
This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In this blog post, we will cover how to add custom MongoDB graphs to Percona Monitoring and Management (PMM) and (for the daring Golang developers out there) how to add custom metrics to PMM’s percona/mongodb_exporter metric exporter.
To get to adding new graphs and metrics, we first need to go over how PMM gets metrics from your database nodes and how they become graphs.
Percona Monitoring and Management (PMM)
Percona Monitoring and Management (PMM) is an open-source platform for managing and monitoring MySQL and MongoDB. It was developed by Percona on top of open-source technology. Behind the scenes, the graphing features this article covers use Prometheus (a popular time-series data store), Grafana (a popular visualisation tool), mongodb_exporter (our MongoDB database metric exporter) plus other technologies to provide database and operating system metric graphs for your database instances.
Prometheus
As mentioned, Percona Monitoring and Management uses Prometheus to gather and store database and operating system metrics. Prometheus works on an HTTP(s) pull-based architecture, where Prometheus “pulls” metrics from “exporters” on a schedule.
To provide a detailed view of your database hosts, you must enable two PMM monitoring services for MongoDB graphing capabilities:
See this link for more details on adding monitoring services to Percona Monitoring and Management: https://www.percona.com/doc/percona-monitoring-and-management/pmm-admin.html#adding-monitoring-services
It is important to note that not all metrics gathered by Percona Monitoring and Management are graphed. This is by design. Storing more metrics vs. what is graphed is very useful when more advanced insight is necessary. We also aim for PMM to be simple and straightforward to use, explaining why we don’t graph all of the nearly 1,000 metrics we collect per MongoDB node on each polling.
My personal monitoring philosophy is “monitor until it hurts and then take one step back.” In other words, try to get a much data as you can without impacting the database or adding monitoring resources/cost. Also, Prometheus stores large volumes of metrics efficiently due to compression and highly optimized data structures on disk. This offsets a lot of the cost of collecting extra metrics.
Later in this blog, I will show how to add a graph for an example metric that is currently gathered by PMM but is not graphed in PMM as of today. To see what metrics are available on PMM’s Prometheus instance, visit “http://
prometheus/node_exporter (linux:metrics)
PMM’s OS-level metrics are provided to Prometheus via the 3rd-party exporter: prometheus/node_exporter.
This exporter provides 712 metrics per “pull” on my test CentOS 7 host that has:
Note: more physical or virtual devices add to the number of node_exporter metrics.
The inner workings and addition of metrics to this exporter will not be covered in this blog post. Generally, the current metrics offered by node_exporter are more than enough.
Below is a full example of a single “pull” of metrics from node_exporter on my test host:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 1236 1237 1238 1239 1240 1241 1242 1243 1244 1245 1246 1247 1248 1249 1250 1251 1252 1253 1254 1255 1256 1257 1258 1259 1260 1261 1262 1263 1264 1265 1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 1325 1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 1393 1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 1490 1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 1526 1527 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1540 1541 1542 1543 1544 1545 1546 1547 1548 1549 1550 1551 1552 1553 1554 1555 |
$ curl -sk https://192.168.99.10:42000/metrics|grep node # HELP node_boot_time Node boot time, in unixtime. # TYPE node_boot_time gauge node_boot_time 1.488904144e+09 # HELP node_context_switches Total number of context switches. # TYPE node_context_switches counter node_context_switches 1.0407839e+07 # HELP node_cpu Seconds the cpus spent in each mode. # TYPE node_cpu counter node_cpu{cpu="cpu0",mode="guest"} 0 node_cpu{cpu="cpu0",mode="idle"} 6437.71 node_cpu{cpu="cpu0",mode="iowait"} 24 node_cpu{cpu="cpu0",mode="irq"} 0 node_cpu{cpu="cpu0",mode="nice"} 0 node_cpu{cpu="cpu0",mode="softirq"} 1.38 node_cpu{cpu="cpu0",mode="steal"} 0 node_cpu{cpu="cpu0",mode="system"} 117.65 node_cpu{cpu="cpu0",mode="user"} 33.6 node_cpu{cpu="cpu1",mode="guest"} 0 node_cpu{cpu="cpu1",mode="idle"} 6443.68 node_cpu{cpu="cpu1",mode="iowait"} 15.03 node_cpu{cpu="cpu1",mode="irq"} 0 node_cpu{cpu="cpu1",mode="nice"} 0 node_cpu{cpu="cpu1",mode="softirq"} 7.15 node_cpu{cpu="cpu1",mode="steal"} 0 node_cpu{cpu="cpu1",mode="system"} 118.08 node_cpu{cpu="cpu1",mode="user"} 28.84 # HELP node_disk_bytes_read The total number of bytes read successfully. # TYPE node_disk_bytes_read counter node_disk_bytes_read{device="dm-0"} 2.09581056e+08 node_disk_bytes_read{device="dm-1"} 1.114112e+06 node_disk_bytes_read{device="dm-2"} 5.500416e+06 node_disk_bytes_read{device="dm-3"} 2.98752e+06 node_disk_bytes_read{device="dm-4"} 3.480576e+06 node_disk_bytes_read{device="dm-5"} 4.0983552e+07 node_disk_bytes_read{device="dm-6"} 303104 node_disk_bytes_read{device="sda"} 2.40276992e+08 node_disk_bytes_read{device="sdb"} 4.5549568e+07 node_disk_bytes_read{device="sdc"} 8.967168e+06 node_disk_bytes_read{device="sr0"} 49152 # HELP node_disk_bytes_written The total number of bytes written successfully. # TYPE node_disk_bytes_written counter node_disk_bytes_written{device="dm-0"} 4.1160192e+07 node_disk_bytes_written{device="dm-1"} 0 node_disk_bytes_written{device="dm-2"} 2.413568e+06 node_disk_bytes_written{device="dm-3"} 9.0589184e+07 node_disk_bytes_written{device="dm-4"} 4.631552e+06 node_disk_bytes_written{device="dm-5"} 2.140672e+06 node_disk_bytes_written{device="dm-6"} 0 node_disk_bytes_written{device="sda"} 4.3257344e+07 node_disk_bytes_written{device="sdb"} 6.772224e+06 node_disk_bytes_written{device="sdc"} 9.3002752e+07 node_disk_bytes_written{device="sr0"} 0 # HELP node_disk_io_now The number of I/Os currently in progress. # TYPE node_disk_io_now gauge node_disk_io_now{device="dm-0"} 0 node_disk_io_now{device="dm-1"} 0 node_disk_io_now{device="dm-2"} 0 node_disk_io_now{device="dm-3"} 0 node_disk_io_now{device="dm-4"} 0 node_disk_io_now{device="dm-5"} 0 node_disk_io_now{device="dm-6"} 0 node_disk_io_now{device="sda"} 0 node_disk_io_now{device="sdb"} 0 node_disk_io_now{device="sdc"} 0 node_disk_io_now{device="sr0"} 0 # HELP node_disk_io_time_ms Milliseconds spent doing I/Os. # TYPE node_disk_io_time_ms counter node_disk_io_time_ms{device="dm-0"} 6443 node_disk_io_time_ms{device="dm-1"} 41 node_disk_io_time_ms{device="dm-2"} 319 node_disk_io_time_ms{device="dm-3"} 61024 node_disk_io_time_ms{device="dm-4"} 1159 node_disk_io_time_ms{device="dm-5"} 772 node_disk_io_time_ms{device="dm-6"} 1 node_disk_io_time_ms{device="sda"} 6965 node_disk_io_time_ms{device="sdb"} 2004 node_disk_io_time_ms{device="sdc"} 60718 node_disk_io_time_ms{device="sr0"} 5 # HELP node_disk_io_time_weighted The weighted # of milliseconds spent doing I/Os. See https://www.kernel.org/doc/Documentation/iostats.txt. # TYPE node_disk_io_time_weighted counter node_disk_io_time_weighted{device="dm-0"} 9972 node_disk_io_time_weighted{device="dm-1"} 46 node_disk_io_time_weighted{device="dm-2"} 369 node_disk_io_time_weighted{device="dm-3"} 147704 node_disk_io_time_weighted{device="dm-4"} 1618 node_disk_io_time_weighted{device="dm-5"} 968 node_disk_io_time_weighted{device="dm-6"} 1 node_disk_io_time_weighted{device="sda"} 10365 node_disk_io_time_weighted{device="sdb"} 3213 node_disk_io_time_weighted{device="sdc"} 143822 node_disk_io_time_weighted{device="sr0"} 5 # HELP node_disk_read_time_ms The total number of milliseconds spent by all reads. # TYPE node_disk_read_time_ms counter node_disk_read_time_ms{device="dm-0"} 7037 node_disk_read_time_ms{device="dm-1"} 46 node_disk_read_time_ms{device="dm-2"} 312 node_disk_read_time_ms{device="dm-3"} 56 node_disk_read_time_ms{device="dm-4"} 115 node_disk_read_time_ms{device="dm-5"} 906 node_disk_read_time_ms{device="dm-6"} 1 node_disk_read_time_ms{device="sda"} 7646 node_disk_read_time_ms{device="sdb"} 1192 node_disk_read_time_ms{device="sdc"} 412 node_disk_read_time_ms{device="sr0"} 5 # HELP node_disk_reads_completed The total number of reads completed successfully. # TYPE node_disk_reads_completed counter node_disk_reads_completed{device="dm-0"} 11521 node_disk_reads_completed{device="dm-1"} 133 node_disk_reads_completed{device="dm-2"} 1139 node_disk_reads_completed{device="dm-3"} 130 node_disk_reads_completed{device="dm-4"} 199 node_disk_reads_completed{device="dm-5"} 2077 node_disk_reads_completed{device="dm-6"} 42 node_disk_reads_completed{device="sda"} 13429 node_disk_reads_completed{device="sdb"} 2483 node_disk_reads_completed{device="sdc"} 1376 node_disk_reads_completed{device="sr0"} 12 # HELP node_disk_reads_merged The number of reads merged. See https://www.kernel.org/doc/Documentation/iostats.txt. # TYPE node_disk_reads_merged counter node_disk_reads_merged{device="dm-0"} 0 node_disk_reads_merged{device="dm-1"} 0 node_disk_reads_merged{device="dm-2"} 0 node_disk_reads_merged{device="dm-3"} 0 node_disk_reads_merged{device="dm-4"} 0 node_disk_reads_merged{device="dm-5"} 0 node_disk_reads_merged{device="dm-6"} 0 node_disk_reads_merged{device="sda"} 12 node_disk_reads_merged{device="sdb"} 0 node_disk_reads_merged{device="sdc"} 0 node_disk_reads_merged{device="sr0"} 0 # HELP node_disk_sectors_read The total number of sectors read successfully. # TYPE node_disk_sectors_read counter node_disk_sectors_read{device="dm-0"} 409338 node_disk_sectors_read{device="dm-1"} 2176 node_disk_sectors_read{device="dm-2"} 10743 node_disk_sectors_read{device="dm-3"} 5835 node_disk_sectors_read{device="dm-4"} 6798 node_disk_sectors_read{device="dm-5"} 80046 node_disk_sectors_read{device="dm-6"} 592 node_disk_sectors_read{device="sda"} 469291 node_disk_sectors_read{device="sdb"} 88964 node_disk_sectors_read{device="sdc"} 17514 node_disk_sectors_read{device="sr0"} 96 # HELP node_disk_sectors_written The total number of sectors written successfully. # TYPE node_disk_sectors_written counter node_disk_sectors_written{device="dm-0"} 80391 node_disk_sectors_written{device="dm-1"} 0 node_disk_sectors_written{device="dm-2"} 4714 node_disk_sectors_written{device="dm-3"} 176932 node_disk_sectors_written{device="dm-4"} 9046 node_disk_sectors_written{device="dm-5"} 4181 node_disk_sectors_written{device="dm-6"} 0 node_disk_sectors_written{device="sda"} 84487 node_disk_sectors_written{device="sdb"} 13227 node_disk_sectors_written{device="sdc"} 181646 node_disk_sectors_written{device="sr0"} 0 # HELP node_disk_write_time_ms This is the total number of milliseconds spent by all writes. # TYPE node_disk_write_time_ms counter node_disk_write_time_ms{device="dm-0"} 2935 node_disk_write_time_ms{device="dm-1"} 0 node_disk_write_time_ms{device="dm-2"} 57 node_disk_write_time_ms{device="dm-3"} 146868 node_disk_write_time_ms{device="dm-4"} 1503 node_disk_write_time_ms{device="dm-5"} 62 node_disk_write_time_ms{device="dm-6"} 0 node_disk_write_time_ms{device="sda"} 2797 node_disk_write_time_ms{device="sdb"} 2096 node_disk_write_time_ms{device="sdc"} 143569 node_disk_write_time_ms{device="sr0"} 0 # HELP node_disk_writes_completed The total number of writes completed successfully. # TYPE node_disk_writes_completed counter node_disk_writes_completed{device="dm-0"} 2701 node_disk_writes_completed{device="dm-1"} 0 node_disk_writes_completed{device="dm-2"} 70 node_disk_writes_completed{device="dm-3"} 415913 node_disk_writes_completed{device="dm-4"} 2737 node_disk_writes_completed{device="dm-5"} 17 node_disk_writes_completed{device="dm-6"} 0 node_disk_writes_completed{device="sda"} 3733 node_disk_writes_completed{device="sdb"} 3189 node_disk_writes_completed{device="sdc"} 421341 node_disk_writes_completed{device="sr0"} 0 # HELP node_disk_writes_merged The number of writes merged. See https://www.kernel.org/doc/Documentation/iostats.txt. # TYPE node_disk_writes_merged counter node_disk_writes_merged{device="dm-0"} 0 node_disk_writes_merged{device="dm-1"} 0 node_disk_writes_merged{device="dm-2"} 0 node_disk_writes_merged{device="dm-3"} 0 node_disk_writes_merged{device="dm-4"} 0 node_disk_writes_merged{device="dm-5"} 0 node_disk_writes_merged{device="dm-6"} 0 node_disk_writes_merged{device="sda"} 147 node_disk_writes_merged{device="sdb"} 19 node_disk_writes_merged{device="sdc"} 2182 node_disk_writes_merged{device="sr0"} 0 # HELP node_exporter_build_info A metric with a constant '1' value labeled by version, revision, branch, and goversion from which node_exporter was built. # TYPE node_exporter_build_info gauge node_exporter_build_info{branch="master",goversion="go1.7.4",revision="2d78e22000779d63c714011e4fb30c65623b9c77",version="1.1.1"} 1 # HELP node_exporter_scrape_duration_seconds node_exporter: Duration of a scrape job. # TYPE node_exporter_scrape_duration_seconds summary node_exporter_scrape_duration_seconds{collector="diskstats",result="success",quantile="0.5"} 0.00018768700000000002 node_exporter_scrape_duration_seconds{collector="diskstats",result="success",quantile="0.9"} 0.000199063 node_exporter_scrape_duration_seconds{collector="diskstats",result="success",quantile="0.99"} 0.000199063 node_exporter_scrape_duration_seconds_sum{collector="diskstats",result="success"} 0.0008093360000000001 node_exporter_scrape_duration_seconds_count{collector="diskstats",result="success"} 3 node_exporter_scrape_duration_seconds{collector="filefd",result="success",quantile="0.5"} 2.6501000000000003e-05 node_exporter_scrape_duration_seconds{collector="filefd",result="success",quantile="0.9"} 0.000149764 node_exporter_scrape_duration_seconds{collector="filefd",result="success",quantile="0.99"} 0.000149764 node_exporter_scrape_duration_seconds_sum{collector="filefd",result="success"} 0.0004463360000000001 node_exporter_scrape_duration_seconds_count{collector="filefd",result="success"} 3 node_exporter_scrape_duration_seconds{collector="filesystem",result="success",quantile="0.5"} 0.000350556 node_exporter_scrape_duration_seconds{collector="filesystem",result="success",quantile="0.9"} 