
In my previous blog post, I talked about new general tablespaces in MySQL 8.0. Recently MySQL 8.0.3-rc was released, which includes a new data dictionary. My goal is to create one million tables in MySQL and test the performance.
Q: Why million tables in MySQL? Is it even realistic? How does this happen?
Usually, millions of tables in MySQL is a result of “a schema per customer” Software as a Service (SaaS) approach. For the purposes of customer data isolation (security) and logical data partitioning (performance), each “customer” has a dedicated schema. You can think of a WordPress hosting service (or any CMS based hosting) where each customer has their own dedicated schema. With 10K customers per MySQL server, we could end up with millions of tables.
Q: Should you design an application with >1 million tables?
Having separate tables is one of the easiest designs for a multi-tenant or SaaS application, and makes it easy to shard and re-distribute your workload between servers. In fact, the table-per-customer or schema-per-customer design has the quickest time-to-market, which is why we see it a lot in consulting. In this post, we are not aiming to cover the merits of should you do this (if your application has high churn or millions of free users, for example, it might not be a good idea). Instead, we will focus on if the new data dictionary provides relief to a historical pain point.
Q: Why is one million tables a problem?
The main issue results from the fact that MySQL needs to open (and eventually close) the table structure file (FRM file). With one million tables, we are talking about at least one million files. Originally MySQL fixed it with table_open_cache and table_definition_cache. However, the maximum value for table_open_cache is 524288. In addition, it is split into 16 partitions by default (to reduce the contention). So it is not ideal. MySQL 8.0 has removed FRM files for InnoDB, and will now allow you to create general tablespaces. I’ve demonstrated how we can create tablespace per customer in MySQL 8.0, which is ideal for “schema-per-customer” approach (we can move/migrate one customer data to a new server by importing/exporting the tablespace).
Recently, I’ve created a test with one million tables. The test creates 10K databases, and each database contains 100 tables. To use a standard benchmark I’ve employed sysbench table structure.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> select count(*) from information_schema.schemata where schema_name like 'test_sbtest%'; +----------+ | count(*) | +----------+ | 10000 | +----------+ 1 row in set (0.01 sec) mysql> select count(*) from information_schema.tables where table_schema like 'test_sbtest%'; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (4.61 sec) |
This also creates a huge overhead: with one million tables we have ~two million files. Each .frm file and .ibd file size sums up to 175G:
|
1 2 |
# du -sh /ssd/mysql_57 175G /ssd/mysql_57 |
Now I’ve used sysbench Lua script to insert one row randomly into one table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
pathtest = "/usr/share/sysbench/tests/include/oltp_legacy/" if pathtest then dofile(pathtest .. "common.lua") else require("common") end function event() local table_name local i local c_val local k_val local pad_val local oltp_tables_count = 100 local oltp_db_count = 10000 table_name = "test_sbtest_" .. sb_rand_uniform(1, oltp_db_count) .. ".sbtest".. sb_rand_uniform(1, oltp_tables_count) k_val = sb_rand(1, oltp_table_size) c_val = sb_rand_str([[ ###########-###########-###########-###########-###########-###########-###########-###########-###########-###########]]) pad_val = sb_rand_str([[ ###########-###########-###########-###########-###########]]) rs = db_query("INSERT INTO " .. table_name .. " (id, k, c, pad) VALUES " .. string.format("(%d, %d, '%s', '%s')", i, k_val, c_val, pad_val)) end end |
With:
|
1 2 |
local oltp_tables_count = 100 local oltp_db_count = 10000 |
Sysbench will choose one table randomly out of one million. With oltp_tables_count = 1 and oltp_db_count = 100, it will only choose the first table (sbtest1) out of the first 100 databases (randomly).
