growth? Sharding might be the answer, but it’s a complex architectural change. Understanding MongoDB sharding best practices is crucial before you decide to implement it. This blog post explores the key drivers for sharding a MongoDB cluster, examines the scenarios where it makes sense, and discusses the fundamental considerations and best practices involved in this scaling strategy.
Related: MongoDB Configuration 101: 5 Configuration Options That Impact Performance and How to Set Them
Sharding in MongoDB is a technique used to distribute a database horizontally across multiple nodes or servers, known as “shards.” Each shard manages a portion of the data, forming a sharded cluster, which enables MongoDB to handle large datasets and high user concurrency effectively.
In a sharded cluster, each shard acts as an independent database responsible for storing and managing specific data. When data is inserted into the cluster, MongoDB’s balancer automatically redistributes the data across the shards, ensuring a balanced distribution and workload.
Sharding enables horizontal scaling, where more servers or nodes are added to the cluster to handle increasing data and user demands. Horizontal scaling enhances performance and capacity as the workload is shared across multiple machines, reducing the risk of a single point of failure. Vertical scaling is also often discussed, which involves increasing the resources of a single server, which can have limitations in hardware capabilities and become costly as demands grow. Sharding is a preferred approach for database systems facing substantial growth and needing high availability.
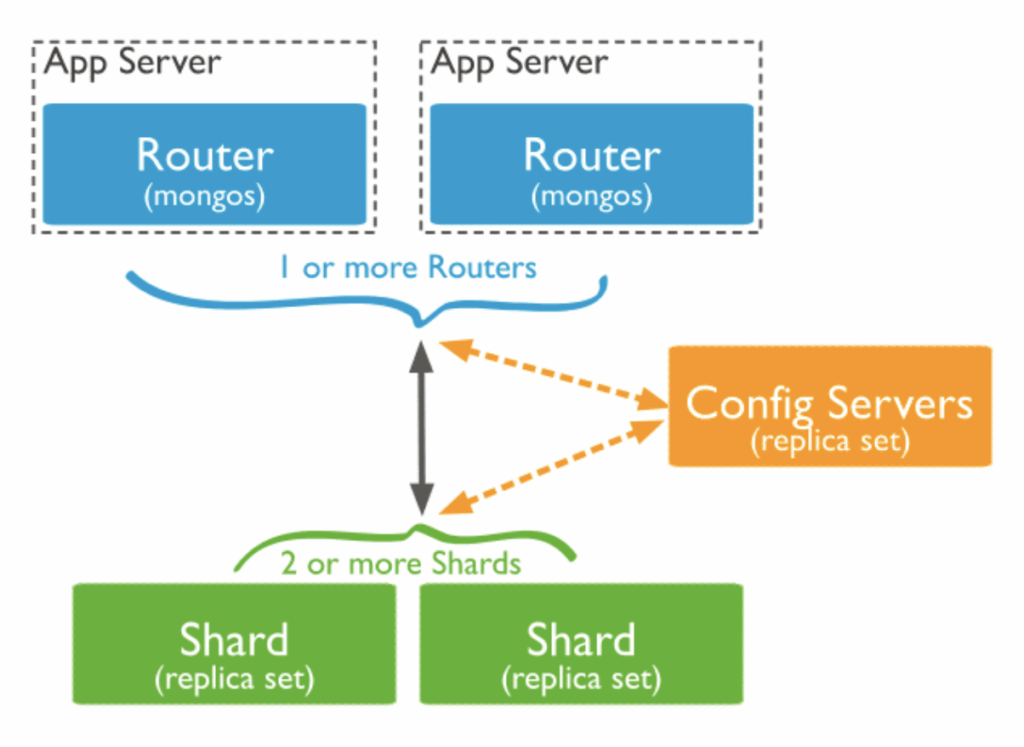
The sharding architecture consists of several components:
Shard Servers: Shard servers are individual nodes within the sharded cluster. Each shard stores a subset of the data and operates as an independent database. MongoDB distributes data across these shard servers to ensure an even distribution.
Config Servers: Config servers store the metadata and configuration information for the sharded cluster, including details about the distribution of data across shards, chunk ranges, and the shard key. Config servers facilitate the coordination of queries and data migrations within the sharded cluster.