0.000661542 node_exporter_scrape_duration_seconds{collector="filesystem",result="success",quantile="0.99"} 0.000661542 node_exporter_scrape_duration_seconds_sum{collector="filesystem",result="success"} 0.006669826000000001 node_exporter_scrape_duration_seconds_count{collector="filesystem",result="success"} 3 node_exporter_scrape_duration_seconds{collector="loadavg",result="success",quantile="0.5"} 4.1976e-05 node_exporter_scrape_duration_seconds{collector="loadavg",result="success",quantile="0.9"} 4.2433000000000005e-05 node_exporter_scrape_duration_seconds{collector="loadavg",result="success",quantile="0.99"} 4.2433000000000005e-05 node_exporter_scrape_duration_seconds_sum{collector="loadavg",result="success"} 0.0006603080000000001 node_exporter_scrape_duration_seconds_count{collector="loadavg",result="success"} 3 node_exporter_scrape_duration_seconds{collector="meminfo",result="success",quantile="0.5"} 0.000244919 node_exporter_scrape_duration_seconds{collector="meminfo",result="success",quantile="0.9"} 0.00038740000000000004 node_exporter_scrape_duration_seconds{collector="meminfo",result="success",quantile="0.99"} 0.00038740000000000004 node_exporter_scrape_duration_seconds_sum{collector="meminfo",result="success"} 0.003157154 node_exporter_scrape_duration_seconds_count{collector="meminfo",result="success"} 3 node_exporter_scrape_duration_seconds{collector="netdev",result="success",quantile="0.5"} 0.000152886 node_exporter_scrape_duration_seconds{collector="netdev",result="success",quantile="0.9"} 0.00048569400000000006 node_exporter_scrape_duration_seconds{collector="netdev",result="success",quantile="0.99"} 0.00048569400000000006 node_exporter_scrape_duration_seconds_sum{collector="netdev",result="success"} 0.0033770220000000004 node_exporter_scrape_duration_seconds_count{collector="netdev",result="success"} 3 node_exporter_scrape_duration_seconds{collector="netstat",result="success",quantile="0.5"} 0.0007874710000000001 node_exporter_scrape_duration_seconds{collector="netstat",result="success",quantile="0.9"} 0.001612906 node_exporter_scrape_duration_seconds{collector="netstat",result="success",quantile="0.99"} 0.001612906 node_exporter_scrape_duration_seconds_sum{collector="netstat",result="success"} 0.0055138800000000005 node_exporter_scrape_duration_seconds_count{collector="netstat",result="success"} 3 node_exporter_scrape_duration_seconds{collector="stat",result="success",quantile="0.5"} 9.3368e-05 node_exporter_scrape_duration_seconds{collector="stat",result="success",quantile="0.9"} 0.00014552100000000002 node_exporter_scrape_duration_seconds{collector="stat",result="success",quantile="0.99"} 0.00014552100000000002 node_exporter_scrape_duration_seconds_sum{collector="stat",result="success"} 0.00039008900000000004 node_exporter_scrape_duration_seconds_count{collector="stat",result="success"} 3 node_exporter_scrape_duration_seconds{collector="time",result="success",quantile="0.5"} 1.0485e-05 node_exporter_scrape_duration_seconds{collector="time",result="success",quantile="0.9"} 2.462e-05 node_exporter_scrape_duration_seconds{collector="time",result="success",quantile="0.99"} 2.462e-05 node_exporter_scrape_duration_seconds_sum{collector="time",result="success"} 6.4423e-05 node_exporter_scrape_duration_seconds_count{collector="time",result="success"} 3 node_exporter_scrape_duration_seconds{collector="uname",result="success",quantile="0.5"} 1.811e-05 node_exporter_scrape_duration_seconds{collector="uname",result="success",quantile="0.9"} 6.731300000000001e-05 node_exporter_scrape_duration_seconds{collector="uname",result="success",quantile="0.99"} 6.731300000000001e-05 node_exporter_scrape_duration_seconds_sum{collector="uname",result="success"} 0.00030852200000000004 node_exporter_scrape_duration_seconds_count{collector="uname",result="success"} 3 node_exporter_scrape_duration_seconds{collector="vmstat",result="success",quantile="0.5"} 0.00035561100000000003 node_exporter_scrape_duration_seconds{collector="vmstat",result="success",quantile="0.9"} 0.00046660900000000004 node_exporter_scrape_duration_seconds{collector="vmstat",result="success",quantile="0.99"} 0.00046660900000000004 node_exporter_scrape_duration_seconds_sum{collector="vmstat",result="success"} 0.002186003 node_exporter_scrape_duration_seconds_count{collector="vmstat",result="success"} 3 # HELP node_filefd_allocated File descriptor statistics: allocated. # TYPE node_filefd_allocated gauge node_filefd_allocated 1696 # HELP node_filefd_maximum File descriptor statistics: maximum. # TYPE node_filefd_maximum gauge node_filefd_maximum 382428 # HELP node_filesystem_avail Filesystem space available to non-root users in bytes. # TYPE node_filesystem_avail gauge node_filesystem_avail{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 2.977058816e+09 node_filesystem_avail{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 2.3885000704e+10 node_filesystem_avail{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 6.520070144e+09 node_filesystem_avail{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 8.374427648e+09 node_filesystem_avail{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 6.386853888e+10 node_filesystem_avail{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 1.37248768e+08 node_filesystem_avail{device="rootfs",fstype="rootfs",mountpoint="/"} 2.977058816e+09 node_filesystem_avail{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 1.978773504e+09 node_filesystem_avail{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 3.975168e+08 node_filesystem_avail{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 3.975168e+08 # HELP node_filesystem_files Filesystem total file nodes. # TYPE node_filesystem_files gauge node_filesystem_files{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 6.991872e+06 node_filesystem_files{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 2.9360128e+07 node_filesystem_files{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 8.388608e+06 node_filesystem_files{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 4.194304e+06 node_filesystem_files{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 3.145728e+07 node_filesystem_files{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 512000 node_filesystem_files{device="rootfs",fstype="rootfs",mountpoint="/"} 6.991872e+06 node_filesystem_files{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 485249 node_filesystem_files{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 485249 node_filesystem_files{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 485249 # HELP node_filesystem_files_free Filesystem total free file nodes. # TYPE node_filesystem_files_free gauge node_filesystem_files_free{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 6.839777e+06 node_filesystem_files_free{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 2.9273287e+07 node_filesystem_files_free{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 8.376436e+06 node_filesystem_files_free{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 4.194188e+06 node_filesystem_files_free{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 3.1457181e+07 node_filesystem_files_free{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 511638 node_filesystem_files_free{device="rootfs",fstype="rootfs",mountpoint="/"} 6.839777e+06 node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 484725 node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 485248 node_filesystem_files_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 485248 # HELP node_filesystem_free Filesystem free space in bytes. # TYPE node_filesystem_free gauge node_filesystem_free{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 2.977058816e+09 node_filesystem_free{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 2.3885000704e+10 node_filesystem_free{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 6.520070144e+09 node_filesystem_free{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 8.374427648e+09 node_filesystem_free{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 6.386853888e+10 node_filesystem_free{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 1.37248768e+08 node_filesystem_free{device="rootfs",fstype="rootfs",mountpoint="/"} 2.977058816e+09 node_filesystem_free{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 1.978773504e+09 node_filesystem_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 3.975168e+08 node_filesystem_free{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 3.975168e+08 # HELP node_filesystem_readonly Filesystem read-only status. # TYPE node_filesystem_readonly gauge node_filesystem_readonly{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 0 node_filesystem_readonly{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 0 node_filesystem_readonly{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 0 node_filesystem_readonly{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 0 node_filesystem_readonly{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 0 node_filesystem_readonly{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 0 node_filesystem_readonly{device="rootfs",fstype="rootfs",mountpoint="/"} 0 node_filesystem_readonly{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 0 node_filesystem_readonly{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 0 node_filesystem_readonly{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 0 # HELP node_filesystem_size Filesystem size in bytes. # TYPE node_filesystem_size gauge node_filesystem_size{device="/dev/mapper/centos-root",fstype="xfs",mountpoint="/"} 7.149191168e+09 node_filesystem_size{device="/dev/mapper/data-home",fstype="xfs",mountpoint="/home"} 3.0054285312e+10 node_filesystem_size{device="/dev/mapper/data-opt",fstype="xfs",mountpoint="/opt"} 8.579448832e+09 node_filesystem_size{device="/dev/mapper/tmpdata-docker",fstype="xfs",mountpoint="/var/lib/docker"} 8.579448832e+09 node_filesystem_size{device="/dev/mapper/tmpdata-mongo_data",fstype="xfs",mountpoint="/home/tim/mongo/data"} 6.439305216e+10 node_filesystem_size{device="/dev/sda1",fstype="xfs",mountpoint="/boot"} 5.20794112e+08 node_filesystem_size{device="rootfs",fstype="rootfs",mountpoint="/"} 7.149191168e+09 node_filesystem_size{device="tmpfs",fstype="tmpfs",mountpoint="/run"} 1.987579904e+09 node_filesystem_size{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/0"} 3.975168e+08 node_filesystem_size{device="tmpfs",fstype="tmpfs",mountpoint="/run/user/1000"} 3.975168e+08 # HELP node_forks Total number of forks. # TYPE node_forks counter node_forks 3928 # HELP node_intr Total number of interrupts serviced. # TYPE node_intr counter node_intr 4.629898e+06 # HELP node_load1 1m load average. # TYPE node_load1 gauge node_load1 0.2 # HELP node_load15 15m load average. # TYPE node_load15 gauge node_load15 0.21 # HELP node_load5 5m load average. # TYPE node_load5 gauge node_load5 0.22 # HELP node_memory_Active Memory information field Active. # TYPE node_memory_Active gauge node_memory_Active 4.80772096e+08 # HELP node_memory_Active_anon Memory information field Active_anon. # TYPE node_memory_Active_anon gauge node_memory_Active_anon 3.62610688e+08 # HELP node_memory_Active_file Memory information field Active_file. # TYPE node_memory_Active_file gauge node_memory_Active_file 1.18161408e+08 # HELP node_memory_AnonHugePages Memory information field AnonHugePages. # TYPE node_memory_AnonHugePages gauge node_memory_AnonHugePages 1.2582912e+07 # HELP node_memory_AnonPages Memory information field AnonPages. # TYPE node_memory_AnonPages gauge node_memory_AnonPages 3.62438656e+08 # HELP node_memory_Bounce Memory information field Bounce. # TYPE node_memory_Bounce gauge node_memory_Bounce 0 # HELP node_memory_Buffers Memory information field Buffers. # TYPE node_memory_Buffers gauge node_memory_Buffers 1.90464e+06 # HELP node_memory_Cached Memory information field Cached. # TYPE node_memory_Cached gauge node_memory_Cached 3.12205312e+08 # HELP node_memory_CommitLimit Memory information field CommitLimit. # TYPE node_memory_CommitLimit gauge node_memory_CommitLimit 2.847408128e+09 # HELP node_memory_Committed_AS Memory information field Committed_AS. # TYPE node_memory_Committed_AS gauge node_memory_Committed_AS 5.08229632e+09 # HELP node_memory_DirectMap2M Memory information field DirectMap2M. # TYPE node_memory_DirectMap2M gauge node_memory_DirectMap2M 4.22576128e+09 # HELP node_memory_DirectMap4k Memory information field DirectMap4k. # TYPE node_memory_DirectMap4k gauge node_memory_DirectMap4k 6.914048e+07 # HELP node_memory_Dirty Memory information field Dirty. # TYPE node_memory_Dirty gauge node_memory_Dirty 69632 # HELP node_memory_HardwareCorrupted Memory information field HardwareCorrupted. # TYPE node_memory_HardwareCorrupted gauge node_memory_HardwareCorrupted 0 # HELP node_memory_HugePages_Free Memory information field HugePages_Free. # TYPE node_memory_HugePages_Free gauge node_memory_HugePages_Free 0 # HELP node_memory_HugePages_Rsvd Memory information field HugePages_Rsvd. # TYPE node_memory_HugePages_Rsvd gauge node_memory_HugePages_Rsvd 0 # HELP node_memory_HugePages_Surp Memory information field HugePages_Surp. # TYPE node_memory_HugePages_Surp gauge node_memory_HugePages_Surp 0 # HELP node_memory_HugePages_Total Memory information field HugePages_Total. # TYPE node_memory_HugePages_Total gauge node_memory_HugePages_Total 0 # HELP node_memory_Hugepagesize Memory information field Hugepagesize. # TYPE node_memory_Hugepagesize gauge node_memory_Hugepagesize 2.097152e+06 # HELP node_memory_Inactive Memory information field Inactive. # TYPE node_memory_Inactive gauge node_memory_Inactive 1.95702784e+08 # HELP node_memory_Inactive_anon Memory information field Inactive_anon. # TYPE node_memory_Inactive_anon gauge node_memory_Inactive_anon 8.564736e+06 # HELP node_memory_Inactive_file Memory information field Inactive_file. # TYPE node_memory_Inactive_file gauge node_memory_Inactive_file 1.87138048e+08 # HELP node_memory_KernelStack Memory information field KernelStack. # TYPE node_memory_KernelStack gauge node_memory_KernelStack 1.1583488e+07 # HELP node_memory_Mapped Memory information field Mapped. # TYPE