As expected, MySQL 5.7 has a huge performance degradation when going across one million tables. When running a script that only inserts data into 100 random tables, we can see ~150K transactions per second. When the data is inserted in one million tables (chosen randomly) performance drops to 2K (!) transactions per second:
Insert into 100 random tables:
|
1 2 3 4 5 6 7 8 9 10 |
SQL statistics: queries performed: read: 0 write: 16879188 other: 0 total: 16879188 transactions: 16879188 (140611.72 per sec.) queries: 16879188 (140611.72 per sec.) ignored errors: 0 (0.00 per sec.) reconnects: 0 (0.00 per sec.) |
Insert into one million random tables:
|
1 2 3 4 5 6 7 8 9 10 |
SQL statistics: queries performed: read: 0 write: 243533 other: 0 total: 243533 transactions: 243533 (2029.21 per sec.) queries: 243533 (2029.21 per sec.) ignored errors: 0 (0.00 per sec.) reconnects: 0 (0.00 per sec.) |
This is expected. Here I’m testing the worst-case scenario, where we can’t keep all table open handlers and table definitions in cache (memory) since the table_open_cache and table_definition_cache both have a limit of 524288.
Also, normally we can expect a huge skew between access to the tables. There can be only 20% active customers (80-20 rule), meaning that we can only expect active access to 2K databases. In addition, there will be old or unused tables so we can expect around 100K or less of active tables.
The above results are from this server:
|
1 2 3 |
Processors | 64xGenuine Intel(R) CPU @ 2.00GHz Memory Total | 251.8G Disk | Samsung 950 Pro PCIE SSD (nvme) |
Sysbench script:
|
1 |
sysbench $conn --report-interval=1 --num-threads=32 --max-requests=0 --max-time=600 --test=/root/drupal_demo/insert_custom.lua run |
My.cnf:
|
1 2 3 4 5 6 7 8 9 |
innodb_buffer_pool_size = 100G innodb_io_capacity=20000 innodb_flush_log_at_trx_commit = 0 innodb_log_file_size = 2G innodb_flush_method=O_DIRECT_NO_FSYNC skip-log-bin open_files_limit=1000000 table_open_cache=524288 table_definition_cache=524288 |
In MySQL 8.0 is it easy and logical to create one general tablespace per each schema (it will host all tables in this schema). In MySQL 5.7, general tablespaces are available – but there are still .frm files.
I’ve used the following script to create 100 tables in one schema all in one tablespace:
|
1 2 3 4 5 |
mysql test -e "CREATE TABLESPACE t ADD DATAFILE 't.ibd' engine=InnoDB;" for i in {1..10000} do mysql test -e "create table ab$i(i int) tablespace t" done |
The new MySQL 8.0.3-rc also uses the new data dictionary, so all MyISAM tables in the mysql schema are removed and all metadata is stored in additional mysql.ibd file.
Creating InnoDB tables fast enough can be a task by itself. Stewart Smith published a blog post a while ago where he focused on optimizing time to create 30K tables in MySQL.
The problem is that after creating an .ibd file, MySQL needs to “fsync” it. However, when creating a table inside the tablespace, there is no fsync. I’ve created a simple script to create tables in parallel, one thread per database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#/bin/bash function do_db { mysql -vvv -e "create database $db"; mysql -vvv $db -e "CREATE TABLESPACE $db ADD DATAFILE '$db.ibd' engine=InnoDB;" for i in {1..100} do table="CREATE TABLE sbtest$i ( id int(10) unsigned NOT NULL AUTO_INCREMENT, k int(10) unsigned NOT NULL DEFAULT '0', c varchar(120) NOT NULL DEFAULT '', pad varchar(60) NOT NULL DEFAULT '', PRIMARY KEY (id), KEY k_1 (k) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 tablespace $db;" mysql $db -e "$table" done } c=0 for m in {1..100} do for i in {1..100} do let c=$c+1 echo $c db="test_sbtest_$c" do_db & done wait done |
That script works perfectly in MySQL 8.0.1-dmr and creates one million tables in 25 minutes and 28 seconds (1528 seconds). That is ~654 tables per second. That is significantly faster than ~30 tables per second in the original Stewart’s test and 2x faster than a test where all fsyncs were artificially disabled using libeat-my-data library.
Unfortunately, in MySQL 8.0.3-rc some regression was introduced. In MySQL 8.0.3-rc I can see heavy mutex contention, and the table creation speed dropped from 25 minutes to ~280 minutes. I’ve filed a bug report: performance regression: “create table” speed and scalability in 8.0.3.