Query Routers (mongos): Query routers, also known as “mongos” processes, act as the interface between applications and the sharded cluster. They receive requests, route queries to the appropriate shards, and aggregate results when needed. Mongos processes hide the underlying sharding complexity from the application, making it appear as a single logical database.
Ready to leave MongoDB, Inc. behind? Percona is the cost-effective, enterprise-grade alternative businesses trust.

Shard Key: The shard key is a field or set of fields chosen to determine how data is distributed across the shards. It’s essential to select an appropriate shard key to ensure even data distribution and efficient querying. A poorly chosen shard key can lead to performance issues.
Chunk: A chunk is a range of data within a shard that is determined by the shard key. Chunks are the units of data migration between shards during rebalancing operations.
Balancer: The balancer is responsible for ensuring an even distribution of data across the shards. As data is added or removed, the balancer migrates chunks of data between shards to maintain data balance and optimal performance.
Together, these components form the sharding architecture, which allows MongoDB to scale horizontally and efficiently manage vast amounts of data.
Learn more: Compare PostgreSQL Sharding and MongoDB Sharding
Start the mongod processes for the config server replica set with the –configsvr option. Each replica set can have multiple mongod processes (up to 50), but avoid using arbiters or zero-priority members. An example command:
|
1 |
mongod --configsvr --replSet <configReplSetName> --dbpath <path> --port 27019 --bind_ip localhost,<hostname(s)|ip address(es)> |
Connect to any one of the replica set members using the mongo shell. Here’s an example:
|
1 |
mongo --host <hostname> --port 27019 |
Run the rs.initiate() command on one of the replica set members to initiate the config server replica set. Use the following example command as a guide:
|
1 2 3 4 5 6 7 8 9 10 11 |
rs.initiate( { _id: "<configReplSetName>", configsvr: true, members: [ { _id : 0, host : "<cfg1.example.net:27019>" }, { _id : 1, host : "<cfg2.example.net:27019>" }, { _id : 2, host : "<cfg3.example.net:27019>" } ] } ) |
Now that the config server replica set is set up and running, we can create the shards in MongoDB.
Start the mongod processes for each shard replica set with the –shardsvr option. Each shard will have its own replica set with a different name. Example:
|
1 |
mongod --shardsvr --replSet <shardReplicaSetName> --dbpath <path> --port 27018 --bind_ip <cluster hostname(s)|ip address(es)> |
Use the mongo shell to connect to any one of the replica set members of the shard.
|
1 |
mongo --host <hostname> --port 27018 |
Run the rs.initiate() command on one of the replica set members of each shard to initiate the shard replica set. Make sure to omit the –configsvr option. An example command:
|
1 2 3 4 5 6 7 8 9 10 |
rs.initiate( { _id: "<shardReplicaSetName>", members: [ { _id : 0, host : "<shard-host1.example.net:27018>" }, { _id : 1, host : "<shard-host2.example.net:27018>" }, { _id : 2, host : "<shard-host3.example.net:27018>" } ] } ) |
The shard replica sets are now set up and running. You can now proceed with the sharding process in MongoDB.
To complete the setup, start the mongos process and connect it to the config servers replica set.
|
1 |
mongos --configdb <configReplSetName>/<cfg1.example.net:27019>,<cfg2.example.net:27019>,<cfg3.example.net:27019> --bind_ip localhost,<cluster hostname(s)|ip address(es)> |
It’s recommended to deploy multiple mongos instances to distribute the workload and ensure high availability.
To configure and enable sharding for your MongoDB database, follow these steps:
Connect to your mongos instance:
|
1 |
mongo --host <hostname> --port 27017 |
Add each shard to the cluster using the sh.addShard() command. Do this for each shard:
|
1 |
sh.addShard("<shardReplicaSetName>/<shard-host1.example.net:27018>,<shard-host2.example.net:27018>,<shard-host3.example.net:27018>") |
Enable sharding on your desired database using the sh.enableSharding() method:
|
1 |
sh.enableSharding("<database>") |
Finally, shard your collection using the sh.shardCollection() method. You have two options: hashed sharding for even data distribution or range-based sharding for optimizing queries across data ranges. Choose one of the following commands based on your needs:
a. For hashed sharding:
|
1 |
sh.shardCollection("<database>.<collection>", { <shard key field> : "hashed", ... }) |
b. For range-based sharding:
|
1 |
sh.shardCollection("<database>.<collection>", { <shard key field> : 1, ... }) |
Your sharded cluster is now set up. Ensure that any application interactions are performed through the mongos instances to take full advantage of sharding.