node_memory_Mapped gauge node_memory_Mapped 6.7530752e+07 # HELP node_memory_MemAvailable Memory information field MemAvailable. # TYPE node_memory_MemAvailable gauge node_memory_MemAvailable 3.273515008e+09 # HELP node_memory_MemFree Memory information field MemFree. # TYPE node_memory_MemFree gauge node_memory_MemFree 3.15346944e+09 # HELP node_memory_MemTotal Memory information field MemTotal. # TYPE node_memory_MemTotal gauge node_memory_MemTotal 3.975163904e+09 # HELP node_memory_Mlocked Memory information field Mlocked. # TYPE node_memory_Mlocked gauge node_memory_Mlocked 0 # HELP node_memory_NFS_Unstable Memory information field NFS_Unstable. # TYPE node_memory_NFS_Unstable gauge node_memory_NFS_Unstable 0 # HELP node_memory_PageTables Memory information field PageTables. # TYPE node_memory_PageTables gauge node_memory_PageTables 9.105408e+06 # HELP node_memory_SReclaimable Memory information field SReclaimable. # TYPE node_memory_SReclaimable gauge node_memory_SReclaimable 4.4638208e+07 # HELP node_memory_SUnreclaim Memory information field SUnreclaim. # TYPE node_memory_SUnreclaim gauge node_memory_SUnreclaim 3.2059392e+07 # HELP node_memory_Shmem Memory information field Shmem. # TYPE node_memory_Shmem gauge node_memory_Shmem 8.810496e+06 # HELP node_memory_Slab Memory information field Slab. # TYPE node_memory_Slab gauge node_memory_Slab 7.66976e+07 # HELP node_memory_SwapCached Memory information field SwapCached. # TYPE node_memory_SwapCached gauge node_memory_SwapCached 0 # HELP node_memory_SwapFree Memory information field SwapFree. # TYPE node_memory_SwapFree gauge node_memory_SwapFree 8.59828224e+08 # HELP node_memory_SwapTotal Memory information field SwapTotal. # TYPE node_memory_SwapTotal gauge node_memory_SwapTotal 8.59828224e+08 # HELP node_memory_Unevictable Memory information field Unevictable. # TYPE node_memory_Unevictable gauge node_memory_Unevictable 0 # HELP node_memory_VmallocChunk Memory information field VmallocChunk. # TYPE node_memory_VmallocChunk gauge node_memory_VmallocChunk 3.5184346918912e+13 # HELP node_memory_VmallocTotal Memory information field VmallocTotal. # TYPE node_memory_VmallocTotal gauge node_memory_VmallocTotal 3.5184372087808e+13 # HELP node_memory_VmallocUsed Memory information field VmallocUsed. # TYPE node_memory_VmallocUsed gauge node_memory_VmallocUsed 1.6748544e+07 # HELP node_memory_Writeback Memory information field Writeback. # TYPE node_memory_Writeback gauge node_memory_Writeback 0 # HELP node_memory_WritebackTmp Memory information field WritebackTmp. # TYPE node_memory_WritebackTmp gauge node_memory_WritebackTmp 0 # HELP node_netstat_IcmpMsg_InType3 Protocol IcmpMsg statistic InType3. # TYPE node_netstat_IcmpMsg_InType3 untyped node_netstat_IcmpMsg_InType3 32 # HELP node_netstat_IcmpMsg_OutType3 Protocol IcmpMsg statistic OutType3. # TYPE node_netstat_IcmpMsg_OutType3 untyped node_netstat_IcmpMsg_OutType3 32 # HELP node_netstat_Icmp_InAddrMaskReps Protocol Icmp statistic InAddrMaskReps. # TYPE node_netstat_Icmp_InAddrMaskReps untyped node_netstat_Icmp_InAddrMaskReps 0 # HELP node_netstat_Icmp_InAddrMasks Protocol Icmp statistic InAddrMasks. # TYPE node_netstat_Icmp_InAddrMasks untyped node_netstat_Icmp_InAddrMasks 0 # HELP node_netstat_Icmp_InCsumErrors Protocol Icmp statistic InCsumErrors. # TYPE node_netstat_Icmp_InCsumErrors untyped node_netstat_Icmp_InCsumErrors 0 # HELP node_netstat_Icmp_InDestUnreachs Protocol Icmp statistic InDestUnreachs. # TYPE node_netstat_Icmp_InDestUnreachs untyped node_netstat_Icmp_InDestUnreachs 32 # HELP node_netstat_Icmp_InEchoReps Protocol Icmp statistic InEchoReps. # TYPE node_netstat_Icmp_InEchoReps untyped node_netstat_Icmp_InEchoReps 0 # HELP node_netstat_Icmp_InEchos Protocol Icmp statistic InEchos. # TYPE node_netstat_Icmp_InEchos untyped node_netstat_Icmp_InEchos 0 # HELP node_netstat_Icmp_InErrors Protocol Icmp statistic InErrors. # TYPE node_netstat_Icmp_InErrors untyped node_netstat_Icmp_InErrors 0 # HELP node_netstat_Icmp_InMsgs Protocol Icmp statistic InMsgs. # TYPE node_netstat_Icmp_InMsgs untyped node_netstat_Icmp_InMsgs 32 # HELP node_netstat_Icmp_InParmProbs Protocol Icmp statistic InParmProbs. # TYPE node_netstat_Icmp_InParmProbs untyped node_netstat_Icmp_InParmProbs 0 # HELP node_netstat_Icmp_InRedirects Protocol Icmp statistic InRedirects. # TYPE node_netstat_Icmp_InRedirects untyped node_netstat_Icmp_InRedirects 0 # HELP node_netstat_Icmp_InSrcQuenchs Protocol Icmp statistic InSrcQuenchs. # TYPE node_netstat_Icmp_InSrcQuenchs untyped node_netstat_Icmp_InSrcQuenchs 0 # HELP node_netstat_Icmp_InTimeExcds Protocol Icmp statistic InTimeExcds. # TYPE node_netstat_Icmp_InTimeExcds untyped node_netstat_Icmp_InTimeExcds 0 # HELP node_netstat_Icmp_InTimestampReps Protocol Icmp statistic InTimestampReps. # TYPE node_netstat_Icmp_InTimestampReps untyped node_netstat_Icmp_InTimestampReps 0 # HELP node_netstat_Icmp_InTimestamps Protocol Icmp statistic InTimestamps. # TYPE node_netstat_Icmp_InTimestamps untyped node_netstat_Icmp_InTimestamps 0 # HELP node_netstat_Icmp_OutAddrMaskReps Protocol Icmp statistic OutAddrMaskReps. # TYPE node_netstat_Icmp_OutAddrMaskReps untyped node_netstat_Icmp_OutAddrMaskReps 0 # HELP node_netstat_Icmp_OutAddrMasks Protocol Icmp statistic OutAddrMasks. # TYPE node_netstat_Icmp_OutAddrMasks untyped node_netstat_Icmp_OutAddrMasks 0 # HELP node_netstat_Icmp_OutDestUnreachs Protocol Icmp statistic OutDestUnreachs. # TYPE node_netstat_Icmp_OutDestUnreachs untyped node_netstat_Icmp_OutDestUnreachs 32 # HELP node_netstat_Icmp_OutEchoReps Protocol Icmp statistic OutEchoReps. # TYPE node_netstat_Icmp_OutEchoReps untyped node_netstat_Icmp_OutEchoReps 0 # HELP node_netstat_Icmp_OutEchos Protocol Icmp statistic OutEchos. # TYPE node_netstat_Icmp_OutEchos untyped node_netstat_Icmp_OutEchos 0 # HELP node_netstat_Icmp_OutErrors Protocol Icmp statistic OutErrors. # TYPE node_netstat_Icmp_OutErrors untyped node_netstat_Icmp_OutErrors 0 # HELP node_netstat_Icmp_OutMsgs Protocol Icmp statistic OutMsgs. # TYPE node_netstat_Icmp_OutMsgs untyped node_netstat_Icmp_OutMsgs 32 # HELP node_netstat_Icmp_OutParmProbs Protocol Icmp statistic OutParmProbs. # TYPE node_netstat_Icmp_OutParmProbs untyped node_netstat_Icmp_OutParmProbs 0 # HELP node_netstat_Icmp_OutRedirects Protocol Icmp statistic OutRedirects. # TYPE node_netstat_Icmp_OutRedirects untyped node_netstat_Icmp_OutRedirects 0 # HELP node_netstat_Icmp_OutSrcQuenchs Protocol Icmp statistic OutSrcQuenchs. # TYPE node_netstat_Icmp_OutSrcQuenchs untyped node_netstat_Icmp_OutSrcQuenchs 0 # HELP node_netstat_Icmp_OutTimeExcds Protocol Icmp statistic OutTimeExcds. # TYPE node_netstat_Icmp_OutTimeExcds untyped node_netstat_Icmp_OutTimeExcds 0 # HELP node_netstat_Icmp_OutTimestampReps Protocol Icmp statistic OutTimestampReps. # TYPE node_netstat_Icmp_OutTimestampReps untyped node_netstat_Icmp_OutTimestampReps 0 # HELP node_netstat_Icmp_OutTimestamps Protocol Icmp statistic OutTimestamps. # TYPE node_netstat_Icmp_OutTimestamps untyped node_netstat_Icmp_OutTimestamps 0 # HELP node_netstat_IpExt_InBcastOctets Protocol IpExt statistic InBcastOctets. # TYPE node_netstat_IpExt_InBcastOctets untyped node_netstat_IpExt_InBcastOctets 16200 # HELP node_netstat_IpExt_InBcastPkts Protocol IpExt statistic InBcastPkts. # TYPE node_netstat_IpExt_InBcastPkts untyped node_netstat_IpExt_InBcastPkts 225 # HELP node_netstat_IpExt_InCEPkts Protocol IpExt statistic InCEPkts. # TYPE node_netstat_IpExt_InCEPkts untyped node_netstat_IpExt_InCEPkts 0 # HELP node_netstat_IpExt_InCsumErrors Protocol IpExt statistic InCsumErrors. # TYPE node_netstat_IpExt_InCsumErrors untyped node_netstat_IpExt_InCsumErrors 0 # HELP node_netstat_IpExt_InECT0Pkts Protocol IpExt statistic InECT0Pkts. # TYPE node_netstat_IpExt_InECT0Pkts untyped node_netstat_IpExt_InECT0Pkts 0 # HELP node_netstat_IpExt_InECT1Pkts Protocol IpExt statistic InECT1Pkts. # TYPE node_netstat_IpExt_InECT1Pkts untyped node_netstat_IpExt_InECT1Pkts 0 # HELP node_netstat_IpExt_InMcastOctets Protocol IpExt statistic InMcastOctets. # TYPE node_netstat_IpExt_InMcastOctets untyped node_netstat_IpExt_InMcastOctets 0 # HELP node_netstat_IpExt_InMcastPkts Protocol IpExt statistic InMcastPkts. # TYPE node_netstat_IpExt_InMcastPkts untyped node_netstat_IpExt_InMcastPkts 0 # HELP node_netstat_IpExt_InNoECTPkts Protocol IpExt statistic InNoECTPkts. # TYPE node_netstat_IpExt_InNoECTPkts untyped node_netstat_IpExt_InNoECTPkts 139536 # HELP node_netstat_IpExt_InNoRoutes Protocol IpExt statistic InNoRoutes. # TYPE node_netstat_IpExt_InNoRoutes untyped node_netstat_IpExt_InNoRoutes 1 # HELP node_netstat_IpExt_InOctets Protocol IpExt statistic InOctets. # TYPE node_netstat_IpExt_InOctets untyped node_netstat_IpExt_InOctets 3.4550209e+07 # HELP node_netstat_IpExt_InTruncatedPkts Protocol IpExt statistic InTruncatedPkts. # TYPE node_netstat_IpExt_InTruncatedPkts untyped node_netstat_IpExt_InTruncatedPkts 0 # HELP node_netstat_IpExt_OutBcastOctets Protocol IpExt statistic OutBcastOctets. # TYPE node_netstat_IpExt_OutBcastOctets untyped node_netstat_IpExt_OutBcastOctets 0 # HELP node_netstat_IpExt_OutBcastPkts Protocol IpExt statistic OutBcastPkts. # TYPE node_netstat_IpExt_OutBcastPkts untyped node_netstat_IpExt_OutBcastPkts 0 # HELP node_netstat_IpExt_OutMcastOctets Protocol IpExt statistic OutMcastOctets. # TYPE node_netstat_IpExt_OutMcastOctets untyped node_netstat_IpExt_OutMcastOctets 0 # HELP node_netstat_IpExt_OutMcastPkts Protocol IpExt statistic OutMcastPkts. # TYPE node_netstat_IpExt_OutMcastPkts untyped node_netstat_IpExt_OutMcastPkts 0 # HELP node_netstat_IpExt_OutOctets Protocol IpExt statistic OutOctets. # TYPE node_netstat_IpExt_OutOctets untyped node_netstat_IpExt_OutOctets 3.469735e+07 # HELP node_netstat_Ip_DefaultTTL Protocol Ip statistic DefaultTTL. # TYPE node_netstat_Ip_DefaultTTL untyped node_netstat_Ip_DefaultTTL 64 # HELP node_netstat_Ip_ForwDatagrams Protocol Ip statistic ForwDatagrams. # TYPE node_netstat_Ip_ForwDatagrams untyped node_netstat_Ip_ForwDatagrams 0 # HELP node_netstat_Ip_Forwarding Protocol Ip statistic Forwarding. # TYPE node_netstat_Ip_Forwarding untyped node_netstat_Ip_Forwarding 1 # HELP node_netstat_Ip_FragCreates Protocol Ip statistic FragCreates. # TYPE node_netstat_Ip_FragCreates untyped node_netstat_Ip_FragCreates 0 # HELP node_netstat_Ip_FragFails Protocol Ip statistic FragFails. # TYPE node_netstat_Ip_FragFails untyped node_netstat_Ip_FragFails 0 # HELP node_netstat_Ip_FragOKs Protocol Ip statistic FragOKs. # TYPE node_netstat_Ip_FragOKs untyped node_netstat_Ip_FragOKs 0 # HELP node_netstat_Ip_InAddrErrors Protocol Ip statistic InAddrErrors. # TYPE node_netstat_Ip_InAddrErrors untyped node_netstat_Ip_InAddrErrors 0 # HELP node_netstat_Ip_InDelivers Protocol Ip statistic InDelivers. # TYPE node_netstat_Ip_InDelivers untyped node_netstat_Ip_InDelivers 139535 # HELP node_netstat_Ip_InDiscards Protocol Ip statistic InDiscards. # TYPE node_netstat_Ip_InDiscards untyped node_netstat_Ip_InDiscards 0 # HELP node_netstat_Ip_InHdrErrors Protocol Ip statistic InHdrErrors. # TYPE node_netstat_Ip_InHdrErrors untyped node_netstat_Ip_InHdrErrors 0 # HELP node_netstat_Ip_InReceives Protocol Ip statistic InReceives. # TYPE node_netstat_Ip_InReceives untyped node_netstat_Ip_InReceives 139536 # HELP node_netstat_Ip_InUnknownProtos Protocol Ip statistic InUnknownProtos. # TYPE node_netstat_Ip_InUnknownProtos untyped node_netstat_Ip_InUnknownProtos 0 # HELP node_netstat_Ip_OutDiscards Protocol Ip statistic OutDiscards. # TYPE node_netstat_Ip_OutDiscards untyped node_netstat_Ip_OutDiscards 16 # HELP node_netstat_Ip_OutNoRoutes Protocol Ip statistic OutNoRoutes. # TYPE node_netstat_Ip_OutNoRoutes untyped node_netstat_Ip_OutNoRoutes 0 # HELP node_netstat_Ip_OutRequests Protocol Ip statistic OutRequests. # TYPE node_netstat_Ip_OutRequests untyped node_netstat_Ip_OutRequests 139089 # HELP node_netstat_Ip_ReasmFails Protocol Ip statistic ReasmFails. # TYPE node_netstat_Ip_ReasmFails untyped node_netstat_Ip_ReasmFails 0 # HELP node_netstat_Ip_ReasmOKs Protocol Ip statistic ReasmOKs. # TYPE node_netstat_Ip_ReasmOKs untyped node_netstat_Ip_ReasmOKs 0 # HELP node_netstat_Ip_ReasmReqds Protocol Ip statistic ReasmReqds. # TYPE node_netstat_Ip_ReasmReqds untyped node_netstat_Ip_ReasmReqds 0 # HELP node_netstat_Ip_ReasmTimeout Protocol Ip statistic ReasmTimeout. # TYPE node_netstat_Ip_ReasmTimeout untyped node_netstat_Ip_ReasmTimeout 0 # HELP node_netstat_TcpExt_ArpFilter Protocol TcpExt statistic ArpFilter. # TYPE node_netstat_TcpExt_ArpFilter untyped node_netstat_TcpExt_ArpFilter 0 # HELP node_netstat_TcpExt_BusyPollRxPackets Protocol TcpExt statistic BusyPollRxPackets. # TYPE node_netstat_TcpExt_BusyPollRxPackets untyped node_netstat_TcpExt_BusyPollRxPackets 0 # HELP node_netstat_TcpExt_DelayedACKLocked Protocol TcpExt statistic DelayedACKLocked. # TYPE node_netstat_TcpExt_DelayedACKLocked untyped node_netstat_TcpExt_DelayedACKLocked 0 # HELP node_netstat_TcpExt_DelayedACKLost Protocol TcpExt statistic DelayedACKLost. # TYPE node_netstat_TcpExt_DelayedACKLost untyped node_netstat_TcpExt_DelayedACKLost 0 # HELP node_netstat_TcpExt_DelayedACKs Protocol TcpExt statistic DelayedACKs. # TYPE node_netstat_TcpExt_DelayedACKs untyped node_netstat_TcpExt_DelayedACKs 3374 # HELP node_netstat_TcpExt_EmbryonicRsts Protocol TcpExt statistic EmbryonicRsts. # TYPE node_netstat_TcpExt_EmbryonicRsts untyped node_netstat_TcpExt_EmbryonicRsts 0 # HELP node_netstat_TcpExt_IPReversePathFilter Protocol TcpExt statistic IPReversePathFilter. # TYPE node_netstat_TcpExt_IPReversePathFilter untyped node_netstat_TcpExt_IPReversePathFilter 0 # HELP node_netstat_TcpExt_ListenDrops Protocol TcpExt statistic ListenDrops. # TYPE node_netstat_TcpExt_ListenDrops untyped node_netstat_TcpExt_ListenDrops 0 # HELP node_netstat_TcpExt_ListenOverflows Protocol TcpExt statistic ListenOverflows. # TYPE node_netstat_TcpExt_ListenOverflows untyped node_netstat_TcpExt_ListenOverflows 0 # HELP node_netstat_TcpExt_LockDroppedIcmps Protocol TcpExt statistic LockDroppedIcmps. # TYPE node_netstat_TcpExt_LockDroppedIcmps untyped node_netstat_TcpExt_LockDroppedIcmps 0 # HELP node_netstat_TcpExt_OfoPruned Protocol TcpExt statistic OfoPruned. # TYPE node_netstat_TcpExt_OfoPruned