With general tablespaces and no .frm files, the size on disk decreased:
|
1 2 3 4 |
# du -h -d1 /ssd/ 147G /ssd/mysql_801 119G /ssd/mysql_803 175G /ssd/mysql_57 |
Please note though that in MySQL 8.0.3-rc, with new native data dictionary, the size on disk increased as it needs to write additional information (Serialized Dictionary Information, SDI) to the tablespace files:
The general mysql data dictionary in MySQL 8.0.3 is 6.6Gb:
|
1 |
6.6G /ssd/mysql/mysql.ibd |
I’ve repeated the same test I’ve done for MySQL 5.7 in MySQL 8.0.3-rc (and in 8.0.1-dmr), but using general tablespace. I created 10K databases (=10K tablespace files), each database has100 tables and each database resides in its own tablespace.
There are two new tablespace level caches we can use in MySQL 8.0: tablespace_definition_cache and schema_definition_cache:
|
1 2 |
tablespace_definition_cache = 15000 schema_definition_cache = 524288 |
Unfortunately, with one million random table accesses in MySQL 8.0 (both 8.0.1 and 8.0.3), we can still see that it stalls on opening tables (even with no .frm files and general tablespaces):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
mysql> select conn_id, current_statement, state, statement_latency, lock_latency from sys.processlist where current_statement is not null and conn_id <> CONNECTION_ID(); +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ | conn_id | current_statement | state | statement_latency | lock_latency | +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ | 199 | INSERT INTO test_sbtest_9749.s ... 8079-53209333270-93105555128') | Opening tables | 4.45 ms | 0 ps | | 198 | INSERT INTO test_sbtest_1863.s ... 9574-29782886623-39251573705') | Opening tables | 9.95 ms | 5.67 ms | | 189 | INSERT INTO test_sbtest_3948.s ... 9365-63502117132-66650064067') | Opening tables | 16.29 ms | 15.38 ms | | 190 | INSERT INTO test_sbtest_6885.s ... 8436-41291265610-60894472357') | Opening tables | 13.78 ms | 9.52 ms | | 191 | INSERT INTO test_sbtest_247.sb ... 7467-89459234028-92064334941') | Opening tables | 8.36 ms | 3.18 ms | | 192 | INSERT INTO test_sbtest_9689.s ... 8058-74586985382-00185651578') | Opening tables | 6.89 ms | 0 ps | | 193 | INSERT INTO test_sbtest_8777.s ... 1900-02582963670-01868315060') | Opening tables | 7.09 ms | 5.70 ms | | 194 | INSERT INTO test_sbtest_9972.s ... 9057-89011320723-95018545652') | Opening tables | 9.44 ms | 9.35 ms | | 195 | INSERT INTO test_sbtest_6977.s ... 