
A lot of things have been said about UUID, and storing UUID in an optimized way. Now that we have generated columns, we can store the decomposed information inside the UUID and merge it again with generated columns. This blog post demonstrates this process.
First, I used a simple table with one char field that I called uuid_char to establish a base case. I used this table with and without a primary key:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE uuid_char ( uuid char(36) CHARACTER SET utf8 NOT NULL, ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE uuid_char_pk ( uuid char(36) CHARACTER SET utf8 NOT NULL, PRIMARY KEY (uuid) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; |
I performed the tests on a local VM over MySQL 5.7.17 for 30 seconds, with only two threads, because I wanted to just compare the executions:
|
1 2 3 4 5 6 7 8 9 10 11 |
sysbench --oltp-table-size=100000000 --test=/usr/share/doc/sysbench/tests/db/insert_uuid_generated_columns.uuid_char.lua --oltp-tables-count=4 --num-threads=2 --mysql-user=root --max-requests=5000000 --report-interval=5 --max-time=30 --mysql-db=generatedcolumn run |
One pair of executions is with the UUID generated by sysbench, which simulates the UUID that comes from the app:
|
1 |
rs = db_query("INSERT INTO uuid_char (uuid) VALUES " .. string.format("('%s')",c_val)) |
An alternative execution is for when the UUID is generated by the MySQL function uuid():
|
1 |
rs = db_query("INSERT INTO uuid_char (uuid) VALUES (uuid())") |
Below we can see the results:
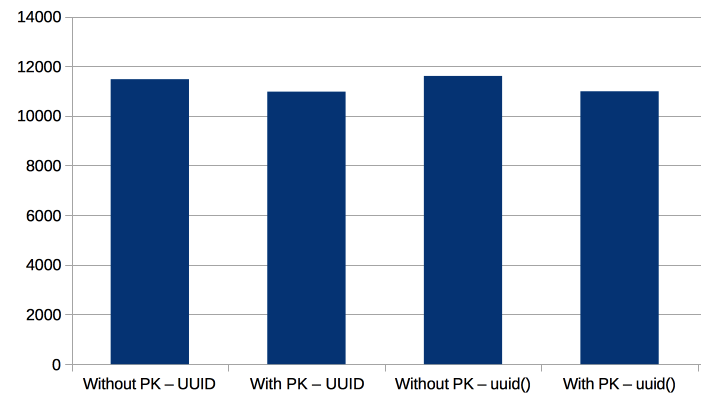
The inserts are faster without a PK (but only by 5%), and using the uuid() function doesn’t impact performance.
Now, let’s see the alternative method, which is decomposing the UUID. It has four main information sets:
The structure of the table that we’ll use is:
|
1 2 3 4 5 6 |
CREATE TABLE `uuid_generated` ( `timestamp` decimal(18,7) unsigned NOT NULL, `mac` bigint(20) unsigned NOT NULL, `temp_uniq` binary(2) NOT NULL, PRIMARY KEY (`timestamp`,`mac`,`temp_uniq`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; |
To understand how a UUID is unwrapped, I used this store procedure (which receives a UUID and inserts it into the table):
|
1 2 3 4 5 6 7 8 |
CREATE PROCEDURE ins_generated_uuid (uuid char(38)) begin set @hex_timestamp = concat(substring(uuid, 16, 3), substring(uuid, 10, 4), substring(uuid, 1, 8)); set @timestamp = concat(conv(@hex_timestamp,16,10)div 10000000 - (141427 * 24 * 60 * 60),'.',right(conv(@hex_timestamp,16,10),7)); set @mac = conv(right(uuid,12),16,10); set @temp_uniq = unhex(substring(uuid,20,4)); insert into uuid_generated (timestamp,mac,temp_uniq) values (@timestamp,@mac,@temp_uniq); end ;; |
Explanation:
If I wanted to get the UUID again, I can use these two generated columns:
|
1 2 |
`hex_timestamp` char(40) GENERATED ALWAYS AS (conv(((`timestamp` * 10000000) + (((141427 * 24) * 60) * 600000000)),10,16)) VIRTUAL, `uuid_generated` char(38) GENERATED ALWAYS AS (concat(right(`hex_timestamp`,8),'-',substr(`hex_timestamp`,4,4),'-1',left(`hex_timestamp`,3),'-',convert(hex(`temp_uniq`) using utf8),'-',lpad(conv(`mac`,10,16),12,'0'))) VIRTUAL, |
We performed tests over five scenarios:
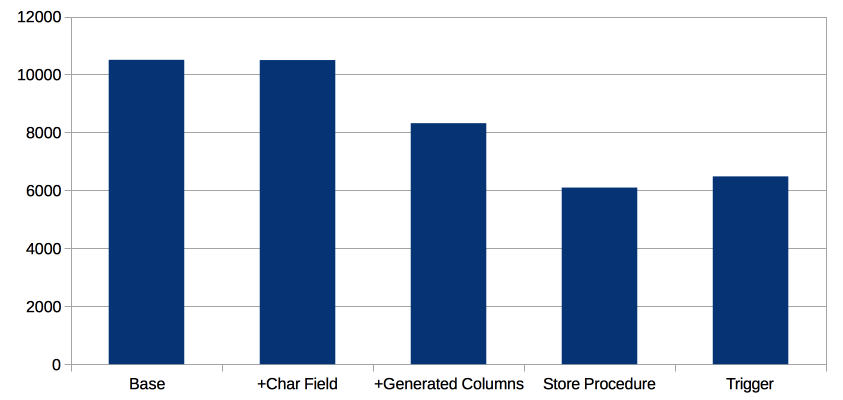
The difference between the Base and the previous table structure with Primary Keys is very small. So, the new basic structure has no impact on performance.
