
In this blog, I’ll use ClickHouse and Tabix to look at a new very large dataset for research.
It is hard to come across interesting datasets, especially a big one (and by big I mean one billion rows or more). Before, I’ve used on-time airline performance available from BUREAU OF TRANSPORTATION STATISTICS. Another recent example is NYC Taxi and Uber Trips data, with over one billion records.
However, today I wanted to mention an interesting dataset I found recently that has been available since 2015. This is Reddit’s comments and submissions dataset, made possible thanks to Reddit’s generous API. The dataset was first mentioned at “I have every publicly available Reddit comment for research,” and currently you can find it at pushshift.io. However, there is no guarantee that pushshift.io will provide this dataset in the future. I think it would be valuable for Amazon or another cloud provider made this dataset available for researchers, just as Amazon provides https://aws.amazon.com/public-datasets/.
The dataset contains 2.86 billion records to the end of 2016 and is 709GB in size, uncompressed. This dataset is valuable for a variety of research scenarios, from simple stats to natural language processing and machine learning.
Now let’s see what simple info we can collect from this dataset using ClickHouse and https://tabix.io/, a GUI tool for ClickHouse. In this first round, we’ll figure some basic stats, like number of comments per month, number of authors per month and number of subreddits. I also added how many comments in average are left for a post.
Queries to achieve this:
|
1 2 3 4 5 6 7 |
SELECT toYYYYMM(created_date) dt,count(*) comments FROM commententry1 GROUP BY dt ORDER BY dt ;; SELECT toYYYYMM(created_date) dt,count(DISTINCT author) authors FROM commententry1 GROUP BY dt ORDER BY dt ;; SELECT toYYYYMM(created_date) dt,count(DISTINCT subreddit) subreddits FROM commententry1 GROUP BY dt ORDER BY dt ;; SELECT toYYYYMM(created_date) dt,count(*)/count(distinct link_id) comments_per_post FROM commententry1 GROUP BY dt ORDER BY dt |
And the graphical result:
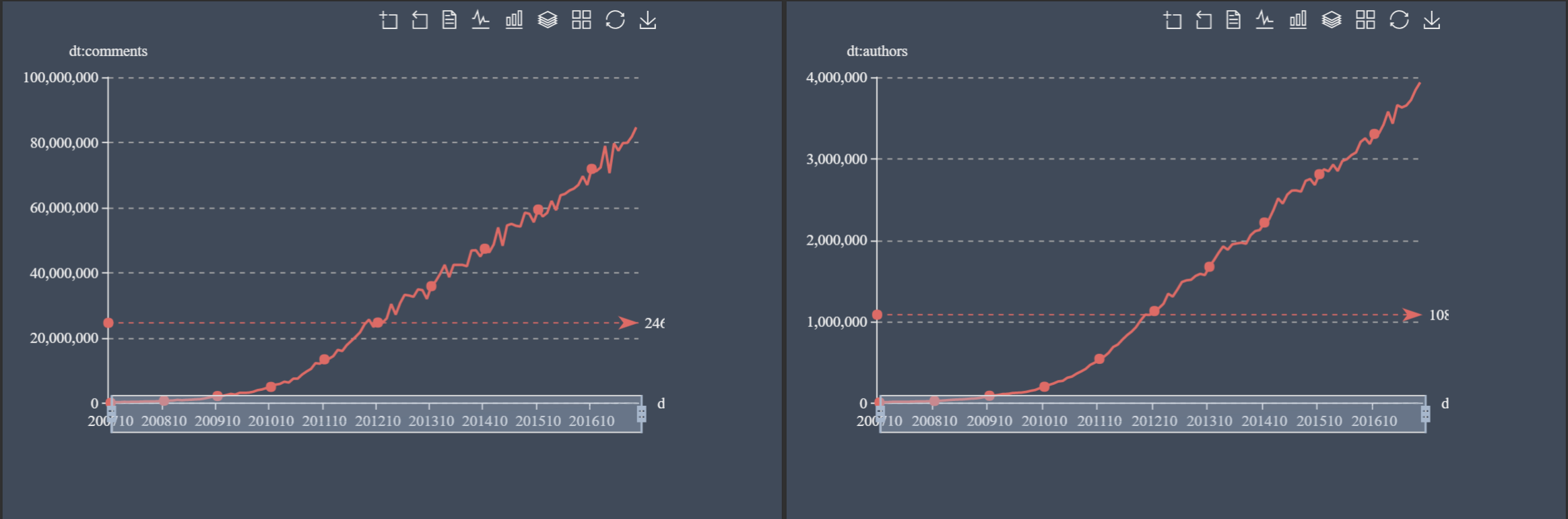
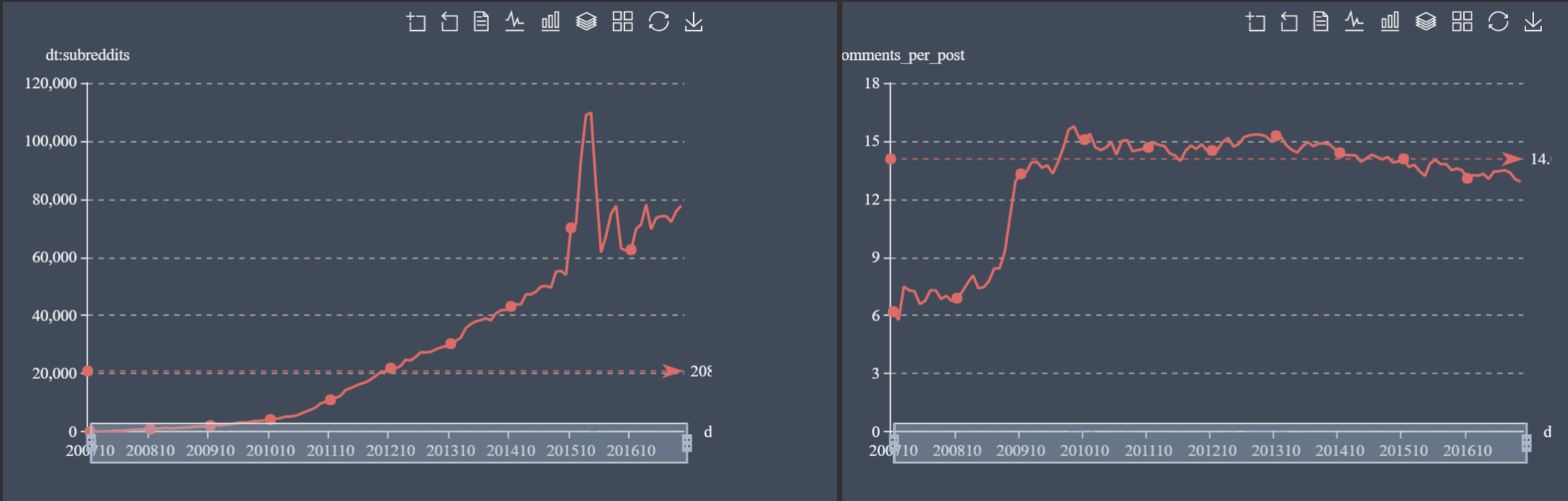
It impressive to see the constant growth in comments (to 70mln per month by the end of 2016) and authors (to 3.5mln for the same time period). There is something interesting happening with subreddits, which jump up and down. It’s interesting to see that the average count of comments per post stays stable, with a slight decline to 13 comments/post by the end of 2016.
Now let’s check most popular subreddits:
|
1 2 3 4 5 |
SELECT subreddit,count(*) cnt FROM commententry1 GROUP BY subreddit ORDER BY cnt DESC limit 100 DRAW_TREEMAP { path:'subreddit.cnt' } |
and using a treemap (available in Tabix.io):

We can measure subreddits that get the biggest increase in comments in 2016 compared to 2015:
|
1 2 3 4 5 |
SELECT subreddit,cntnew-cntold diff FROM (SELECT subreddit,count(*) cntnew FROM commententry1 WHERE toYear(created_date)=2016 GROUP BY subreddit) ALL INNER JOIN (SELECT subreddit,count(*) cntold FROM commententry1 WHERE toYear(created_date)=2015 GROUP BY subreddit) USING (subreddit) ORDER BY diff DESC LIMIT 50 DRAW_TREEMAP { path:'subreddit.diff' } |

Obviously, Reddit was affected by the United States Presidential Election 2016, but not just that. The gaming community saw an increase in Overwatch, PokemonGO and Dark Souls 3.
Now we can try to run our own DB-Ranking, but only based on Reddit comments. This is how I can do this for MySQL, PostgreSQL and MongoDB:
|
1 2 3 4 5 6 |
SELECT toStartOfQuarter(created_date) Quarter, sum(if(positionCaseInsensitive(body,'mysql')>0,1,0)) mysql, sum(if(positionCaseInsensitive(body,'postgres')>0,1,0)) postgres, sum(if(positionCaseInsensitive(body,'mongodb')>0,1,0)) mongodb FROM commententry1 GROUP BY Quarter ORDER BY Quarter; |
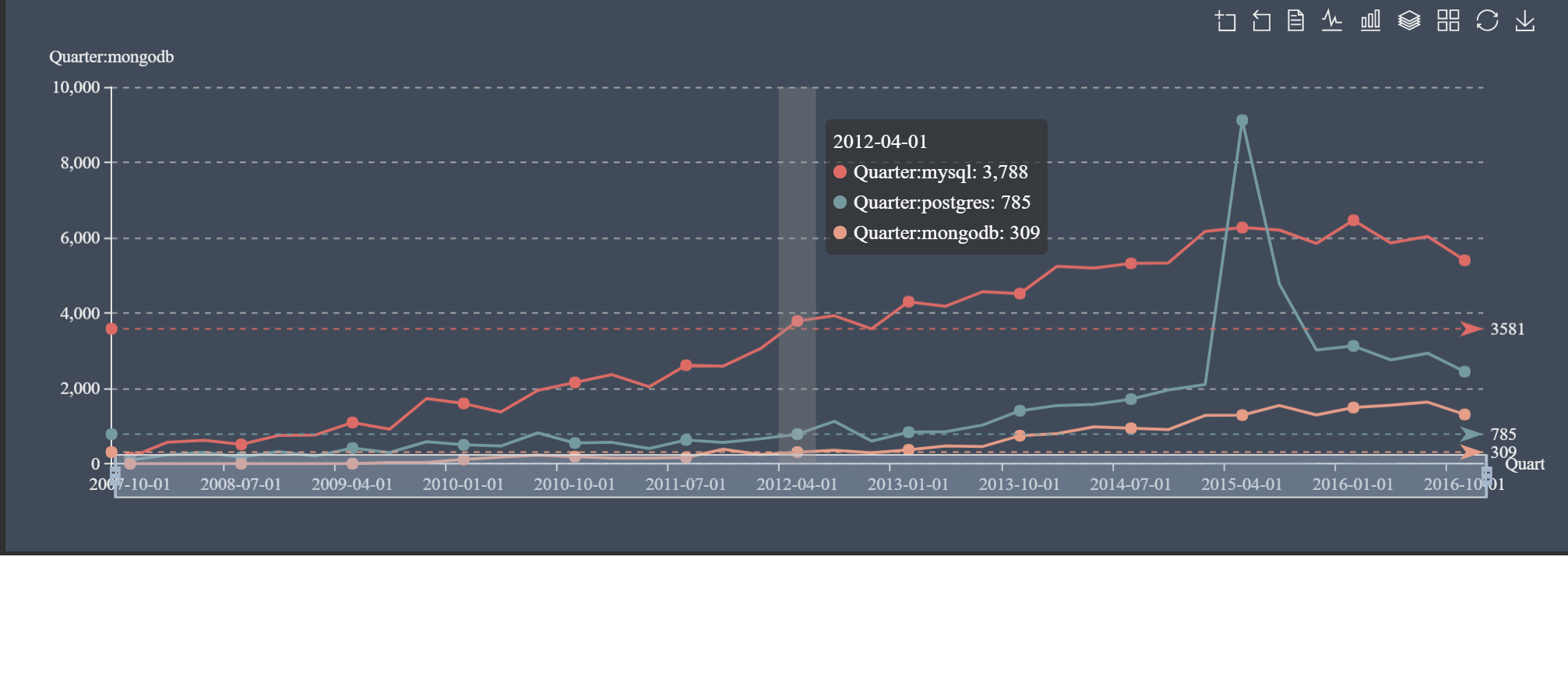
I would say the result is aligned with https://db-engines.com/en/ranking, where MySQL is the most popular among the three, followed by PostgreSQL and then MongoDB. There is an interesting spike for PostgreSQL in the second quarter in 2015, caused by a bot in “leagueoflegend” tournaments. The bot was actively announcing that it is powered by PostgreSQL in the comments, like this: http://reddit.com/r/leagueoflegends/comments/37cvc3/c/crln2ef.