7902-29158428721-66447528241') | Opening tables | 7.82 ms | 789.00 us | | 196 | INSERT INTO test_sbtest_129.sb ... 2091-86346366083-87657045906') | Opening tables | 13.01 ms | 7.30 ms | | 197 | INSERT INTO test_sbtest_1418.s ... 6581-90894769279-68213053531') | Opening tables | 16.35 ms | 10.07 ms | | 208 | INSERT INTO test_sbtest_4757.s ... 4592-86183240946-83973365617') | Opening tables | 8.66 ms | 2.84 ms | | 207 | INSERT INTO test_sbtest_2152.s ... 5459-55779113235-07063155183') | Opening tables | 11.08 ms | 3.89 ms | | 212 | INSERT INTO test_sbtest_7623.s ... 0354-58204256630-57234862746') | Opening tables | 8.67 ms | 2.80 ms | | 215 | INSERT INTO test_sbtest_5216.s ... 9161-37142478639-26288001648') | Opening tables | 9.72 ms | 3.92 ms | | 210 | INSERT INTO test_sbtest_8007.s ... 2999-90116450579-85010442132') | Opening tables | 1.33 ms | 0 ps | | 203 | INSERT INTO test_sbtest_7173.s ... 2718-12894934801-25331023143') | Opening tables | 358.09 us | 0 ps | | 209 | INSERT INTO test_sbtest_1118.s ... 8361-98642762543-17027080501') | Opening tables | 3.32 ms | 0 ps | | 219 | INSERT INTO test_sbtest_5039.s ... 1740-21004115002-49204432949') | Opening tables | 8.56 ms | 8.44 ms | | 202 | INSERT INTO test_sbtest_8322.s ... 8686-46403563348-31237202393') | Opening tables | 1.19 ms | 0 ps | | 205 | INSERT INTO test_sbtest_1563.s ... 6753-76124087654-01753008993') | Opening tables | 9.62 ms | 2.76 ms | | 213 | INSERT INTO test_sbtest_5817.s ... 2771-82142650177-00423653942') | Opening tables | 17.21 ms | 16.47 ms | | 216 | INSERT INTO test_sbtest_238.sb ... 5343-25703812276-82353892989') | Opening tables | 7.24 ms | 7.20 ms | | 200 | INSERT INTO test_sbtest_2637.s ... 8022-62207583903-44136028229') | Opening tables | 7.52 ms | 7.39 ms | | 204 | INSERT INTO test_sbtest_9289.s ... 2786-22417080232-11687891881') | Opening tables | 10.75 ms | 9.01 ms | | 201 | INSERT INTO test_sbtest_6573.s ... 0106-91679428362-14852851066') | Opening tables | 8.43 ms | 7.03 ms | | 217 | INSERT INTO test_sbtest_1071.s ... 9465-09453525844-02377557541') | Opening tables | 8.42 ms | 7.49 ms | | 206 | INSERT INTO test_sbtest_9588.s ... 8804-20770286377-79085399594') | Opening tables | 8.02 ms | 7.50 ms | | 211 | INSERT INTO test_sbtest_4657.s ... 4758-53442917995-98424096745') | Opening tables | 16.62 ms | 9.76 ms | | 218 | INSERT INTO test_sbtest_9672.s ... 