We see that Base and +Char Field have the same performance. So leaving a char field has no performance impact (it just uses more disk space).
Using generated columns impact performance. This is expected, as the columns are generated to validate the type before the row is inserted.
Finally, the use of triggers and store procedure has the same impact in performance.
These are the three structures to the tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
CREATE TABLE `uuid_generated` ( `timestamp` decimal(18,7) unsigned NOT NULL, `mac` bigint(20) unsigned NOT NULL, `temp_uniq` binary(2) NOT NULL, PRIMARY KEY (`timestamp`,`mac`,`temp_uniq`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE `uuid_generated_char` ( `timestamp` decimal(18,7) unsigned NOT NULL, `mac` bigint(20) unsigned NOT NULL, `temp_uniq` binary(2) NOT NULL, `uuid` char(38) DEFAULT NULL, PRIMARY KEY (`timestamp`,`mac`,`temp_uniq`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; CREATE TABLE `uuid_generated_char_plus` ( `timestamp` decimal(18,7) unsigned NOT NULL, `mac` bigint(20) unsigned NOT NULL, `temp_uniq` binary(2) NOT NULL, `uuid` char(38) DEFAULT NULL, `hex_timestamp` char(40) GENERATED ALWAYS AS (conv(((`timestamp` * 10000000) + (((141427 * 24) * 60) * 600000000)),10,16)) VIRTUAL, `uuid_generated` char(38) GENERATED ALWAYS AS (concat(right(`hex_timestamp`,8),'-',substr(`hex_timestamp`,4,4),'-1',left(`hex_timestamp`,3),'-',convert(hex(`temp_uniq`) using utf8),'-',lpad(conv(`mac`,10,16),12,'0'))) VIRTUAL, PRIMARY KEY (`timestamp`,`mac`,`temp_uniq`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; |
And this is the trigger:
|
1 2 3 4 5 6 7 8 9 10 11 |
DROP TRIGGER IF EXISTS ins_generated_uuid; delimiter ;; CREATE TRIGGER ins_uuid_generated BEFORE INSERT ON uuid_generated FOR EACH ROW begin set @hex_timestamp = concat(substring(NEW.uuid, 16, 3), substring(NEW.uuid, 10, 4), substring(NEW.uuid, 1, 8)); set NEW.timestamp = concat(conv(@hex_timestamp,16,10)div 10000000 - (141427 * 24 * 60 * 60),'.',right(conv(@hex_timestamp,16,10),7)); set NEW.mac = conv(right(NEW.uuid,12),16,10); set NEW.temp_uniq = unhex(substring(NEW.uuid,20,4)); end ;; delimiter ; |
Decomposing the UUID is an alternative to storing them in order, but it won’t speed up inserts. It is simpler to execute queries over a range of dates, and look at the row for a particular device, as you will be able to use the MAC (it is recommended to add an index for it). Generated columns give you the possibility to build the UUID back in just one string.





How big was innodb_buffer_pool_size? How big was the table? If the table was smaller than the buffer_pool, you have not yet gotten to the interesting use case.
As far as inserting into a BTree index, UUID() is essentially a ‘random’ string. Once the uuid index (the PRIMARY KEY, in your first test) becomes bigger than the buffer_pool, the ‘next’ INSERT has a chance of causing a cache miss. Once the index is, say, 5 times as big as the buffer_pool, then 80% of INSERTs will cause cache-misses! This will be dramatic on performance.
If your goal is to rearrange the UUID value so that the “time” is the first part of the string, then INSERT performance will be similar to AUTO_INCREMENT or TIMESTAMP — ‘all’ new rows go into the ‘last’ block of the BTree. The buffer_pool_size no longer matters.
But… Only Type 1 UUIDs have a “time” in them. So only those can be “fixed” that way. Note: MySQL’s UUID is Type 1, but many clients use some other Type.
My blog on such: http://mysql.rjweb.org/doc.php/uuid . Also, MySQL version 8.0 has builtin functions to facilitate rearranging UUIDs and putting them into BINARY(16) to save a significant amount of space (hence speed).
Hi Rick,
You are right that in essence uuid is a ‘random’ string that on a large table the performance will drop. So, the base case is just to show how much my server can insert in the best scenario of the worse case. However, in the second case it will store it in order avoiding this issue.
The second case is where I wanted to compare different approaches. Using another type of UUID version, for sure, is another valid approach that I thought, but I didn’t add it, as at the end, it won’t add any value to the comparison with generated columns.
From my understanding, UUID is packaging data that at the end is unique, but also valuable! What I wanted to show is that decomposing this valuable info, helps us to perform queries over internal fields, and you will still have the UUID as a generated column. Some queries could be:
– Which devices (MAC) sent events at “2017-01-05 09:00:00”?
select mac from uuid_generated where timestamp = “2017-01-05 09:00:00” group by mac;
– When this particular device send the last event?
select max(timestamp) from uuid_generated where mac=conv(“6d5178b4e60c”,16,10);
etc…
MySQL 8.0 will have built-in functions but that will be useful when you don’t care how the UUID is made of.
Now why would you use utf8 to encode what is basically a few hexadecimal numbers and minus signs?
I agree; “CHAR(36) CHARACTER SET utf8” always consumes 108 bytes (in older MySQL versions), so it is really bad to use utf8 instead of ascii (or latin1 or binary).
I wonder if the performance hit for UUID4 would be the same.