
In this blog post, we’ll look at how Prophet can forecast metrics.
Facebook recently released a forecasting tool called Prophet. Prophet can forecast a particular metric in which we have an interest. It works by fitting time-series data to get a prediction of how that metric will look in the future.
For example, it could be used to:
At its core, it uses a Generalized Additive Model. It is basically the merging of two models. First, a generalized linear model that, in the case of Prophet, can be a linear or logistic regression (depending on what we choose). Second, an additive model applied to that regression. The final graph represents the combination of those two. That is, the smoothed regression area of the variable to predict. For more technical details of how it works, check out Prophet’s paper.
Most of the previous points can be summarized in a simple concept, capacity planning. Let’s see how it works.
Prophet provides either a Python or R library. The following example will use the Python one. You can install it using:
|
1 |
pip install prophet |
Prophet expects the metrics with a particular structure: a Pandas DataFrame with two columns, ds and y:
| ds | y | |
|---|---|---|
| 0 | 2013-10-01 | 34 |
| 1 | 2013-10-02 | 43 |
| 2 | 2013-10-03 | 20 |
| 3 | 2013-10-04 | 12 |
| 4 | 2013-10-05 | 46 |
| … | … | … |
The data I am going to use here is from Kaggle Competition Shelter Animal Outcomes. The idea is to find out how Austin Animal Center‘s workload will evolve in the future by trying to predict the number of animal outcomes per day for the next three years. I am using this dataset because it has enough data, shows a very simple trend and it is a non-technical metric (no previous knowledge on the topic is needed). The same method can be applied to most of the services or business metrics you could have.
At this point, we have the metric stored in a local variable, called “series” in this particular example. Now we only need to fit it into our model:
|
1 2 |
m = Prophet() m.fit(series); |
and define how far into the future we want to predict (three years in this case):
|
1 |
future = m.make_future_dataframe(periods=365*3) |
Now, just plot the data:
|
1 2 3 4 5 |
m.plot(forecast) plt.title("Outcomes forecast per Year",fontsize=20) plt.xlabel("Year",fontsize=20) plt.ylabel("Number of outcomes",fontsize=20) plt.show() |
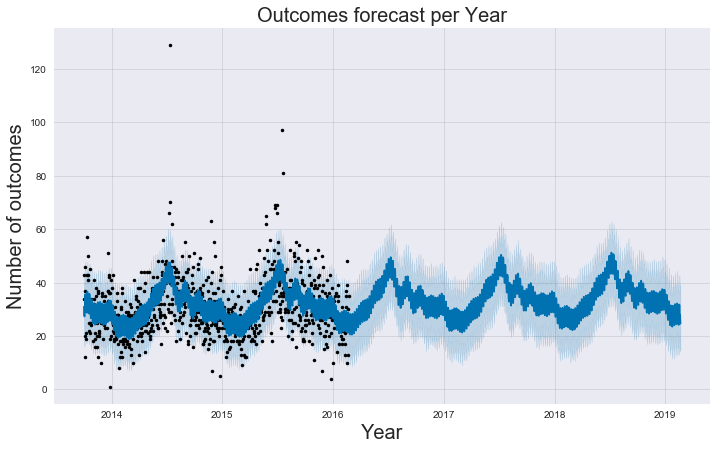
The graph shows a smoothed regression surface. We can see that the data provided covers from the last months 2013 to the first of 2016. From that point, those are the predictions.
We can already find some interesting data. Our data shows a large increase during the summer months and predicts it to continue in the future. But this representation also has some problems. As we can see, there are at least three outliers with values > 65. The fastest way to deal with outliers is to just remove them. 🙂
|
1 |
series[series["y"]>65] |
| ds | y | |
|---|---|---|
| 0 | 2014-07-12 | 129 |
| 1 | 2015-07-18 | 97 |
| 2 | 2015-07-19 | 81 |
| … | … | … |
|
1 |
series.drop(series[series["y"]>60].index,inplace=True) |
Now the graph looks much better. Let’s also add a horizontal line that will help to see the trend:
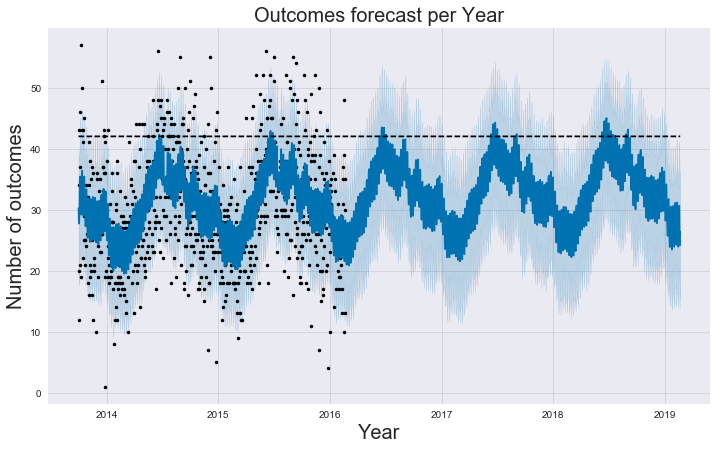
From that forecast, Austin Animal Center should expect an increase in the next few years but not a large one. Therefore, the increase trend year-over-year won’t cause problems in the near future. But there could be a moment when we reach the shelter’s maximum capacity.
|
1 |
m = Prophet(holidays=holidays) |
When we want to predict the future of a particular metric, we can use Prophet to make that forecast, and then plan for it based on the information we get from the model. It can be used on very different types of problems, and it is very easy to use. Do you want to know how loaded your database will be in the future? Ask Prophet!





interesting.
Thanks a lot for the wonderful article. I have two questions. Sometimes Prophet prediction reached below 0 in y axis, even though my past data doesn’t have any negative data set.I tried to plot graph for CPUUtilisation of my database. How that is possible? My data set growth rate is increasing, not decreasing.
Will the prediction work accurately for the equal amount of time that we have data? For example, if I have one month of sample data, will it work properly for future one month alone? Because after one month, I saw the graph increases linearly for different set of data, even though my actual data is non linear.
Hello,
For the first question, I would recommend you to log scale the input data. Works better if there are few points with large peaks of CPU usage when most of the time it is pretty low. If you are using python, just apply np.log to y.
For the second question, the more data you fit in the model the better will be the prediction. If the data you use for training only shows a clear linear increasing shape, it will just predict the same for the next months, because that is what it knows about that metric. Take my blog post as an example. If I only fit “July” data as input, and ask the model to predict the following months, it will fail. Because that large linear increase only happens during summer months. With more data (a year in this case) it is able to see that there are different patterns, with a small increase year over year.
Thanks for the inputs. Really appreciate your efforts!.
Thanks for the article, very quick to get started. FYI, I think there’s a minor but significant bug in your code example. After:
future = …
I think you need to include:
forecast = m.predict(future)