1537-13189199316-54071282928') | Opening tables | 10.01 ms | 7.41 ms | | 214 | INSERT INTO test_sbtest_1391.s ... 9241-84702335152-38653248940') | Opening tables | 21.34 ms | 15.54 ms | | 220 | INSERT INTO test_sbtest_6542.s ... 7778-65788940102-87075246009') | Opening tables | 2.96 ms | 0 ps | +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ 32 rows in set (0.11 sec) |
And the transactions per second drops to ~2K.
Here I’ve expected different behavior. With the .frm files gone and with tablespace_definition_cache set to more than 10K (we have only 10K tablespace files), I’ve expected that MySQL does not have to open and close files. It looks like this is not the case.
I can also see the table opening (since the server started):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> show global status like '%open%'; +----------------------------+-----------+ | Variable_name | Value | +----------------------------+-----------+ | Com_ha_open | 0 | | Com_show_open_tables | 0 | | Innodb_num_open_files | 10040 | | Open_files | 0 | | Open_streams | 0 | | Open_table_definitions | 524288 | | Open_tables | 499794 | | Opened_files | 22 | | Opened_table_definitions | 1220904 | | Opened_tables | 2254648 | | Slave_open_temp_tables | 0 | | Table_open_cache_hits | 256866421 | | Table_open_cache_misses | 2254643 | | Table_open_cache_overflows | 1254766 | +----------------------------+-----------+ |
This is easier to see on the graphs from PMM. Insert per second for the two runs (both running 16 threads):
As we can see, the first run is dong 50K -100K inserts/second. Second run is only limited to ~2.5 inserts per second:
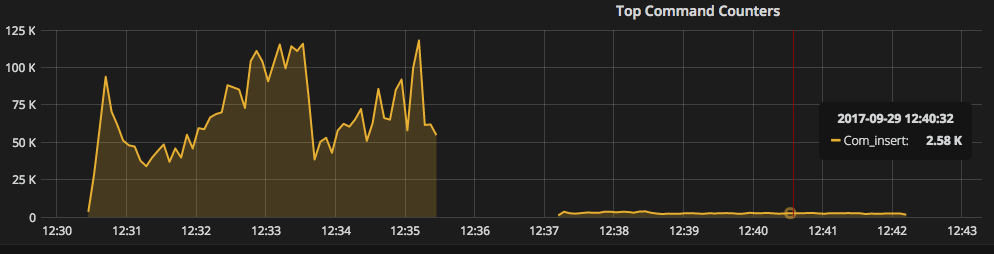
“Table open cache misses” grows significantly after the start of the second benchmark run:
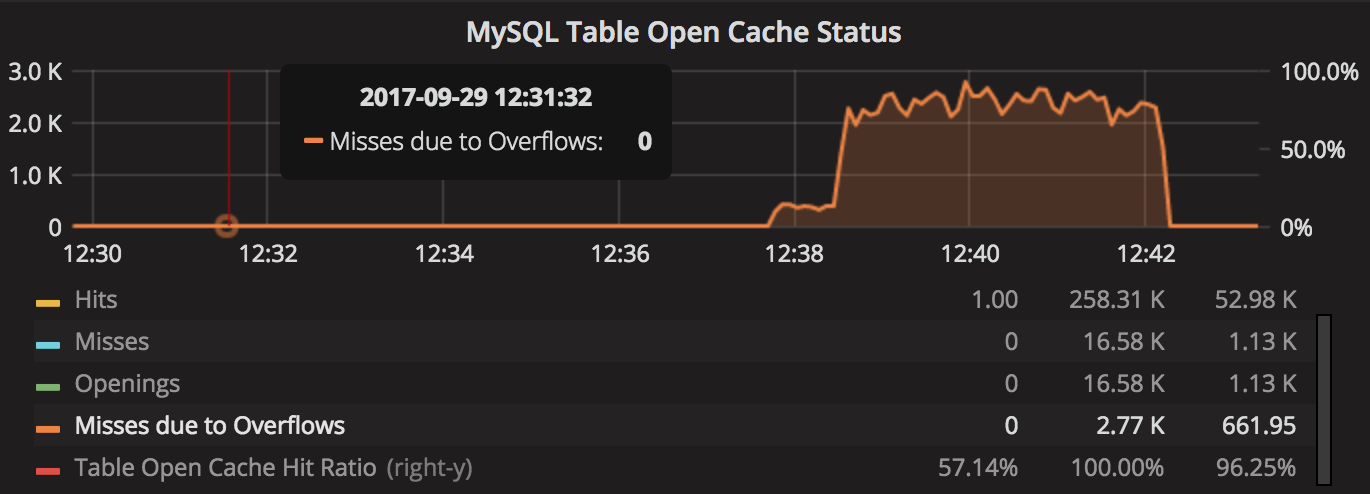
As we can see, MySQL performs ~1.1K table definition openings per second and has ~2K table cache misses due to the overflow:
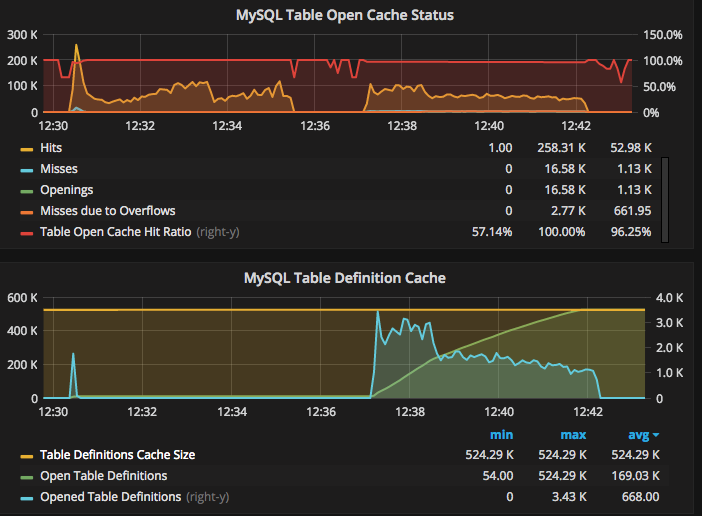
When inserting against only 1K random tables (one specific table in a random database, that way we almost guarantee that one thread will always write to a different tablespace file), the table_open_cache got warmed up quickly. After a couple of seconds, the sysbench test starts showing > 100K tps. The processlist looks much better (compare the statement latency and lock latency to the above as well):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