Ensure your databases are performing their best — today and tomorrow — with proactive database optimization and query tuning. Book a database assessment
Disaster recovery (DR) is a very delicate topic: how long would you tolerate an outage? If necessary, how long would it take you to restore the entire database? Depending on the database size and on disk speed, a backup/restore process might take hours or even days!
There is no hard number in Gigabytes to justify a cluster. But in general, you should engage when the database is more than 200GB the backup and restore processes might take a while to finish.
Let’s consider the case where we have a replica set with a 300GB database. The full restore process might last around four hours, whereas if the database has two shards, it will take about two hours – and depending on the number of shards we can improve that time. Simple math: if there are two shards, the restore process takes half of the time to restore when compared to a single replica set.
Disaster recovery (DR) is a very delicate topic: how long would you tolerate an outage? If necessary, how long would it take you to restore the entire database? Depending on the database size and on disk speed, a backup/restore process might take hours or even days!
There is no hard number in Gigabytes to justify a cluster. But in general, you should engage when the database is more than 200GB the backup and restore processes might take a while to finish.
Let’s consider the case where we have a replica set with a 300GB database. The full restore process might last around four hours, whereas if the database has two shards, it will take about two hours – and depending on the number of shards we can improve that time. Simple math: if there are two shards, the restore process takes half of the time to restore when compared to a single replica set.
Disk and memory are inexpensive nowadays. However, this is not true when companies need to scale out to high numbers (such as TB of RAM). Suppose your cloud provider can only offer you up to 5,000 IOPS in the disk subsystem, but the application needs more than that to work correctly. To work around this performance limitation, it is better to start a cluster and divide the writes among Mongodb instances. That said, if there are two shards the application will have 10000 IOPS available to use for writes and reads in the disk subsystem.
There are a few storage engine limitations that can be a bottleneck in your use case. MMAPv2 does have a lock per collection, while WiredTiger has tickets that will limit the number of writes and reads happening concurrently. Although we can tweak the number of tickets available in WiredTiger, there is a virtual limit – which means that changing the available tickets might generate processor overload instead of increasing performance. If one of these situations becomes a bottleneck in your system, you start a cluster. Once you shard the collection, you distribute the load/lock among the different instances.
Several databases only work with a small percentage of the stored data. This is called hot data or working set. Cold data or historical data is rarely read and demands considerable system resources when it is. So why spend money on expensive machines that only store cold data or low-value data? With a cluster deployment, we can choose where the cold data is stored, and use cheap devices and disks to do so. The same is true for hot data – we can use better machines to have better performance. This methodology also speeds up writes and reads on the hot data, as the indexes are smaller and add less overhead to the system.
It doesn’t matter whether this need comes from application design or legal compliance. If the data must stay within continent or country borders, a cluster helps make that happen. It is possible to limit data localization so that it is stored solely in a specific “part of the world.” The number of shards and their geographic positions is not essential for the application, as it only views the database. This is commonly used in worldwide companies for better performance, or simply to comply with the local law.
Infrastructure and hardware limitations are very similar. When thinking about infrastructure, however, we focus on specific cases when the Mongodb instances should be small. An example is running MongoDB on Mesos. Some providers only offer a few cores and a limited amount of RAM. Even if you are willing to pay more for that, it is not possible to purchase more than they offer as their products. A cluster provides the option to split a small amount of data among a lot of shards, reaching the same performance a big and expensive machine provides.
Consider that a replica set or a single instance holds all the data. If for any reason this instance/replica set goes down, the whole application goes down. In a cluster, if we lose one of the five shards, 80% of the data is still available. Running a few shards helps to isolate failures. Obviously, running a multiple MongoDB instances makes the cluster prone to have a failed instance, but as each shard must have at least three instances the probability of the entire shard being down is minimal. For providers that offer different zones, it is good practice to have different members of the shard in different availability zones (or even different regions).