untyped node_netstat_TcpExt_OfoPruned 0 # HELP node_netstat_TcpExt_OutOfWindowIcmps Protocol TcpExt statistic OutOfWindowIcmps. # TYPE node_netstat_TcpExt_OutOfWindowIcmps untyped node_netstat_TcpExt_OutOfWindowIcmps 0 # HELP node_netstat_TcpExt_PAWSActive Protocol TcpExt statistic PAWSActive. # TYPE node_netstat_TcpExt_PAWSActive untyped node_netstat_TcpExt_PAWSActive 0 # HELP node_netstat_TcpExt_PAWSEstab Protocol TcpExt statistic PAWSEstab. # TYPE node_netstat_TcpExt_PAWSEstab untyped node_netstat_TcpExt_PAWSEstab 0 # HELP node_netstat_TcpExt_PAWSPassive Protocol TcpExt statistic PAWSPassive. # TYPE node_netstat_TcpExt_PAWSPassive untyped node_netstat_TcpExt_PAWSPassive 0 # HELP node_netstat_TcpExt_PruneCalled Protocol TcpExt statistic PruneCalled. # TYPE node_netstat_TcpExt_PruneCalled untyped node_netstat_TcpExt_PruneCalled 0 # HELP node_netstat_TcpExt_RcvPruned Protocol TcpExt statistic RcvPruned. # TYPE node_netstat_TcpExt_RcvPruned untyped node_netstat_TcpExt_RcvPruned 0 # HELP node_netstat_TcpExt_SyncookiesFailed Protocol TcpExt statistic SyncookiesFailed. # TYPE node_netstat_TcpExt_SyncookiesFailed untyped node_netstat_TcpExt_SyncookiesFailed 0 # HELP node_netstat_TcpExt_SyncookiesRecv Protocol TcpExt statistic SyncookiesRecv. # TYPE node_netstat_TcpExt_SyncookiesRecv untyped node_netstat_TcpExt_SyncookiesRecv 0 # HELP node_netstat_TcpExt_SyncookiesSent Protocol TcpExt statistic SyncookiesSent. # TYPE node_netstat_TcpExt_SyncookiesSent untyped node_netstat_TcpExt_SyncookiesSent 0 # HELP node_netstat_TcpExt_TCPACKSkippedChallenge Protocol TcpExt statistic TCPACKSkippedChallenge. # TYPE node_netstat_TcpExt_TCPACKSkippedChallenge untyped node_netstat_TcpExt_TCPACKSkippedChallenge 0 # HELP node_netstat_TcpExt_TCPACKSkippedFinWait2 Protocol TcpExt statistic TCPACKSkippedFinWait2. # TYPE node_netstat_TcpExt_TCPACKSkippedFinWait2 untyped node_netstat_TcpExt_TCPACKSkippedFinWait2 0 # HELP node_netstat_TcpExt_TCPACKSkippedPAWS Protocol TcpExt statistic TCPACKSkippedPAWS. # TYPE node_netstat_TcpExt_TCPACKSkippedPAWS untyped node_netstat_TcpExt_TCPACKSkippedPAWS 0 # HELP node_netstat_TcpExt_TCPACKSkippedSeq Protocol TcpExt statistic TCPACKSkippedSeq. # TYPE node_netstat_TcpExt_TCPACKSkippedSeq untyped node_netstat_TcpExt_TCPACKSkippedSeq 0 # HELP node_netstat_TcpExt_TCPACKSkippedSynRecv Protocol TcpExt statistic TCPACKSkippedSynRecv. # TYPE node_netstat_TcpExt_TCPACKSkippedSynRecv untyped node_netstat_TcpExt_TCPACKSkippedSynRecv 0 # HELP node_netstat_TcpExt_TCPACKSkippedTimeWait Protocol TcpExt statistic TCPACKSkippedTimeWait. # TYPE node_netstat_TcpExt_TCPACKSkippedTimeWait untyped node_netstat_TcpExt_TCPACKSkippedTimeWait 0 # HELP node_netstat_TcpExt_TCPAbortFailed Protocol TcpExt statistic TCPAbortFailed. # TYPE node_netstat_TcpExt_TCPAbortFailed untyped node_netstat_TcpExt_TCPAbortFailed 0 # HELP node_netstat_TcpExt_TCPAbortOnClose Protocol TcpExt statistic TCPAbortOnClose. # TYPE node_netstat_TcpExt_TCPAbortOnClose untyped node_netstat_TcpExt_TCPAbortOnClose 1 # HELP node_netstat_TcpExt_TCPAbortOnData Protocol TcpExt statistic TCPAbortOnData. # TYPE node_netstat_TcpExt_TCPAbortOnData untyped node_netstat_TcpExt_TCPAbortOnData 2 # HELP node_netstat_TcpExt_TCPAbortOnLinger Protocol TcpExt statistic TCPAbortOnLinger. # TYPE node_netstat_TcpExt_TCPAbortOnLinger untyped node_netstat_TcpExt_TCPAbortOnLinger 0 # HELP node_netstat_TcpExt_TCPAbortOnMemory Protocol TcpExt statistic TCPAbortOnMemory. # TYPE node_netstat_TcpExt_TCPAbortOnMemory untyped node_netstat_TcpExt_TCPAbortOnMemory 0 # HELP node_netstat_TcpExt_TCPAbortOnTimeout Protocol TcpExt statistic TCPAbortOnTimeout. # TYPE node_netstat_TcpExt_TCPAbortOnTimeout untyped node_netstat_TcpExt_TCPAbortOnTimeout 0 # HELP node_netstat_TcpExt_TCPAutoCorking Protocol TcpExt statistic TCPAutoCorking. # TYPE node_netstat_TcpExt_TCPAutoCorking untyped node_netstat_TcpExt_TCPAutoCorking 4 # HELP node_netstat_TcpExt_TCPBacklogDrop Protocol TcpExt statistic TCPBacklogDrop. # TYPE node_netstat_TcpExt_TCPBacklogDrop untyped node_netstat_TcpExt_TCPBacklogDrop 0 # HELP node_netstat_TcpExt_TCPChallengeACK Protocol TcpExt statistic TCPChallengeACK. # TYPE node_netstat_TcpExt_TCPChallengeACK untyped node_netstat_TcpExt_TCPChallengeACK 0 # HELP node_netstat_TcpExt_TCPDSACKIgnoredNoUndo Protocol TcpExt statistic TCPDSACKIgnoredNoUndo. # TYPE node_netstat_TcpExt_TCPDSACKIgnoredNoUndo untyped node_netstat_TcpExt_TCPDSACKIgnoredNoUndo 0 # HELP node_netstat_TcpExt_TCPDSACKIgnoredOld Protocol TcpExt statistic TCPDSACKIgnoredOld. # TYPE node_netstat_TcpExt_TCPDSACKIgnoredOld untyped node_netstat_TcpExt_TCPDSACKIgnoredOld 0 # HELP node_netstat_TcpExt_TCPDSACKOfoRecv Protocol TcpExt statistic TCPDSACKOfoRecv. # TYPE node_netstat_TcpExt_TCPDSACKOfoRecv untyped node_netstat_TcpExt_TCPDSACKOfoRecv 0 # HELP node_netstat_TcpExt_TCPDSACKOfoSent Protocol TcpExt statistic TCPDSACKOfoSent. # TYPE node_netstat_TcpExt_TCPDSACKOfoSent untyped node_netstat_TcpExt_TCPDSACKOfoSent 0 # HELP node_netstat_TcpExt_TCPDSACKOldSent Protocol TcpExt statistic TCPDSACKOldSent. # TYPE node_netstat_TcpExt_TCPDSACKOldSent untyped node_netstat_TcpExt_TCPDSACKOldSent 0 # HELP node_netstat_TcpExt_TCPDSACKRecv Protocol TcpExt statistic TCPDSACKRecv. # TYPE node_netstat_TcpExt_TCPDSACKRecv untyped node_netstat_TcpExt_TCPDSACKRecv 0 # HELP node_netstat_TcpExt_TCPDSACKUndo Protocol TcpExt statistic TCPDSACKUndo. # TYPE node_netstat_TcpExt_TCPDSACKUndo untyped node_netstat_TcpExt_TCPDSACKUndo 0 # HELP node_netstat_TcpExt_TCPDeferAcceptDrop Protocol TcpExt statistic TCPDeferAcceptDrop. # TYPE node_netstat_TcpExt_TCPDeferAcceptDrop untyped node_netstat_TcpExt_TCPDeferAcceptDrop 0 # HELP node_netstat_TcpExt_TCPDirectCopyFromBacklog Protocol TcpExt statistic TCPDirectCopyFromBacklog. # TYPE node_netstat_TcpExt_TCPDirectCopyFromBacklog untyped node_netstat_TcpExt_TCPDirectCopyFromBacklog 0 # HELP node_netstat_TcpExt_TCPDirectCopyFromPrequeue Protocol TcpExt statistic TCPDirectCopyFromPrequeue. # TYPE node_netstat_TcpExt_TCPDirectCopyFromPrequeue untyped node_netstat_TcpExt_TCPDirectCopyFromPrequeue 1.062e+06 # HELP node_netstat_TcpExt_TCPFACKReorder Protocol TcpExt statistic TCPFACKReorder. # TYPE node_netstat_TcpExt_TCPFACKReorder untyped node_netstat_TcpExt_TCPFACKReorder 0 # HELP node_netstat_TcpExt_TCPFastOpenActive Protocol TcpExt statistic TCPFastOpenActive. # TYPE node_netstat_TcpExt_TCPFastOpenActive untyped node_netstat_TcpExt_TCPFastOpenActive 0 # HELP node_netstat_TcpExt_TCPFastOpenActiveFail Protocol TcpExt statistic TCPFastOpenActiveFail. # TYPE node_netstat_TcpExt_TCPFastOpenActiveFail untyped node_netstat_TcpExt_TCPFastOpenActiveFail 0 # HELP node_netstat_TcpExt_TCPFastOpenCookieReqd Protocol TcpExt statistic TCPFastOpenCookieReqd. # TYPE node_netstat_TcpExt_TCPFastOpenCookieReqd untyped node_netstat_TcpExt_TCPFastOpenCookieReqd 0 # HELP node_netstat_TcpExt_TCPFastOpenListenOverflow Protocol TcpExt statistic TCPFastOpenListenOverflow. # TYPE node_netstat_TcpExt_TCPFastOpenListenOverflow untyped node_netstat_TcpExt_TCPFastOpenListenOverflow 0 # HELP node_netstat_TcpExt_TCPFastOpenPassive Protocol TcpExt statistic TCPFastOpenPassive. # TYPE node_netstat_TcpExt_TCPFastOpenPassive untyped node_netstat_TcpExt_TCPFastOpenPassive 0 # HELP node_netstat_TcpExt_TCPFastOpenPassiveFail Protocol TcpExt statistic TCPFastOpenPassiveFail. # TYPE node_netstat_TcpExt_TCPFastOpenPassiveFail untyped node_netstat_TcpExt_TCPFastOpenPassiveFail 0 # HELP node_netstat_TcpExt_TCPFastRetrans Protocol TcpExt statistic TCPFastRetrans. # TYPE node_netstat_TcpExt_TCPFastRetrans untyped node_netstat_TcpExt_TCPFastRetrans 0 # HELP node_netstat_TcpExt_TCPForwardRetrans Protocol TcpExt statistic TCPForwardRetrans. # TYPE node_netstat_TcpExt_TCPForwardRetrans untyped node_netstat_TcpExt_TCPForwardRetrans 0 # HELP node_netstat_TcpExt_TCPFromZeroWindowAdv Protocol TcpExt statistic TCPFromZeroWindowAdv. # TYPE node_netstat_TcpExt_TCPFromZeroWindowAdv untyped node_netstat_TcpExt_TCPFromZeroWindowAdv 0 # HELP node_netstat_TcpExt_TCPFullUndo Protocol TcpExt statistic TCPFullUndo. # TYPE node_netstat_TcpExt_TCPFullUndo untyped node_netstat_TcpExt_TCPFullUndo 0 # HELP node_netstat_TcpExt_TCPHPAcks Protocol TcpExt statistic TCPHPAcks. # TYPE node_netstat_TcpExt_TCPHPAcks untyped node_netstat_TcpExt_TCPHPAcks 21314 # HELP node_netstat_TcpExt_TCPHPHits Protocol TcpExt statistic TCPHPHits. # TYPE node_netstat_TcpExt_TCPHPHits untyped node_netstat_TcpExt_TCPHPHits 3607 # HELP node_netstat_TcpExt_TCPHPHitsToUser Protocol TcpExt statistic TCPHPHitsToUser. # TYPE node_netstat_TcpExt_TCPHPHitsToUser untyped node_netstat_TcpExt_TCPHPHitsToUser 0 # HELP node_netstat_TcpExt_TCPHystartDelayCwnd Protocol TcpExt statistic TCPHystartDelayCwnd. # TYPE node_netstat_TcpExt_TCPHystartDelayCwnd untyped node_netstat_TcpExt_TCPHystartDelayCwnd 0 # HELP node_netstat_TcpExt_TCPHystartDelayDetect Protocol TcpExt statistic TCPHystartDelayDetect. # TYPE node_netstat_TcpExt_TCPHystartDelayDetect untyped node_netstat_TcpExt_TCPHystartDelayDetect 0 # HELP node_netstat_TcpExt_TCPHystartTrainCwnd Protocol TcpExt statistic TCPHystartTrainCwnd. # TYPE node_netstat_TcpExt_TCPHystartTrainCwnd untyped node_netstat_TcpExt_TCPHystartTrainCwnd 0 # HELP node_netstat_TcpExt_TCPHystartTrainDetect Protocol TcpExt statistic TCPHystartTrainDetect. # TYPE node_netstat_TcpExt_TCPHystartTrainDetect untyped node_netstat_TcpExt_TCPHystartTrainDetect 0 # HELP node_netstat_TcpExt_TCPLossFailures Protocol TcpExt statistic TCPLossFailures. # TYPE node_netstat_TcpExt_TCPLossFailures untyped node_netstat_TcpExt_TCPLossFailures 0 # HELP node_netstat_TcpExt_TCPLossProbeRecovery Protocol TcpExt statistic TCPLossProbeRecovery. # TYPE node_netstat_TcpExt_TCPLossProbeRecovery untyped node_netstat_TcpExt_TCPLossProbeRecovery 0 # HELP node_netstat_TcpExt_TCPLossProbes Protocol TcpExt statistic TCPLossProbes. # TYPE node_netstat_TcpExt_TCPLossProbes untyped node_netstat_TcpExt_TCPLossProbes 0 # HELP node_netstat_TcpExt_TCPLossUndo Protocol TcpExt statistic TCPLossUndo. # TYPE node_netstat_TcpExt_TCPLossUndo untyped node_netstat_TcpExt_TCPLossUndo 0 # HELP node_netstat_TcpExt_TCPLostRetransmit Protocol TcpExt statistic TCPLostRetransmit. # TYPE node_netstat_TcpExt_TCPLostRetransmit untyped node_netstat_TcpExt_TCPLostRetransmit 0 # HELP node_netstat_TcpExt_TCPMD5NotFound Protocol TcpExt statistic TCPMD5NotFound. # TYPE node_netstat_TcpExt_TCPMD5NotFound untyped node_netstat_TcpExt_TCPMD5NotFound 0 # HELP node_netstat_TcpExt_TCPMD5Unexpected Protocol TcpExt statistic TCPMD5Unexpected. # TYPE node_netstat_TcpExt_TCPMD5Unexpected untyped node_netstat_TcpExt_TCPMD5Unexpected 0 # HELP node_netstat_TcpExt_TCPMemoryPressures Protocol TcpExt statistic TCPMemoryPressures. # TYPE node_netstat_TcpExt_TCPMemoryPressures untyped node_netstat_TcpExt_TCPMemoryPressures 0 # HELP node_netstat_TcpExt_TCPMinTTLDrop Protocol TcpExt statistic TCPMinTTLDrop. # TYPE node_netstat_TcpExt_TCPMinTTLDrop untyped node_netstat_TcpExt_TCPMinTTLDrop 0 # HELP node_netstat_TcpExt_TCPOFODrop Protocol TcpExt statistic TCPOFODrop. # TYPE node_netstat_TcpExt_TCPOFODrop untyped node_netstat_TcpExt_TCPOFODrop 0 # HELP node_netstat_TcpExt_TCPOFOMerge Protocol TcpExt statistic TCPOFOMerge. # TYPE node_netstat_TcpExt_TCPOFOMerge untyped node_netstat_TcpExt_TCPOFOMerge 0 # HELP node_netstat_TcpExt_TCPOFOQueue Protocol TcpExt statistic TCPOFOQueue. # TYPE node_netstat_TcpExt_TCPOFOQueue untyped node_netstat_TcpExt_TCPOFOQueue 0 # HELP node_netstat_TcpExt_TCPOrigDataSent Protocol TcpExt statistic TCPOrigDataSent. # TYPE node_netstat_TcpExt_TCPOrigDataSent untyped node_netstat_TcpExt_TCPOrigDataSent 99807 # HELP node_netstat_TcpExt_TCPPartialUndo Protocol TcpExt statistic TCPPartialUndo. # TYPE node_netstat_TcpExt_TCPPartialUndo untyped node_netstat_TcpExt_TCPPartialUndo 0 # HELP node_netstat_TcpExt_TCPPrequeueDropped Protocol TcpExt statistic TCPPrequeueDropped. # TYPE node_netstat_TcpExt_TCPPrequeueDropped untyped node_netstat_TcpExt_TCPPrequeueDropped 0 # HELP node_netstat_TcpExt_TCPPrequeued Protocol TcpExt statistic TCPPrequeued. # TYPE node_netstat_TcpExt_TCPPrequeued untyped node_netstat_TcpExt_TCPPrequeued 68753 # HELP node_netstat_TcpExt_TCPPureAcks Protocol TcpExt statistic TCPPureAcks. # TYPE node_netstat_TcpExt_TCPPureAcks untyped node_netstat_TcpExt_TCPPureAcks 17834 # HELP node_netstat_TcpExt_TCPRcvCoalesce Protocol TcpExt statistic TCPRcvCoalesce. # TYPE node_netstat_TcpExt_TCPRcvCoalesce untyped node_netstat_TcpExt_TCPRcvCoalesce 2 # HELP node_netstat_TcpExt_TCPRcvCollapsed Protocol TcpExt statistic TCPRcvCollapsed. # TYPE node_netstat_TcpExt_TCPRcvCollapsed untyped node_netstat_TcpExt_TCPRcvCollapsed 0 # HELP node_netstat_TcpExt_TCPRenoFailures Protocol TcpExt statistic TCPRenoFailures. # TYPE node_netstat_TcpExt_TCPRenoFailures untyped node_netstat_TcpExt_TCPRenoFailures 0 # HELP node_netstat_TcpExt_TCPRenoRecovery Protocol TcpExt statistic TCPRenoRecovery. # TYPE node_netstat_TcpExt_TCPRenoRecovery untyped node_netstat_TcpExt_TCPRenoRecovery 0 # HELP node_netstat_TcpExt_TCPRenoRecoveryFail Protocol TcpExt statistic TCPRenoRecoveryFail. # TYPE node_netstat_TcpExt_TCPRenoRecoveryFail untyped node_netstat_TcpExt_TCPRenoRecoveryFail 0 # HELP node_netstat_TcpExt_TCPRenoReorder Protocol TcpExt statistic TCPRenoReorder. # TYPE node_netstat_TcpExt_TCPRenoReorder untyped node_netstat_TcpExt_TCPRenoReorder 0 # HELP node_netstat_TcpExt_TCPReqQFullDoCookies Protocol TcpExt statistic TCPReqQFullDoCookies. # TYPE node_netstat_TcpExt_TCPReqQFullDoCookies untyped node_netstat_TcpExt_TCPReqQFullDoCookies 0 # HELP node_netstat_TcpExt_TCPReqQFullDrop Protocol TcpExt statistic TCPReqQFullDrop. # TYPE node_netstat_TcpExt_TCPReqQFullDrop untyped node_netstat_TcpExt_TCPReqQFullDrop 0 # HELP node_netstat_TcpExt_TCPRetransFail Protocol TcpExt statistic TCPRetransFail. # TYPE node_netstat_TcpExt_TCPRetransFail untyped node_netstat_TcpExt_TCPRetransFail 0 # HELP node_netstat_TcpExt_TCPSACKDiscard Protocol TcpExt statistic TCPSACKDiscard. # TYPE node_netstat_TcpExt_TCPSACKDiscard untyped node_netstat_TcpExt_TCPSACKDiscard 0 # HELP node_netstat_TcpExt_TCPSACKReneging Protocol TcpExt statistic TCPSACKReneging. # TYPE node_netstat_TcpExt_TCPSACKReneging