mysql> select conn_id, current_statement, state, statement_latency, lock_latency from sys.processlist where current_statement is not null and conn_id <> CONNECTION_ID(); +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ | conn_id | current_statement | state | statement_latency | lock_latency | +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ | 253 | INSERT INTO test_sbtest_3293.s ... 2282-95400708146-84684851551') | starting | 22.72 us | 0 ps | | 254 | INSERT INTO test_sbtest_3802.s ... 4030-35983148190-23616685226') | update | 62.88 us | 45.00 us | | 255 | INSERT INTO test_sbtest_5290.s ... 2361-58374942527-86207214617') | Opening tables | 36.07 us | 0 ps | | 256 | INSERT INTO test_sbtest_5684.s ... 4717-34992549120-04746631452') | Opening tables | 37.61 us | 37.00 us | | 257 | INSERT INTO test_sbtest_5088.s ... 5637-75275906887-76112520982') | starting | 22.97 us | 0 ps | | 258 | INSERT INTO test_sbtest_1375.s ... 8592-24036624620-65536442287') | query end | 98.66 us | 35.00 us | | 259 | INSERT INTO test_sbtest_8764.s ... 8566-02569157908-49891861265') | Opening tables | 47.13 us | 37.00 us | | 260 | INSERT INTO test_sbtest_560.sb ... 2605-08226572929-25889530906') | query end | 155.64 us | 38.00 us | | 261 | INSERT INTO test_sbtest_7776.s ... 0243-86335905542-37976752368') | System lock | 46.68 us | 32.00 us | | 262 | INSERT INTO test_sbtest_6551.s ... 5496-19983185638-75401382079') | update | 74.07 us | 40.00 us | | 263 | INSERT INTO test_sbtest_7765.s ... 5428-29707353898-77023627427') | update | 71.35 us | 45.00 us | | 265 | INSERT INTO test_sbtest_5771.s ... 7065-03531013976-67381721569') | query end | 138.42 us | 39.00 us | | 266 | INSERT INTO test_sbtest_8603.s ... 7158-66470411444-47085285977') | update | 64.00 us | 36.00 us | | 267 | INSERT INTO test_sbtest_3983.s ... 5039-55965227945-22430910215') | update | 21.04 ms | 39.00 us | | 268 | INSERT INTO test_sbtest_8186.s ... 5418-65389322831-81706268892') | query end | 113.58 us | 37.00 us | | 269 | INSERT INTO test_sbtest_1373.s ... 1399-08304962595-55155170406') | update | 131.97 us | 59.00 us | | 270 | INSERT INTO test_sbtest_7624.s ... 0589-64243675321-62971916496') | query end | 120.47 us | 38.00 us | | 271 | INSERT INTO test_sbtest_8201.s ... 6888-31692084119-80855845726') | query end | 109.97 us | 37.00 us | | 272 | INSERT INTO test_sbtest_7054.s ... 