To highlight more ClickHouse features: along with standard SQL functions, it provides a variety of statistical functions (for example, Quantile calculations). We can try to see the distribution of the number of comments left by authors:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT quantileExact(0.1)(cnt), quantileExact(0.2)(cnt), quantileExact(0.3)(cnt), quantileExact(0.4)(cnt), quantileExact(0.5)(cnt), quantileExact(0.6)(cnt), quantileExact(0.7)(cnt), quantileExact(0.8)(cnt), quantileExact(0.9)(cnt), quantileExact(0.99)(cnt) FROM ( SELECT author, count(*) AS cnt FROM commententry1 WHERE author != '[deleted]' GROUP BY author ) |
The result is:
|
1 2 3 4 5 6 7 8 9 10 |
quantileExact(0.1)(cnt) - 1 quantileExact(0.2)(cnt) - 1 quantileExact(0.3)(cnt) - 1 quantileExact(0.4)(cnt) - 2 quantileExact(0.5)(cnt) - 4 quantileExact(0.6)(cnt) - 7 quantileExact(0.7)(cnt) - 16 quantileExact(0.8)(cnt) - 42 quantileExact(0.9)(cnt) - 160 quantileExact(0.99)(cnt) - 2271 |
Which means that 30% of authors left only one comment, and 50% of authors left four comments or less.
In general, ClickHouse was a pleasure to use when running analytical queries. However, I should note the missing support of WINDOW functions is a huge limitation. Even MySQL 8.0, which recently was released as RC, provides support for WINDOW functions. I hope ClickHouse will implement this as well.
Resources
RELATED POSTS





Few additions:
1. To calculate multiple quantiles in a single pass, you may use quantiles aggregate function (note the ‘s’).
Example: quantilesExact(0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.99)
Also for this dataset it is perfectly Ok to use “quantilesTiming” aggregate function.
2. There is -If combinator for aggregate functions, and you may write
sumIf(x, condition) instead of sum(if(condition, x, 0))
For the simple case, when you just count number of rows, where the condition is met, you may write just
sum(condition)