untyped node_netstat_TcpExt_TCPSACKReneging 0 # HELP node_netstat_TcpExt_TCPSACKReorder Protocol TcpExt statistic TCPSACKReorder. # TYPE node_netstat_TcpExt_TCPSACKReorder untyped node_netstat_TcpExt_TCPSACKReorder 0 # HELP node_netstat_TcpExt_TCPSYNChallenge Protocol TcpExt statistic TCPSYNChallenge. # TYPE node_netstat_TcpExt_TCPSYNChallenge untyped node_netstat_TcpExt_TCPSYNChallenge 0 # HELP node_netstat_TcpExt_TCPSackFailures Protocol TcpExt statistic TCPSackFailures. # TYPE node_netstat_TcpExt_TCPSackFailures untyped node_netstat_TcpExt_TCPSackFailures 0 # HELP node_netstat_TcpExt_TCPSackMerged Protocol TcpExt statistic TCPSackMerged. # TYPE node_netstat_TcpExt_TCPSackMerged untyped node_netstat_TcpExt_TCPSackMerged 0 # HELP node_netstat_TcpExt_TCPSackRecovery Protocol TcpExt statistic TCPSackRecovery. # TYPE node_netstat_TcpExt_TCPSackRecovery untyped node_netstat_TcpExt_TCPSackRecovery 0 # HELP node_netstat_TcpExt_TCPSackRecoveryFail Protocol TcpExt statistic TCPSackRecoveryFail. # TYPE node_netstat_TcpExt_TCPSackRecoveryFail untyped node_netstat_TcpExt_TCPSackRecoveryFail 0 # HELP node_netstat_TcpExt_TCPSackShiftFallback Protocol TcpExt statistic TCPSackShiftFallback. # TYPE node_netstat_TcpExt_TCPSackShiftFallback untyped node_netstat_TcpExt_TCPSackShiftFallback 0 # HELP node_netstat_TcpExt_TCPSackShifted Protocol TcpExt statistic TCPSackShifted. # TYPE node_netstat_TcpExt_TCPSackShifted untyped node_netstat_TcpExt_TCPSackShifted 0 # HELP node_netstat_TcpExt_TCPSchedulerFailed Protocol TcpExt statistic TCPSchedulerFailed. # TYPE node_netstat_TcpExt_TCPSchedulerFailed untyped node_netstat_TcpExt_TCPSchedulerFailed 0 # HELP node_netstat_TcpExt_TCPSlowStartRetrans Protocol TcpExt statistic TCPSlowStartRetrans. # TYPE node_netstat_TcpExt_TCPSlowStartRetrans untyped node_netstat_TcpExt_TCPSlowStartRetrans 0 # HELP node_netstat_TcpExt_TCPSpuriousRTOs Protocol TcpExt statistic TCPSpuriousRTOs. # TYPE node_netstat_TcpExt_TCPSpuriousRTOs untyped node_netstat_TcpExt_TCPSpuriousRTOs 0 # HELP node_netstat_TcpExt_TCPSpuriousRtxHostQueues Protocol TcpExt statistic TCPSpuriousRtxHostQueues. # TYPE node_netstat_TcpExt_TCPSpuriousRtxHostQueues untyped node_netstat_TcpExt_TCPSpuriousRtxHostQueues 0 # HELP node_netstat_TcpExt_TCPSynRetrans Protocol TcpExt statistic TCPSynRetrans. # TYPE node_netstat_TcpExt_TCPSynRetrans untyped node_netstat_TcpExt_TCPSynRetrans 0 # HELP node_netstat_TcpExt_TCPTSReorder Protocol TcpExt statistic TCPTSReorder. # TYPE node_netstat_TcpExt_TCPTSReorder untyped node_netstat_TcpExt_TCPTSReorder 0 # HELP node_netstat_TcpExt_TCPTimeWaitOverflow Protocol TcpExt statistic TCPTimeWaitOverflow. # TYPE node_netstat_TcpExt_TCPTimeWaitOverflow untyped node_netstat_TcpExt_TCPTimeWaitOverflow 0 # HELP node_netstat_TcpExt_TCPTimeouts Protocol TcpExt statistic TCPTimeouts. # TYPE node_netstat_TcpExt_TCPTimeouts untyped node_netstat_TcpExt_TCPTimeouts 0 # HELP node_netstat_TcpExt_TCPToZeroWindowAdv Protocol TcpExt statistic TCPToZeroWindowAdv. # TYPE node_netstat_TcpExt_TCPToZeroWindowAdv untyped node_netstat_TcpExt_TCPToZeroWindowAdv 0 # HELP node_netstat_TcpExt_TCPWantZeroWindowAdv Protocol TcpExt statistic TCPWantZeroWindowAdv. # TYPE node_netstat_TcpExt_TCPWantZeroWindowAdv untyped node_netstat_TcpExt_TCPWantZeroWindowAdv 0 # HELP node_netstat_TcpExt_TW Protocol TcpExt statistic TW. # TYPE node_netstat_TcpExt_TW untyped node_netstat_TcpExt_TW 35 # HELP node_netstat_TcpExt_TWKilled Protocol TcpExt statistic TWKilled. # TYPE node_netstat_TcpExt_TWKilled untyped node_netstat_TcpExt_TWKilled 0 # HELP node_netstat_TcpExt_TWRecycled Protocol TcpExt statistic TWRecycled. # TYPE node_netstat_TcpExt_TWRecycled untyped node_netstat_TcpExt_TWRecycled 0 # HELP node_netstat_Tcp_ActiveOpens Protocol Tcp statistic ActiveOpens. # TYPE node_netstat_Tcp_ActiveOpens untyped node_netstat_Tcp_ActiveOpens 122 # HELP node_netstat_Tcp_AttemptFails Protocol Tcp statistic AttemptFails. # TYPE node_netstat_Tcp_AttemptFails untyped node_netstat_Tcp_AttemptFails 48 # HELP node_netstat_Tcp_CurrEstab Protocol Tcp statistic CurrEstab. # TYPE node_netstat_Tcp_CurrEstab untyped node_netstat_Tcp_CurrEstab 67 # HELP node_netstat_Tcp_EstabResets Protocol Tcp statistic EstabResets. # TYPE node_netstat_Tcp_EstabResets untyped node_netstat_Tcp_EstabResets 3 # HELP node_netstat_Tcp_InCsumErrors Protocol Tcp statistic InCsumErrors. # TYPE node_netstat_Tcp_InCsumErrors untyped node_netstat_Tcp_InCsumErrors 0 # HELP node_netstat_Tcp_InErrs Protocol Tcp statistic InErrs. # TYPE node_netstat_Tcp_InErrs untyped node_netstat_Tcp_InErrs 0 # HELP node_netstat_Tcp_InSegs Protocol Tcp statistic InSegs. # TYPE node_netstat_Tcp_InSegs untyped node_netstat_Tcp_InSegs 138959 # HELP node_netstat_Tcp_MaxConn Protocol Tcp statistic MaxConn. # TYPE node_netstat_Tcp_MaxConn untyped node_netstat_Tcp_MaxConn -1 # HELP node_netstat_Tcp_OutRsts Protocol Tcp statistic OutRsts. # TYPE node_netstat_Tcp_OutRsts untyped node_netstat_Tcp_OutRsts 51 # HELP node_netstat_Tcp_OutSegs Protocol Tcp statistic OutSegs. # TYPE node_netstat_Tcp_OutSegs untyped node_netstat_Tcp_OutSegs 138800 # HELP node_netstat_Tcp_PassiveOpens Protocol Tcp statistic PassiveOpens. # TYPE node_netstat_Tcp_PassiveOpens untyped node_netstat_Tcp_PassiveOpens 75 # HELP node_netstat_Tcp_RetransSegs Protocol Tcp statistic RetransSegs. # TYPE node_netstat_Tcp_RetransSegs untyped node_netstat_Tcp_RetransSegs 0 # HELP node_netstat_Tcp_RtoAlgorithm Protocol Tcp statistic RtoAlgorithm. # TYPE node_netstat_Tcp_RtoAlgorithm untyped node_netstat_Tcp_RtoAlgorithm 1 # HELP node_netstat_Tcp_RtoMax Protocol Tcp statistic RtoMax. # TYPE node_netstat_Tcp_RtoMax untyped node_netstat_Tcp_RtoMax 120000 # HELP node_netstat_Tcp_RtoMin Protocol Tcp statistic RtoMin. # TYPE node_netstat_Tcp_RtoMin untyped node_netstat_Tcp_RtoMin 200 # HELP node_netstat_UdpLite_InCsumErrors Protocol UdpLite statistic InCsumErrors. # TYPE node_netstat_UdpLite_InCsumErrors untyped node_netstat_UdpLite_InCsumErrors 0 # HELP node_netstat_UdpLite_InDatagrams Protocol UdpLite statistic InDatagrams. # TYPE node_netstat_UdpLite_InDatagrams untyped node_netstat_UdpLite_InDatagrams 0 # HELP node_netstat_UdpLite_InErrors Protocol UdpLite statistic InErrors. # TYPE node_netstat_UdpLite_InErrors untyped node_netstat_UdpLite_InErrors 0 # HELP node_netstat_UdpLite_NoPorts Protocol UdpLite statistic NoPorts. # TYPE node_netstat_UdpLite_NoPorts untyped node_netstat_UdpLite_NoPorts 0 # HELP node_netstat_UdpLite_OutDatagrams Protocol UdpLite statistic OutDatagrams. # TYPE node_netstat_UdpLite_OutDatagrams untyped node_netstat_UdpLite_OutDatagrams 0 # HELP node_netstat_UdpLite_RcvbufErrors Protocol UdpLite statistic RcvbufErrors. # TYPE node_netstat_UdpLite_RcvbufErrors untyped node_netstat_UdpLite_RcvbufErrors 0 # HELP node_netstat_UdpLite_SndbufErrors Protocol UdpLite statistic SndbufErrors. # TYPE node_netstat_UdpLite_SndbufErrors untyped node_netstat_UdpLite_SndbufErrors 0 # HELP node_netstat_Udp_InCsumErrors Protocol Udp statistic InCsumErrors. # TYPE node_netstat_Udp_InCsumErrors untyped node_netstat_Udp_InCsumErrors 0 # HELP node_netstat_Udp_InDatagrams Protocol Udp statistic InDatagrams. # TYPE node_netstat_Udp_InDatagrams untyped node_netstat_Udp_InDatagrams 347 # HELP node_netstat_Udp_InErrors Protocol Udp statistic InErrors. # TYPE node_netstat_Udp_InErrors untyped node_netstat_Udp_InErrors 0 # HELP node_netstat_Udp_NoPorts Protocol Udp statistic NoPorts. # TYPE node_netstat_Udp_NoPorts untyped node_netstat_Udp_NoPorts 32 # HELP node_netstat_Udp_OutDatagrams Protocol Udp statistic OutDatagrams. # TYPE node_netstat_Udp_OutDatagrams untyped node_netstat_Udp_OutDatagrams 388 # HELP node_netstat_Udp_RcvbufErrors Protocol Udp statistic RcvbufErrors. # TYPE node_netstat_Udp_RcvbufErrors untyped node_netstat_Udp_RcvbufErrors 0 # HELP node_netstat_Udp_SndbufErrors Protocol Udp statistic SndbufErrors. # TYPE node_netstat_Udp_SndbufErrors untyped node_netstat_Udp_SndbufErrors 0 # HELP node_network_receive_bytes Network device statistic receive_bytes. # TYPE node_network_receive_bytes gauge node_network_receive_bytes{device="docker0"} 0 node_network_receive_bytes{device="enp0s3"} 36421 node_network_receive_bytes{device="enp0s8"} 80451 node_network_receive_bytes{device="lo"} 3.4463599e+07 # HELP node_network_receive_compressed Network device statistic receive_compressed. # TYPE node_network_receive_compressed gauge node_network_receive_compressed{device="docker0"} 0 node_network_receive_compressed{device="enp0s3"} 0 node_network_receive_compressed{device="enp0s8"} 0 node_network_receive_compressed{device="lo"} 0 # HELP node_network_receive_drop Network device statistic receive_drop. # TYPE node_network_receive_drop gauge node_network_receive_drop{device="docker0"} 0 node_network_receive_drop{device="enp0s3"} 0 node_network_receive_drop{device="enp0s8"} 0 node_network_receive_drop{device="lo"} 0 # HELP node_network_receive_errs Network device statistic receive_errs. # TYPE node_network_receive_errs gauge node_network_receive_errs{device="docker0"} 0 node_network_receive_errs{device="enp0s3"} 0 node_network_receive_errs{device="enp0s8"} 0 node_network_receive_errs{device="lo"} 0 # HELP node_network_receive_fifo Network device statistic receive_fifo. # TYPE node_network_receive_fifo gauge node_network_receive_fifo{device="docker0"} 0 node_network_receive_fifo{device="enp0s3"} 0 node_network_receive_fifo{device="enp0s8"} 0 node_network_receive_fifo{device="lo"} 0 # HELP node_network_receive_frame Network device statistic receive_frame. # TYPE node_network_receive_frame gauge node_network_receive_frame{device="docker0"} 0 node_network_receive_frame{device="enp0s3"} 0 node_network_receive_frame{device="enp0s8"} 0 node_network_receive_frame{device="lo"} 0 # HELP node_network_receive_multicast Network device statistic receive_multicast. # TYPE node_network_receive_multicast gauge node_network_receive_multicast{device="docker0"} 0 node_network_receive_multicast{device="enp0s3"} 0 node_network_receive_multicast{device="enp0s8"} 0 node_network_receive_multicast{device="lo"} 0 # HELP node_network_receive_packets Network device statistic receive_packets. # TYPE node_network_receive_packets gauge node_network_receive_packets{device="docker0"} 0 node_network_receive_packets{device="enp0s3"} 421 node_network_receive_packets{device="enp0s8"} 997 node_network_receive_packets{device="lo"} 138313 # HELP node_network_transmit_bytes Network device statistic transmit_bytes. # TYPE node_network_transmit_bytes gauge node_network_transmit_bytes{device="docker0"} 0 node_network_transmit_bytes{device="enp0s3"} 37074 node_network_transmit_bytes{device="enp0s8"} 330717 node_network_transmit_bytes{device="lo"} 3.4463599e+07 # HELP node_network_transmit_compressed Network device statistic transmit_compressed. # TYPE node_network_transmit_compressed gauge node_network_transmit_compressed{device="docker0"} 0 node_network_transmit_compressed{device="enp0s3"} 0 node_network_transmit_compressed{device="enp0s8"} 0 node_network_transmit_compressed{device="lo"} 0 # HELP node_network_transmit_drop Network device statistic transmit_drop. # TYPE node_network_transmit_drop gauge node_network_transmit_drop{device="docker0"} 0 node_network_transmit_drop{device="enp0s3"} 0 node_network_transmit_drop{device="enp0s8"} 0 node_network_transmit_drop{device="lo"} 0 # HELP node_network_transmit_errs Network device statistic transmit_errs. # TYPE node_network_transmit_errs gauge node_network_transmit_errs{device="docker0"} 0 node_network_transmit_errs{device="enp0s3"} 0 node_network_transmit_errs{device="enp0s8"} 0 node_network_transmit_errs{device="lo"} 0 # HELP node_network_transmit_fifo Network device statistic transmit_fifo. # TYPE node_network_transmit_fifo gauge node_network_transmit_fifo{device="docker0"} 0 node_network_transmit_fifo{device="enp0s3"} 0 node_network_transmit_fifo{device="enp0s8"} 0 node_network_transmit_fifo{device="lo"} 0 # HELP node_network_transmit_frame Network device statistic transmit_frame. # TYPE node_network_transmit_frame gauge node_network_transmit_frame{device="docker0"} 0 node_network_transmit_frame{device="enp0s3"} 0 node_network_transmit_frame{device="enp0s8"} 0 node_network_transmit_frame{device="lo"} 0 # HELP node_network_transmit_multicast Network device statistic transmit_multicast. # TYPE node_network_transmit_multicast gauge node_network_transmit_multicast{device="docker0"} 0 node_network_transmit_multicast{device="enp0s3"} 0 node_network_transmit_multicast{device="enp0s8"} 0 node_network_transmit_multicast{device="lo"} 0 # HELP node_network_transmit_packets Network device statistic transmit_packets. # TYPE node_network_transmit_packets gauge node_network_transmit_packets{device="docker0"} 0 node_network_transmit_packets{device="enp0s3"} 438 node_network_transmit_packets{device="enp0s8"} 627 node_network_transmit_packets{device="lo"} 138313 # HELP node_procs_blocked Number of processes blocked waiting for I/O to complete. # TYPE node_procs_blocked gauge node_procs_blocked 0 # HELP node_procs_running Number of processes in runnable state. # TYPE node_procs_running gauge node_procs_running 2 # HELP node_time System time in seconds since epoch (1970). # TYPE node_time counter node_time 1.48891092e+09 # HELP node_uname_info Labeled system information as provided by the uname system call. # TYPE node_uname_info gauge node_uname_info{domainname="(none)",machine="x86_64",nodename="centos7",release="3.10.0-514.10.2.el7.x86_64",sysname="Linux",version="#1 SMP Fri Mar 3 00:04:05 UTC 2017"} 1 # HELP node_vmstat_allocstall /proc/vmstat information field allocstall. # TYPE node_vmstat_allocstall untyped node_vmstat_allocstall 0 # HELP node_vmstat_balloon_deflate /proc/vmstat information field balloon_deflate. # TYPE node_vmstat_balloon_deflate untyped node_vmstat_balloon_deflate 0 # HELP node_vmstat_balloon_inflate /proc/vmstat information field balloon_inflate. # TYPE node_vmstat_balloon_inflate untyped node_vmstat_balloon_inflate 0 # HELP node_vmstat_balloon_migrate /proc/vmstat information field balloon_migrate. # TYPE node_vmstat_balloon_migrate untyped node_vmstat_balloon_migrate 0 # HELP node_vmstat_compact_fail /proc/vmstat information field