3674-32329064814-59707699237') | update | 67.99 us | 35.00 us | | 273 | INSERT INTO test_sbtest_3019.s ... 1740-35410584680-96109859552') | update | 5.21 ms | 33.00 us | | 275 | INSERT INTO test_sbtest_7657.s ... 4985-72017519764-59842283878') | update | 88.91 us | 48.00 us | | 274 | INSERT INTO test_sbtest_8606.s ... 0580-38496560423-65038119567') | freeing items | NULL | 37.00 us | | 276 | INSERT INTO test_sbtest_9349.s ... 0295-94997123247-88008705118') | starting | 25.74 us | 0 ps | | 277 | INSERT INTO test_sbtest_3552.s ... 2080-59650597118-53885660147') | starting | 32.23 us | 0 ps | | 278 | INSERT INTO test_sbtest_3832.s ... 1580-27778606266-19414961452') | freeing items | 194.14 us | 51.00 us | | 279 | INSERT INTO test_sbtest_7685.s ... 0234-22016898044-97277319766') | update | 62.66 us | 40.00 us | | 280 | INSERT INTO test_sbtest_6026.s ... 2629-36599580811-97852201188') | Opening tables | 49.41 us | 37.00 us | | 281 | INSERT INTO test_sbtest_8273.s ... 7957-39977507737-37560332932') | update | 92.56 us | 36.00 us | | 283 | INSERT INTO test_sbtest_8584.s ... 7604-24831943860-69537745471') | starting | 31.20 us | 0 ps | | 284 | INSERT INTO test_sbtest_3787.s ... 1644-40368085836-11529677841') | update | 100.41 us | 40.00 us | +---------+-------------------------------------------------------------------+----------------+-------------------+--------------+ 30 rows in set (0.10 sec) |
What about the 100K random tables? That should fit into the table_open_cache. At the same time, the default 16 table_open_cache_instances split 500K table_open_cache, so each bucket is only ~30K. To fix that, I’ve set table_open_cache_instances = 4 and was able to get ~50K tps average. However, the contention inside the table_open_cache seems to stall the queries:
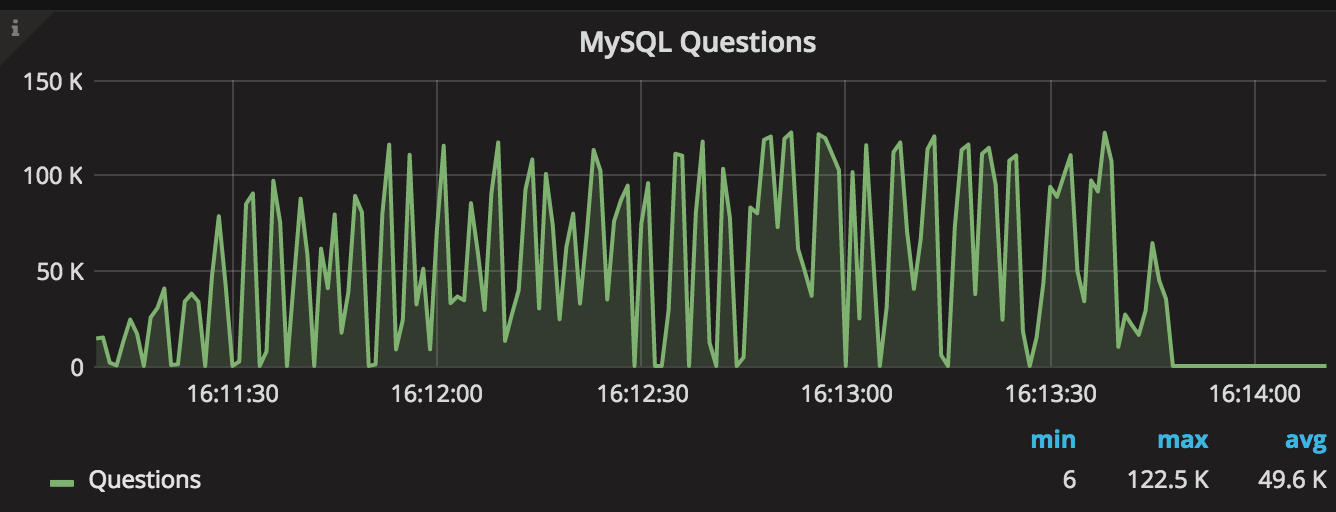
There are only a very limited amount of table openings:
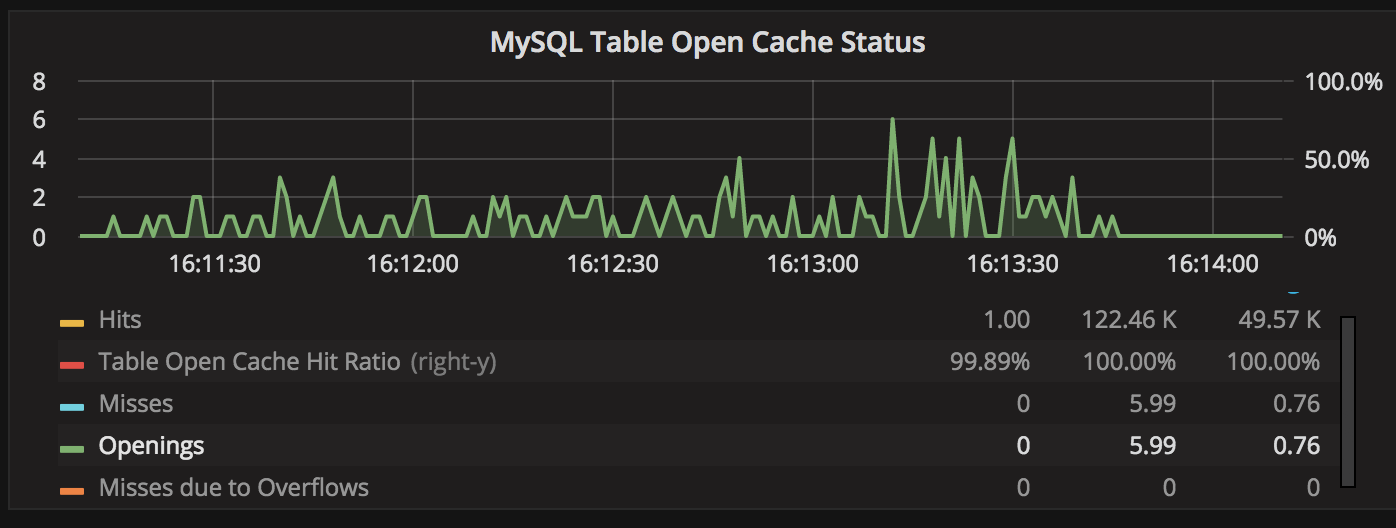
MySQL 8.0 general tablespaces looks very promising. It is finally possible to create one million tables in MySQL without the need to create two million files. Actually, MySQL 8 can handle many tables very well as long as table cache misses are kept to a minimum.
At the same time, the problem with “Opening tables” (worst case scenario test) still persists in MySQL 8.0.3-rc and limits the throughput. I expected to see that MySQL does not have to open/close the table structure file. I also hope the create table regression bug is fixed in the next MySQL 8.0 version.