Queries can take too long, depending on the number of reads they perform. In a clustered deployment, queries can run in parallel and speed up the query response time. If a query runs in ten seconds in a replica set, the same query will likely run in five to six seconds if the cluster has two shards, and so on.
Having a naive shard scheme (using a shard key with low cardinality or poor data distribution properties) in MongoDB can lead to significant concerns, most notably the creation of jumbo chunks in shards. When data is inserted or updated in the collection, MongoDB attempts to evenly distribute chunks across shards based on the shard key. However, if the shard key has low cardinality (a limited number of unique values), it can result in uneven data distribution, causing certain shards to handle significantly more data than others. As a consequence, some shards might end up with oversized chunks, known as jumbo chunks, while others remain underutilized. Jumbo chunks can negatively impact query performance, lead to inefficient data migrations, and increase the risk of data hotspots and unbalanced workloads.
In contrast, using shard keys with high cardinality can be a better solution in some instances. High cardinality keys have a large number of unique values, resulting in more even data distribution across shards. This helps prevent the creation of jumbo chunks and promotes better load balancing among shards. High cardinality keys can also reduce the likelihood of data hotspots and improve query performance by evenly distributing query traffic across shards. Careful consideration of the shard key are crucial to avoid potential pitfalls associated with naive shard schemes and to leverage the full benefits of sharding in MongoDB.
Using monotonically increasing or auto-increasing keys, such as timestamps or incrementing integers, as the shard key in MongoDB can lead to a common scalability pitfall known as “hotspotting,” when all new data is consistently inserted into a single shard, causing that shard to become a bottleneck. As a result, the shard with the highest shard key value will receive most of the writes, while other shards remain underutilized. This can lead to significant write contention and reduced performance.
To overcome the issues of hotspotting and uneven data distribution, a hashed sharding key scheme is preferred in MongoDB. In a hashed sharding key scheme, the shard key value is hashed to determine the shard where the data will be placed. The hashing function evenly distributes data across all shards in a random manner, avoiding the concentration of writes on a single shard. For scenarios where even distribution and horizontal scaling are essential, using a hashed sharding key is a better approach than relying on monotonically increasing keys.
Opting for early sharding proves advantageous as it empowers DBAs to build a scalable and optimized architecture right from the beginning. The distribution of data across multiple shards ensures efficient management of increasing data volumes and user traffic, safeguarding against performance issues and data hotspots. Early sharding also streamlines future scaling endeavors, improves query performance, and bolsters high availability and disaster recovery capabilities.
There are several benefits to monitoring traffic patterns and running the shard balancer during low-traffic times:
To run the shard balancer during chosen low-traffic times, DBAs can use MongoDB’s built-in balancer scheduler. Here’s an example of how to do it:
|
1 2 |
sh.startBalancer() sh.getBalancerState() |
|
1 |
db.settings.save({ _id: "balancer", activeWindow: { start: "01:00", stop: "04:00" } }) |
|
1 |
db.settings.find({ _id: "balancer" }) |
With this configuration, the shard balancer will run only during the specified low-traffic hours while remaining inactive during peak times, ensuring a more performant database.
MongoDB sharding is used to ensure the efficient handling of data growth and user traffic in a high availability, high-performance database environment. By distributing data, queries, and write operations across shards, sharding improves query performance and reduces contention to support data-intensive applications efficiently.
In MongoDB, sharding is a horizontal scaling technique that distributes data across multiple servers or nodes (shards) to handle increasing data volumes and user demands. Partitioning is a logical data organization approach within a single server, where data is divided into smaller partitions to improve data management.
The difference between replication and sharding in MongoDB is that replication is a data redundancy technique used to create copies of the data across multiple servers (replica sets), while harding is a horizontal scaling technique that distributes data across multiple servers or nodes (shards) to handle growing data volumes and user demands.
Auto sharding in MongoDB automatically distributes data across multiple shards, allowing the database system to handle large datasets and high user demands. MongoDB uses a shard key to determine the target shard for each data item, and as data is updated, the system routes it to the appropriate shard based on the shard key. The balancer component continuously monitors the distribution and automatically migrates chunks of data between shards to maintain a balanced workload.
Resources
RELATED POSTS