compact_fail. # TYPE node_vmstat_compact_fail untyped node_vmstat_compact_fail 0 # HELP node_vmstat_compact_free_scanned /proc/vmstat information field compact_free_scanned. # TYPE node_vmstat_compact_free_scanned untyped node_vmstat_compact_free_scanned 0 # HELP node_vmstat_compact_isolated /proc/vmstat information field compact_isolated. # TYPE node_vmstat_compact_isolated untyped node_vmstat_compact_isolated 0 # HELP node_vmstat_compact_migrate_scanned /proc/vmstat information field compact_migrate_scanned. # TYPE node_vmstat_compact_migrate_scanned untyped node_vmstat_compact_migrate_scanned 0 # HELP node_vmstat_compact_stall /proc/vmstat information field compact_stall. # TYPE node_vmstat_compact_stall untyped node_vmstat_compact_stall 0 # HELP node_vmstat_compact_success /proc/vmstat information field compact_success. # TYPE node_vmstat_compact_success untyped node_vmstat_compact_success 0 # HELP node_vmstat_drop_pagecache /proc/vmstat information field drop_pagecache. # TYPE node_vmstat_drop_pagecache untyped node_vmstat_drop_pagecache 0 # HELP node_vmstat_drop_slab /proc/vmstat information field drop_slab. # TYPE node_vmstat_drop_slab untyped node_vmstat_drop_slab 0 # HELP node_vmstat_htlb_buddy_alloc_fail /proc/vmstat information field htlb_buddy_alloc_fail. # TYPE node_vmstat_htlb_buddy_alloc_fail untyped node_vmstat_htlb_buddy_alloc_fail 0 # HELP node_vmstat_htlb_buddy_alloc_success /proc/vmstat information field htlb_buddy_alloc_success. # TYPE node_vmstat_htlb_buddy_alloc_success untyped node_vmstat_htlb_buddy_alloc_success 0 # HELP node_vmstat_kswapd_high_wmark_hit_quickly /proc/vmstat information field kswapd_high_wmark_hit_quickly. # TYPE node_vmstat_kswapd_high_wmark_hit_quickly untyped node_vmstat_kswapd_high_wmark_hit_quickly 0 # HELP node_vmstat_kswapd_inodesteal /proc/vmstat information field kswapd_inodesteal. # TYPE node_vmstat_kswapd_inodesteal untyped node_vmstat_kswapd_inodesteal 0 # HELP node_vmstat_kswapd_low_wmark_hit_quickly /proc/vmstat information field kswapd_low_wmark_hit_quickly. # TYPE node_vmstat_kswapd_low_wmark_hit_quickly untyped node_vmstat_kswapd_low_wmark_hit_quickly 0 # HELP node_vmstat_nr_active_anon /proc/vmstat information field nr_active_anon. # TYPE node_vmstat_nr_active_anon untyped node_vmstat_nr_active_anon 88528 # HELP node_vmstat_nr_active_file /proc/vmstat information field nr_active_file. # TYPE node_vmstat_nr_active_file untyped node_vmstat_nr_active_file 28848 # HELP node_vmstat_nr_alloc_batch /proc/vmstat information field nr_alloc_batch. # TYPE node_vmstat_nr_alloc_batch untyped node_vmstat_nr_alloc_batch 2642 # HELP node_vmstat_nr_anon_pages /proc/vmstat information field nr_anon_pages. # TYPE node_vmstat_nr_anon_pages untyped node_vmstat_nr_anon_pages 85414 # HELP node_vmstat_nr_anon_transparent_hugepages /proc/vmstat information field nr_anon_transparent_hugepages. # TYPE node_vmstat_nr_anon_transparent_hugepages untyped node_vmstat_nr_anon_transparent_hugepages 6 # HELP node_vmstat_nr_bounce /proc/vmstat information field nr_bounce. # TYPE node_vmstat_nr_bounce untyped node_vmstat_nr_bounce 0 # HELP node_vmstat_nr_dirtied /proc/vmstat information field nr_dirtied. # TYPE node_vmstat_nr_dirtied untyped node_vmstat_nr_dirtied 29852 # HELP node_vmstat_nr_dirty /proc/vmstat information field nr_dirty. # TYPE node_vmstat_nr_dirty untyped node_vmstat_nr_dirty 17 # HELP node_vmstat_nr_dirty_background_threshold /proc/vmstat information field nr_dirty_background_threshold. # TYPE node_vmstat_nr_dirty_background_threshold untyped node_vmstat_nr_dirty_background_threshold 39900 # HELP node_vmstat_nr_dirty_threshold /proc/vmstat information field nr_dirty_threshold. # TYPE node_vmstat_nr_dirty_threshold untyped node_vmstat_nr_dirty_threshold 119701 # HELP node_vmstat_nr_file_pages /proc/vmstat information field nr_file_pages. # TYPE node_vmstat_nr_file_pages untyped node_vmstat_nr_file_pages 76687 # HELP node_vmstat_nr_free_cma /proc/vmstat information field nr_free_cma. # TYPE node_vmstat_nr_free_cma untyped node_vmstat_nr_free_cma 0 # HELP node_vmstat_nr_free_pages /proc/vmstat information field nr_free_pages. # TYPE node_vmstat_nr_free_pages untyped node_vmstat_nr_free_pages 769929 # HELP node_vmstat_nr_inactive_anon /proc/vmstat information field nr_inactive_anon. # TYPE node_vmstat_nr_inactive_anon untyped node_vmstat_nr_inactive_anon 2091 # HELP node_vmstat_nr_inactive_file /proc/vmstat information field nr_inactive_file. # TYPE node_vmstat_nr_inactive_file untyped node_vmstat_nr_inactive_file 45688 # HELP node_vmstat_nr_isolated_anon /proc/vmstat information field nr_isolated_anon. # TYPE node_vmstat_nr_isolated_anon untyped node_vmstat_nr_isolated_anon 0 # HELP node_vmstat_nr_isolated_file /proc/vmstat information field nr_isolated_file. # TYPE node_vmstat_nr_isolated_file untyped node_vmstat_nr_isolated_file 0 # HELP node_vmstat_nr_kernel_stack /proc/vmstat information field nr_kernel_stack. # TYPE node_vmstat_nr_kernel_stack untyped node_vmstat_nr_kernel_stack 707 # HELP node_vmstat_nr_mapped /proc/vmstat information field nr_mapped. # TYPE node_vmstat_nr_mapped untyped node_vmstat_nr_mapped 16487 # HELP node_vmstat_nr_mlock /proc/vmstat information field nr_mlock. # TYPE node_vmstat_nr_mlock untyped node_vmstat_nr_mlock 0 # HELP node_vmstat_nr_page_table_pages /proc/vmstat information field nr_page_table_pages. # TYPE node_vmstat_nr_page_table_pages untyped node_vmstat_nr_page_table_pages 2223 # HELP node_vmstat_nr_shmem /proc/vmstat information field nr_shmem. # TYPE node_vmstat_nr_shmem untyped node_vmstat_nr_shmem 2151 # HELP node_vmstat_nr_slab_reclaimable /proc/vmstat information field nr_slab_reclaimable. # TYPE node_vmstat_nr_slab_reclaimable untyped node_vmstat_nr_slab_reclaimable 10898 # HELP node_vmstat_nr_slab_unreclaimable /proc/vmstat information field nr_slab_unreclaimable. # TYPE node_vmstat_nr_slab_unreclaimable untyped node_vmstat_nr_slab_unreclaimable 7827 # HELP node_vmstat_nr_unevictable /proc/vmstat information field nr_unevictable. # TYPE node_vmstat_nr_unevictable untyped node_vmstat_nr_unevictable 0 # HELP node_vmstat_nr_unstable /proc/vmstat information field nr_unstable. # TYPE node_vmstat_nr_unstable untyped node_vmstat_nr_unstable 0 # HELP node_vmstat_nr_vmscan_immediate_reclaim /proc/vmstat information field nr_vmscan_immediate_reclaim. # TYPE node_vmstat_nr_vmscan_immediate_reclaim untyped node_vmstat_nr_vmscan_immediate_reclaim 0 # HELP node_vmstat_nr_vmscan_write /proc/vmstat information field nr_vmscan_write. # TYPE node_vmstat_nr_vmscan_write untyped node_vmstat_nr_vmscan_write 0 # HELP node_vmstat_nr_writeback /proc/vmstat information field nr_writeback. # TYPE node_vmstat_nr_writeback untyped node_vmstat_nr_writeback 0 # HELP node_vmstat_nr_writeback_temp /proc/vmstat information field nr_writeback_temp. # TYPE node_vmstat_nr_writeback_temp untyped node_vmstat_nr_writeback_temp 0 # HELP node_vmstat_nr_written /proc/vmstat information field nr_written. # TYPE node_vmstat_nr_written untyped node_vmstat_nr_written 20344 # HELP node_vmstat_numa_foreign /proc/vmstat information field numa_foreign. # TYPE node_vmstat_numa_foreign untyped node_vmstat_numa_foreign 0 # HELP node_vmstat_numa_hint_faults /proc/vmstat information field numa_hint_faults. # TYPE node_vmstat_numa_hint_faults untyped node_vmstat_numa_hint_faults 0 # HELP node_vmstat_numa_hint_faults_local /proc/vmstat information field numa_hint_faults_local. # TYPE node_vmstat_numa_hint_faults_local untyped node_vmstat_numa_hint_faults_local 0 # HELP node_vmstat_numa_hit /proc/vmstat information field numa_hit. # TYPE node_vmstat_numa_hit untyped node_vmstat_numa_hit 824961 # HELP node_vmstat_numa_huge_pte_updates /proc/vmstat information field numa_huge_pte_updates. # TYPE node_vmstat_numa_huge_pte_updates untyped node_vmstat_numa_huge_pte_updates 0 # HELP node_vmstat_numa_interleave /proc/vmstat information field numa_interleave. # TYPE node_vmstat_numa_interleave untyped node_vmstat_numa_interleave 14563 # HELP node_vmstat_numa_local /proc/vmstat information field numa_local. # TYPE node_vmstat_numa_local untyped node_vmstat_numa_local 824961 # HELP node_vmstat_numa_miss /proc/vmstat information field numa_miss. # TYPE node_vmstat_numa_miss untyped node_vmstat_numa_miss 0 # HELP node_vmstat_numa_other /proc/vmstat information field numa_other. # TYPE node_vmstat_numa_other untyped node_vmstat_numa_other 0 # HELP node_vmstat_numa_pages_migrated /proc/vmstat information field numa_pages_migrated. # TYPE node_vmstat_numa_pages_migrated untyped node_vmstat_numa_pages_migrated 0 # HELP node_vmstat_numa_pte_updates /proc/vmstat information field numa_pte_updates. # TYPE node_vmstat_numa_pte_updates untyped node_vmstat_numa_pte_updates 0 # HELP node_vmstat_pageoutrun /proc/vmstat information field pageoutrun. # TYPE node_vmstat_pageoutrun untyped node_vmstat_pageoutrun 1 # HELP node_vmstat_pgactivate /proc/vmstat information field pgactivate. # TYPE node_vmstat_pgactivate untyped node_vmstat_pgactivate 30452 # HELP node_vmstat_pgalloc_dma /proc/vmstat information field pgalloc_dma. # TYPE node_vmstat_pgalloc_dma untyped node_vmstat_pgalloc_dma 487 # HELP node_vmstat_pgalloc_dma32 /proc/vmstat information field pgalloc_dma32. # TYPE node_vmstat_pgalloc_dma32 untyped node_vmstat_pgalloc_dma32 750526 # HELP node_vmstat_pgalloc_movable /proc/vmstat information field pgalloc_movable. # TYPE node_vmstat_pgalloc_movable untyped node_vmstat_pgalloc_movable 0 # HELP node_vmstat_pgalloc_normal /proc/vmstat information field pgalloc_normal. # TYPE node_vmstat_pgalloc_normal untyped node_vmstat_pgalloc_normal 124283 # HELP node_vmstat_pgdeactivate /proc/vmstat information field pgdeactivate. # TYPE node_vmstat_pgdeactivate untyped node_vmstat_pgdeactivate 0 # HELP node_vmstat_pgfault /proc/vmstat information field pgfault. # TYPE node_vmstat_pgfault untyped node_vmstat_pgfault 1.37842e+06 # HELP node_vmstat_pgfree /proc/vmstat information field pgfree. # TYPE node_vmstat_pgfree untyped node_vmstat_pgfree 1.645789e+06 # HELP node_vmstat_pginodesteal /proc/vmstat information field pginodesteal. # TYPE node_vmstat_pginodesteal untyped node_vmstat_pginodesteal 0 # HELP node_vmstat_pgmajfault /proc/vmstat information field pgmajfault. # TYPE node_vmstat_pgmajfault untyped node_vmstat_pgmajfault 4286 # HELP node_vmstat_pgmigrate_fail /proc/vmstat information field pgmigrate_fail. # TYPE node_vmstat_pgmigrate_fail untyped node_vmstat_pgmigrate_fail 0 # HELP node_vmstat_pgmigrate_success /proc/vmstat information field pgmigrate_success. # TYPE node_vmstat_pgmigrate_success untyped node_vmstat_pgmigrate_success 0 # HELP node_vmstat_pgpgin /proc/vmstat information field pgpgin. # TYPE node_vmstat_pgpgin untyped node_vmstat_pgpgin 289776 # HELP node_vmstat_pgpgout /proc/vmstat information field pgpgout. # TYPE node_vmstat_pgpgout untyped node_vmstat_pgpgout 139684 # HELP node_vmstat_pgrefill_dma /proc/vmstat information field pgrefill_dma. # TYPE node_vmstat_pgrefill_dma untyped node_vmstat_pgrefill_dma 0 # HELP node_vmstat_pgrefill_dma32 /proc/vmstat information field pgrefill_dma32. # TYPE node_vmstat_pgrefill_dma32 untyped node_vmstat_pgrefill_dma32 0 # HELP node_vmstat_pgrefill_movable /proc/vmstat information field pgrefill_movable. # TYPE node_vmstat_pgrefill_movable untyped node_vmstat_pgrefill_movable 0 # HELP node_vmstat_pgrefill_normal /proc/vmstat information field pgrefill_normal. # TYPE node_vmstat_pgrefill_normal untyped node_vmstat_pgrefill_normal 0 # HELP node_vmstat_pgrotated /proc/vmstat information field pgrotated. # TYPE node_vmstat_pgrotated untyped node_vmstat_pgrotated 0 # HELP node_vmstat_pgscan_direct_dma /proc/vmstat information field pgscan_direct_dma. # TYPE node_vmstat_pgscan_direct_dma untyped node_vmstat_pgscan_direct_dma 0 # HELP node_vmstat_pgscan_direct_dma32 /proc/vmstat information field pgscan_direct_dma32. # TYPE node_vmstat_pgscan_direct_dma32 untyped node_vmstat_pgscan_direct_dma32 0 # HELP node_vmstat_pgscan_direct_movable /proc/vmstat information field pgscan_direct_movable. # TYPE node_vmstat_pgscan_direct_movable untyped node_vmstat_pgscan_direct_movable 0 # HELP node_vmstat_pgscan_direct_normal /proc/vmstat information field pgscan_direct_normal. # TYPE node_vmstat_pgscan_direct_normal untyped node_vmstat_pgscan_direct_normal 0 # HELP node_vmstat_pgscan_direct_throttle /proc/vmstat information field pgscan_direct_throttle. # TYPE node_vmstat_pgscan_direct_throttle untyped node_vmstat_pgscan_direct_throttle 0 # HELP node_vmstat_pgscan_kswapd_dma /proc/vmstat information field pgscan_kswapd_dma. # TYPE node_vmstat_pgscan_kswapd_dma untyped node_vmstat_pgscan_kswapd_dma 0 # HELP node_vmstat_pgscan_kswapd_dma32 /proc/vmstat information field pgscan_kswapd_dma32. # TYPE node_vmstat_pgscan_kswapd_dma32 untyped node_vmstat_pgscan_kswapd_dma32 0 # HELP node_vmstat_pgscan_kswapd_movable /proc/vmstat information field pgscan_kswapd_movable. # TYPE node_vmstat_pgscan_kswapd_movable untyped node_vmstat_pgscan_kswapd_movable 0 # HELP node_vmstat_pgscan_kswapd_normal /proc/vmstat information field pgscan_kswapd_normal. # TYPE node_vmstat_pgscan_kswapd_normal untyped node_vmstat_pgscan_kswapd_normal 0 # HELP node_vmstat_pgsteal_direct_dma /proc/vmstat information field pgsteal_direct_dma. # TYPE node_vmstat_pgsteal_direct_dma untyped node_vmstat_pgsteal_direct_dma 0 # HELP node_vmstat_pgsteal_direct_dma32 /proc/vmstat information field pgsteal_direct_dma32. # TYPE node_vmstat_pgsteal_direct_dma32 untyped node_vmstat_pgsteal_direct_dma32 0 # HELP node_vmstat_pgsteal_direct_movable /proc/vmstat information field pgsteal_direct_movable. # TYPE node_vmstat_pgsteal_direct_movable untyped node_vmstat_pgsteal_direct_movable 0 # HELP node_vmstat_pgsteal_direct_normal /proc/vmstat information field pgsteal_direct_normal. # TYPE node_vmstat_pgsteal_direct_normal untyped node_vmstat_pgsteal_direct_normal 0 # HELP node_vmstat_pgsteal_kswapd_dma /proc/vmstat information field pgsteal_kswapd_dma. # TYPE node_vmstat_pgsteal_kswapd_dma untyped node_vmstat_pgsteal_kswapd_dma 0 # HELP node_vmstat_pgsteal_kswapd_dma32 /proc/vmstat information field pgsteal_kswapd_dma32. # TYPE node_vmstat_pgsteal_kswapd_dma32 untyped node_vmstat_pgsteal_kswapd_dma32 0 # HELP