I’ve not tested other new features in the new data dictionary in 8.0.3-rc: i.e., atomic DDL (InnoDB now supports atomic DDL, which ensures that DDL operations are either committed in their entirety or rolled back in case of an unplanned server stoppage). That is the topic of the next blog post.
Resources
RELATED POSTS





Hello!
Regarding “Opening tables” state.
Yes, after .frm files removal we no longer need to open them when table definition is loaded into table definition cache and TABLE_SHARE object is constructed. However we still need to construct TABLE_SHARE object from the information in the data-dictionary. Plus we still need to construct TABLE object and create “handler” object and “open” table in SE (even though this might not lead to opening of files in reality) for each table instance used by some statement (if it is not in open tables cache already).
As you have mentioned both table definition cache and open tables caches are limited to 524288 elements in your case. So test which tries to access 1mil of tables randomly will result in lots of cache misses (and effect will be even worse then one might expect due to open tables cache partitioning).
But do we really have workloads which access 1mil of tables uniformly randomly in practice?
Without some kind of temporal or connection locality at all?
At my previous company, we had to manage over 160,000 tables per MySQL instance, because we separated customer data into one schema per customer (for security and some manageability). The workload was not strictly uniform, because different customers used the service at different rates. But their usage was unpredictable.
Thank Alex, very interesting. I was wondering if you are testing performance differences with information_schema.TABLES and similar system tables.
Federico
I would like to see more benchmarks like this on more practical queries about the new data dictionary. Things like https://www.percona.com/blog/2008/02/04/finding-out-largest-tables-on-mysql-server/ or typical metadata-querying information.
Hi,
Your post is very interesting, I’m glad to know about new data dictionary.
Well, I would like to know how long MySQL 5.7 take to create one million tables compared below time.
> That script works perfectly in MySQL 8.0.1-dmr and creates one million tables in 25 minutes and 28 seconds (1528 seconds).
Regard,