node_vmstat_pgsteal_kswapd_movable /proc/vmstat information field pgsteal_kswapd_movable. # TYPE node_vmstat_pgsteal_kswapd_movable untyped node_vmstat_pgsteal_kswapd_movable 0 # HELP node_vmstat_pgsteal_kswapd_normal /proc/vmstat information field pgsteal_kswapd_normal. # TYPE node_vmstat_pgsteal_kswapd_normal untyped node_vmstat_pgsteal_kswapd_normal 0 # HELP node_vmstat_pswpin /proc/vmstat information field pswpin. # TYPE node_vmstat_pswpin untyped node_vmstat_pswpin 0 # HELP node_vmstat_pswpout /proc/vmstat information field pswpout. # TYPE node_vmstat_pswpout untyped node_vmstat_pswpout 0 # HELP node_vmstat_slabs_scanned /proc/vmstat information field slabs_scanned. # TYPE node_vmstat_slabs_scanned untyped node_vmstat_slabs_scanned 0 # HELP node_vmstat_thp_collapse_alloc /proc/vmstat information field thp_collapse_alloc. # TYPE node_vmstat_thp_collapse_alloc untyped node_vmstat_thp_collapse_alloc 0 # HELP node_vmstat_thp_collapse_alloc_failed /proc/vmstat information field thp_collapse_alloc_failed. # TYPE node_vmstat_thp_collapse_alloc_failed untyped node_vmstat_thp_collapse_alloc_failed 0 # HELP node_vmstat_thp_fault_alloc /proc/vmstat information field thp_fault_alloc. # TYPE node_vmstat_thp_fault_alloc untyped node_vmstat_thp_fault_alloc 53 # HELP node_vmstat_thp_fault_fallback /proc/vmstat information field thp_fault_fallback. # TYPE node_vmstat_thp_fault_fallback untyped node_vmstat_thp_fault_fallback 0 # HELP node_vmstat_thp_split /proc/vmstat information field thp_split. # TYPE node_vmstat_thp_split untyped node_vmstat_thp_split 1 # HELP node_vmstat_thp_zero_page_alloc /proc/vmstat information field thp_zero_page_alloc. # TYPE node_vmstat_thp_zero_page_alloc untyped node_vmstat_thp_zero_page_alloc 0 # HELP node_vmstat_thp_zero_page_alloc_failed /proc/vmstat information field thp_zero_page_alloc_failed. # TYPE node_vmstat_thp_zero_page_alloc_failed untyped node_vmstat_thp_zero_page_alloc_failed 0 # HELP node_vmstat_unevictable_pgs_cleared /proc/vmstat information field unevictable_pgs_cleared. # TYPE node_vmstat_unevictable_pgs_cleared untyped node_vmstat_unevictable_pgs_cleared 0 # HELP node_vmstat_unevictable_pgs_culled /proc/vmstat information field unevictable_pgs_culled. # TYPE node_vmstat_unevictable_pgs_culled untyped node_vmstat_unevictable_pgs_culled 8348 # HELP node_vmstat_unevictable_pgs_mlocked /proc/vmstat information field unevictable_pgs_mlocked. # TYPE node_vmstat_unevictable_pgs_mlocked untyped node_vmstat_unevictable_pgs_mlocked 11226 # HELP node_vmstat_unevictable_pgs_munlocked /proc/vmstat information field unevictable_pgs_munlocked. # TYPE node_vmstat_unevictable_pgs_munlocked untyped node_vmstat_unevictable_pgs_munlocked 9966 # HELP node_vmstat_unevictable_pgs_rescued /proc/vmstat information field unevictable_pgs_rescued. # TYPE node_vmstat_unevictable_pgs_rescued untyped node_vmstat_unevictable_pgs_rescued 7446 # HELP node_vmstat_unevictable_pgs_scanned /proc/vmstat information field unevictable_pgs_scanned. # TYPE node_vmstat_unevictable_pgs_scanned untyped node_vmstat_unevictable_pgs_scanned 0 # HELP node_vmstat_unevictable_pgs_stranded /proc/vmstat information field unevictable_pgs_stranded. # TYPE node_vmstat_unevictable_pgs_stranded untyped node_vmstat_unevictable_pgs_stranded 0 # HELP node_vmstat_workingset_activate /proc/vmstat information field workingset_activate. # TYPE node_vmstat_workingset_activate untyped node_vmstat_workingset_activate 0 # HELP node_vmstat_workingset_nodereclaim /proc/vmstat information field workingset_nodereclaim. # TYPE node_vmstat_workingset_nodereclaim untyped node_vmstat_workingset_nodereclaim 0 # HELP node_vmstat_workingset_refault /proc/vmstat information field workingset_refault. # TYPE node_vmstat_workingset_refault untyped node_vmstat_workingset_refault 0 # HELP node_vmstat_zone_reclaim_failed /proc/vmstat information field zone_reclaim_failed. # TYPE node_vmstat_zone_reclaim_failed untyped node_vmstat_zone_reclaim_failed 0 |
percona/mongodb_exporter (mongodb:metrics)
Behind the scenes of the “mongodb:metric” Percona Monitoring and Management service, percona/mongodb_exporter is the Prometheus exporter that provides detailed database metrics for graphing on the Percona Monitoring and Management server. percona/mongodb_exporter is a Percona fork of the project dcu/mongodb_exporter, with some valuable additional metrics for MongoDB sharding, storage engines, etc.
The mongodb_exporter process is designed to automatically detect the MongoDB node type, storage engine, etc., without any special configuration aside from the connection string.
As of Percona Monitoring and Management 1.1.1, here are the number of metrics collected from a single replication-enabled mongodb instance on a single ‘pull’ from Prometheus:
Note: each additional replica set member adds an additional seven metrics to the list of metrics.
On the sharding side of things, a “mongos” process within a cluster with one shard reports 58 metrics, with one extra metric added for each additional cluster shard and 3-4 extra metrics added for each additional “mongos” instance.
Below is a full example of a single “pull” of metrics from one RocksDB instance. Prometheus exporters provide metrics at the HTTP URL: “/metrics”. This is the exact same payload Prometheus would poll from the exporter:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 |
$ curl -sk https://192.168.99.10:42003/metrics | grep mongodb # HELP mongodb_mongod_asserts_total The asserts document reports the number of asserts on the database. While assert errors are typically uncommon, if there are non-zero values for the asserts, you should check the log file for the mongod process for more information. In many cases these errors are trivial, but are worth investigating. # TYPE mongodb_mongod_asserts_total counter mongodb_mongod_asserts_total{type="msg"} 0 mongodb_mongod_asserts_total{type="regular"} 0 mongodb_mongod_asserts_total{type="rollovers"} 0 mongodb_mongod_asserts_total{type="user"} 1 mongodb_mongod_asserts_total{type="warning"} 0 # HELP mongodb_mongod_connections The connections sub document data regarding the current status of incoming connections and availability of the database server. Use these values to assess the current load and capacity requirements of the server # TYPE mongodb_mongod_connections gauge mongodb_mongod_connections{state="available"} 811 mongodb_mongod_connections{state="current"} 8 # HELP mongodb_mongod_connections_metrics_created_total totalCreated provides a count of all incoming connections created to the server. This number includes connections that have since closed # TYPE mongodb_mongod_connections_metrics_created_total counter mongodb_mongod_connections_metrics_created_total 1977 # HELP mongodb_mongod_extra_info_heap_usage_bytes The heap_usage_bytes field is only available on Unix/Linux systems, and reports the total size in bytes of heap space used by the database process # TYPE mongodb_mongod_extra_info_heap_usage_bytes gauge mongodb_mongod_extra_info_heap_usage_bytes 7.77654e+07 # HELP mongodb_mongod_extra_info_page_faults_total The page_faults Reports the total number of page faults that require disk operations. Page faults refer to operations that require the database server to access data which isn’t available in active memory. The page_faults counter may increase dramatically during moments of poor performance and may correlate with limited memory environments and larger data sets. Limited and sporadic page faults do not necessarily indicate an issue # TYPE mongodb_mongod_extra_info_page_faults_total gauge mongodb_mongod_extra_info_page_faults_total 47 # HELP mongodb_mongod_global_lock_client The activeClients data structure provides more granular information about the number of connected clients and the operation types (e.g. read or write) performed by these clients # TYPE mongodb_mongod_global_lock_client gauge mongodb_mongod_global_lock_client{type="reader"} 0 mongodb_mongod_global_lock_client{type="writer"} 0 # HELP mongodb_mongod_global_lock_current_queue The currentQueue data structure value provides more granular information concerning the number of operations queued because of a lock # TYPE mongodb_mongod_global_lock_current_queue gauge mongodb_mongod_global_lock_current_queue{type="reader"} 0 mongodb_mongod_global_lock_current_queue{type="writer"} 0 # HELP mongodb_mongod_global_lock_ratio The value of ratio displays the relationship between lockTime and totalTime. Low values indicate that operations have held the globalLock frequently for shorter periods of time. High values indicate that operations have held globalLock infrequently for longer periods of time # TYPE mongodb_mongod_global_lock_ratio gauge mongodb_mongod_global_lock_ratio 0 # HELP mongodb_mongod_global_lock_total The value of totalTime represents the time, in microseconds, since the database last started and creation of the globalLock. This is roughly equivalent to total server uptime # TYPE mongodb_mongod_global_lock_total counter mongodb_mongod_global_lock_total 0 # HELP mongodb_mongod_instance_local_time The localTime value is the current time, according to the server, in UTC specified in an ISODate format. # TYPE mongodb_mongod_instance_local_time counter mongodb_mongod_instance_local_time 1.488834066e+09 # HELP mongodb_mongod_instance_uptime_estimate_seconds uptimeEstimate provides the uptime as calculated from MongoDB's internal course-grained time keeping system. # TYPE mongodb_mongod_instance_uptime_estimate_seconds counter mongodb_mongod_instance_uptime_estimate_seconds 15881 # HELP mongodb_mongod_instance_uptime_seconds The value of the uptime field corresponds to the number of seconds that the mongos or mongod process has been active. # TYPE mongodb_mongod_instance_uptime_seconds counter mongodb_mongod_instance_uptime_seconds 15881 # HELP mongodb_mongod_locks_time_acquiring_global_microseconds_total amount of time in microseconds that any database has spent waiting for the global lock # TYPE mongodb_mongod_locks_time_acquiring_global_microseconds_total counter mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Collection",type="read"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Collection",type="write"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Database",type="read"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Database",type="write"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Global",type="read"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Global",type="write"} 5005 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Metadata",type="read"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="Metadata",type="write"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="oplog",type="read"} 0 mongodb_mongod_locks_time_acquiring_global_microseconds_total{database="oplog",type="write"} 0 # HELP mongodb_mongod_locks_time_locked_global_microseconds_total amount of time in microseconds that any database has held the global lock # TYPE mongodb_mongod_locks_time_locked_global_microseconds_total counter mongodb_mongod_locks_time_locked_global_microseconds_total{database="Collection",type="read"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Collection",type="write"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Database",type="read"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Database",type="write"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Global",type="read"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Global",type="write"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Metadata",type="read"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="Metadata",type="write"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="oplog",type="read"} 0 mongodb_mongod_locks_time_locked_global_microseconds_total{database="oplog",type="write"} 0 # HELP mongodb_mongod_locks_time_locked_local_microseconds_total amount of time in microseconds that any database has held the local lock # TYPE mongodb_mongod_locks_time_locked_local_microseconds_total counter mongodb_mongod_locks_time_locked_local_microseconds_total{database="Collection",type="read"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Collection",type="write"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Database",type="read"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Database",type="write"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Global",type="read"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Global",type="write"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Metadata",type="read"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="Metadata",type="write"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="oplog",type="read"} 0 mongodb_mongod_locks_time_locked_local_microseconds_total{database="oplog",type="write"} 0 # HELP mongodb_mongod_memory The mem data structure holds information regarding the target system architecture of mongod and current memory use # TYPE mongodb_mongod_memory gauge mongodb_mongod_memory{type="mapped"} 0 mongodb_mongod_memory{type="mapped_with_journal"} 0 mongodb_mongod_memory{type="resident"} 205 mongodb_mongod_memory{type="virtual"} 1064 # HELP mongodb_mongod_metrics_cursor_open The open is an embedded document that contains data regarding open cursors # TYPE mongodb_mongod_metrics_cursor_open gauge mongodb_mongod_metrics_cursor_open{state="noTimeout"} 0 mongodb_mongod_metrics_cursor_open{state="pinned"} 1 mongodb_mongod_metrics_cursor_open{state="total"} 1 # HELP mongodb_mongod_metrics_cursor_timed_out_total timedOut provides the total number of cursors that have timed out since the server process started. If this number is large or growing at a regular rate, this may indicate an application error # TYPE mongodb_mongod_metrics_cursor_timed_out_total counter mongodb_mongod_metrics_cursor_timed_out_total 0 # HELP mongodb_mongod_metrics_document_total The document holds a document of that reflect document access and modification patterns and data use. Compare these values to the data in the opcounters document, which track total number of operations # TYPE mongodb_mongod_metrics_document_total counter mongodb_mongod_metrics_document_total{state="deleted"} 0 mongodb_mongod_metrics_document_total{state="inserted"} 140396 mongodb_mongod_metrics_document_total{state="returned"} 74105 mongodb_mongod_metrics_document_total{state="updated"} 0 # HELP mongodb_mongod_metrics_get_last_error_wtime_num_total num reports the total number of getLastError operations with a specified write concern (i.e. w) that wait for one or more members of a replica set to acknowledge the write operation (i.e. a w value greater than 1.) # TYPE mongodb_mongod_metrics_get_last_error_wtime_num_total gauge mongodb_mongod_metrics_get_last_error_wtime_num_total 0 # HELP mongodb_mongod_metrics_get_last_error_wtime_total_milliseconds total_millis reports the total amount of time in milliseconds that the mongod has spent performing getLastError operations with write concern (i.e. w) that wait for one or more members of a replica set to acknowledge the write operation (i.e. a w value greater than 1.) # TYPE mongodb_mongod_metrics_get_last_error_wtime_total_milliseconds counter mongodb_mongod_metrics_get_last_error_wtime_total_milliseconds 0 # HELP mongodb_mongod_metrics_get_last_error_wtimeouts_total wtimeouts reports the number of times that write concern operations have timed out as a result of the wtimeout threshold to getLastError. # TYPE mongodb_mongod_metrics_get_last_error_wtimeouts_total counter mongodb_mongod_metrics_get_last_error_wtimeouts_total 0 # HELP mongodb_mongod_metrics_operation_total operation is a sub-document that holds counters for several types of update and query operations that MongoDB handles using special operation types # TYPE mongodb_mongod_metrics_operation_total counter mongodb_mongod_metrics_operation_total{type="fastmod"} 0 mongodb_mongod_metrics_operation_total{type="idhack"} 0 mongodb_mongod_metrics_operation_total{type="scan_and_order"} 0 # HELP mongodb_mongod_metrics_query_executor_total queryExecutor is a document that reports data from the query execution system # TYPE mongodb_mongod_metrics_query_executor_total counter mongodb_mongod_metrics_query_executor_total{state="scanned"} 0 mongodb_mongod_metrics_query_executor_total{state="scanned_objects"} 74105 # HELP mongodb_mongod_metrics_record_moves_total moves reports the total number of times documents move within the on-disk representation of the MongoDB data set. Documents move as a result of operations that increase the size of the document beyond their allocated record size # TYPE mongodb_mongod_metrics_record_moves_total counter mongodb_mongod_metrics_record_moves_total 0 # HELP mongodb_mongod_metrics_repl_apply_batches_num_total num reports the total number of batches applied across all databases # TYPE mongodb_mongod_metrics_repl_apply_batches_num_total counter mongodb_mongod_metrics_repl_apply_batches_num_total 0 # HELP mongodb_mongod_metrics_repl_apply_batches_total_milliseconds total_millis reports the total amount of time the mongod has spent applying operations from the oplog # TYPE mongodb_mongod_metrics_repl_apply_batches_total_milliseconds counter mongodb_mongod_metrics_repl_apply_batches_total_milliseconds 0 # HELP mongodb_mongod_metrics_repl_apply_ops_total ops reports the total number of oplog operations applied # TYPE mongodb_mongod_metrics_repl_apply_ops_total counter mongodb_mongod_metrics_repl_apply_ops_total 0 # HELP mongodb_mongod_metrics_repl_buffer_count count reports the current number of operations in the oplog buffer # TYPE mongodb_mongod_metrics_repl_buffer_count gauge mongodb_mongod_metrics_repl_buffer_count 0 # HELP mongodb_mongod_metrics_repl_buffer_max_size_bytes maxSizeBytes reports the maximum size of the buffer. This value is a constant setting in the mongod, and is not configurable # TYPE mongodb_mongod_metrics_repl_buffer_max_size_bytes counter mongodb_mongod_metrics_repl_buffer_max_size_bytes 2.68435456e+08 # HELP mongodb_mongod_metrics_repl_buffer_size_bytes sizeBytes reports the current size of the contents of the oplog buffer # TYPE mongodb_mongod_metrics_repl_buffer_size_bytes gauge mongodb_mongod_metrics_repl_buffer_size_bytes 0 # HELP mongodb_mongod_metrics_repl_network_bytes_total bytes reports the total amount of data read from the replication sync source # TYPE mongodb_mongod_metrics_repl_network_bytes_total counter mongodb_mongod_metrics_repl_network_bytes_total 0 # HELP mongodb_mongod_metrics_repl_network_getmores_num_total num reports the total number of getmore operations, which are operations that request an additional set of operations from the replication sync source. # TYPE mongodb_mongod_metrics_repl_network_getmores_num_total counter mongodb_mongod_metrics_repl_network_getmores_num_total 0 # HELP mongodb_mongod_metrics_repl_network_getmores_total_milliseconds total_millis reports the total amount of time required to collect data from getmore operations # TYPE mongodb_mongod_metrics_repl_network_getmores_total_milliseconds counter mongodb_mongod_metrics_repl_network_getmores_total_milliseconds 0 # HELP mongodb_mongod_metrics_repl_network_ops_total ops reports the total number of operations read from the replication source. # TYPE mongodb_mongod_metrics_repl_network_ops_total counter mongodb_mongod_metrics_repl_network_ops_total 0 # HELP mongodb_mongod_metrics_repl_network_readers_created_total readersCreated reports the total number of oplog query processes created. MongoDB will create a new oplog query any time an error occurs in the connection, including a timeout, or a network operation. Furthermore, readersCreated will increment every time MongoDB selects a new source fore replication. # TYPE mongodb_mongod_metrics_repl_network_readers_created_total counter mongodb_mongod_metrics_repl_network_readers_created_total 1 # HELP mongodb_mongod_metrics_repl_oplog_insert_bytes_total insertBytes the total size of documents inserted into the oplog. # TYPE mongodb_mongod_metrics_repl_oplog_insert_bytes_total counter mongodb_mongod_metrics_repl_oplog_insert_bytes_total 0 # HELP mongodb_mongod_metrics_repl_oplog_insert_num_total num reports the total number of items inserted into the oplog. # TYPE mongodb_mongod_metrics_repl_oplog_insert_num_total counter mongodb_mongod_metrics_repl_oplog_insert_num_total 0 # HELP mongodb_mongod_metrics_repl_oplog_insert_total_milliseconds total_millis reports the total amount of time spent for the mongod to insert data into the oplog. # TYPE mongodb_mongod_metrics_repl_oplog_insert_total_milliseconds counter mongodb_mongod_metrics_repl_oplog_insert_total_milliseconds 0 # HELP mongodb_mongod_metrics_repl_preload_docs_num_total num reports the total number of documents loaded during the pre-fetch stage of replication # TYPE mongodb_mongod_metrics_repl_preload_docs_num_total counter mongodb_mongod_metrics_repl_preload_docs_num_total 0 # HELP mongodb_mongod_metrics_repl_preload_docs_total_milliseconds total_millis reports the total amount of time spent loading documents as part of the pre-fetch stage of replication # TYPE mongodb_mongod_metrics_repl_preload_docs_total_milliseconds counter mongodb_mongod_metrics_repl_preload_docs_total_milliseconds 0 # HELP mongodb_mongod_metrics_repl_preload_indexes_num_total num reports the total number of index entries loaded by members before updating documents as part of the pre-fetch stage of replication # TYPE mongodb_mongod_metrics_repl_preload_indexes_num_total counter mongodb_mongod_metrics_repl_preload_indexes_num_total 0 # HELP mongodb_mongod_metrics_repl_preload_indexes_total_milliseconds total_millis reports the total amount of time spent loading index entries as part of the pre-fetch stage of replication # TYPE mongodb_mongod_metrics_repl_preload_indexes_total_milliseconds counter mongodb_mongod_metrics_repl_preload_indexes_total_milliseconds 0 # HELP mongodb_mongod_metrics_storage_freelist_search_total metrics about searching records in the database. # TYPE mongodb_mongod_metrics_storage_freelist_search_total counter mongodb_mongod_metrics_storage_freelist_search_total{type="bucket_exhausted"} 0 mongodb_mongod_metrics_storage_freelist_search_total{type="requests"} 0 mongodb_mongod_metrics_storage_freelist_search_total{type="scanned"} 0 # HELP mongodb_mongod_metrics_ttl_deleted_documents_total deletedDocuments reports the total number of documents deleted from collections with a ttl index. # TYPE mongodb_mongod_metrics_ttl_deleted_documents_total counter mongodb_mongod_metrics_ttl_deleted_documents_total 0 # HELP mongodb_mongod_metrics_ttl_passes_total passes reports the number of times the background process removes documents from collections with a ttl index # TYPE mongodb_mongod_metrics_ttl_passes_total counter mongodb_mongod_metrics_ttl_passes_total 0 # HELP mongodb_mongod_network_bytes_total The network data structure contains data regarding MongoDB’s network use # TYPE mongodb_mongod_network_bytes_total counter mongodb_mongod_network_bytes_total{state="in_bytes"} 1.323188842e+09 mongodb_mongod_network_bytes_total{state="out_bytes"} 1.401963024e+09 # HELP mongodb_mongod_network_metrics_num_requests_total The numRequests field is a counter of the total number of distinct requests that the server has received. Use this value to provide context for the bytesIn and bytesOut values to ensure that MongoDB’s network utilization is consistent with expectations and application use # TYPE mongodb_mongod_network_metrics_num_requests_total counter mongodb_mongod_network_metrics_num_requests_total 313023 # HELP mongodb_mongod_op_counters_repl_total The opcountersRepl data structure, similar to the opcounters data structure, provides an overview of database replication operations by type and makes it possible to analyze the load on the replica in more granular manner. These values only appear when the current host has replication enabled # TYPE mongodb_mongod_op_counters_repl_total counter mongodb_mongod_op_counters_repl_total{type="command"} 0 mongodb_mongod_op_counters_repl_total{type="delete"} 0 mongodb_mongod_op_counters_repl_total{type="getmore"} 0 mongodb_mongod_op_counters_repl_total{type="insert"} 0 mongodb_mongod_op_counters_repl_total{type="query"} 0 mongodb_mongod_op_counters_repl_total{type="update"} 0 # HELP mongodb_mongod_op_counters_total The opcounters data structure provides an overview of database operations by type and makes it possible to analyze the load on the database in more granular manner. These numbers will grow over time and in response to database use. Analyze these values over time to track database utilization # TYPE mongodb_mongod_op_counters_total counter mongodb_mongod_op_counters_total{type="command"} 164008 mongodb_mongod_op_counters_total{type="delete"} 0 mongodb_mongod_op_counters_total{type="getmore"} 74912 mongodb_mongod_op_counters_total{type="insert"} 70198 mongodb_mongod_op_counters_total{type="query"} 3907 mongodb_mongod_op_counters_total{type="update"} 0 # HELP mongodb_mongod_replset_heatbeat_interval_millis The frequency in milliseconds of the heartbeats # TYPE mongodb_mongod_replset_heatbeat_interval_millis gauge mongodb_mongod_replset_heatbeat_interval_millis{set="test1"} 2000 # HELP mongodb_mongod_replset_member_config_version The configVersion value is the replica set configuration version. # TYPE mongodb_mongod_replset_member_config_version gauge mongodb_mongod_replset_member_config_version{name="localhost:27017",set="test1",state="PRIMARY"} 2 mongodb_mongod_replset_member_config_version{name="localhost:27027",set="test1",state="SECONDARY"} 2 # HELP mongodb_mongod_replset_member_election_date The timestamp the node was elected as replica leader # TYPE mongodb_mongod_replset_member_election_date gauge mongodb_mongod_replset_member_election_date{name="localhost:27017",set="test1",state="PRIMARY"} 1.488818198e+09 # HELP mongodb_mongod_replset_member_health This field conveys if the member is up (1) or down (0). # TYPE mongodb_mongod_replset_member_health gauge mongodb_mongod_replset_member_health{name="localhost:27017",set="test1",state="PRIMARY"} 1 mongodb_mongod_replset_member_health{name="localhost:27027",set="test1",state="SECONDARY"} 1 # HELP mongodb_mongod_replset_member_last_heartbeat The lastHeartbeat value provides an ISODate formatted date and time of the transmission time of last heartbeat received from this member # TYPE mongodb_mongod_replset_member_last_heartbeat gauge mongodb_mongod_replset_member_last_heartbeat{name="localhost:27027",set="test1",state="SECONDARY"} 1.488834065e+09 # HELP mongodb_mongod_replset_member_last_heartbeat_recv The lastHeartbeatRecv value provides an ISODate formatted date and time that the last heartbeat was received from this member # TYPE mongodb_mongod_replset_member_last_heartbeat_recv gauge mongodb_mongod_replset_member_last_heartbeat_recv{name="localhost:27027",set="test1",state="SECONDARY"} 1.488834066e+09 # HELP mongodb_mongod_replset_member_optime_date The timestamp of the last oplog entry that this member applied. # TYPE mongodb_mongod_replset_member_optime_date gauge mongodb_mongod_replset_member_optime_date{name="localhost:27017",set="test1",state="PRIMARY"} 1.488833953e+09 mongodb_mongod_replset_member_optime_date{name="localhost:27027",set="test1",state="SECONDARY"} 1.488833953e+09 # HELP mongodb_mongod_replset_member_ping_ms The pingMs represents the number of milliseconds (ms) that a round-trip packet takes to travel between the remote member and the local instance. # TYPE mongodb_mongod_replset_member_ping_ms gauge mongodb_mongod_replset_member_ping_ms{name="localhost:27027",set="test1",state="SECONDARY"} 0 # HELP mongodb_mongod_replset_member_state The value of state is an integer between 0 and 10 that represents the replica state of the member. # TYPE mongodb_mongod_replset_member_state gauge mongodb_mongod_replset_member_state{name="localhost:27017",set="test1",state="PRIMARY"} 1 mongodb_mongod_replset_member_state{name="localhost:27027",set="test1",state="SECONDARY"} 2 # HELP mongodb_mongod_replset_member_uptime The uptime field holds a value that reflects the number of seconds that this member has been online. # TYPE mongodb_mongod_replset_member_uptime counter mongodb_mongod_replset_member_uptime{name="localhost:27017",set="test1",state="PRIMARY"} 15881 mongodb_mongod_replset_member_uptime{name="localhost:27027",set="test1",state="SECONDARY"} 15855 # HELP mongodb_mongod_replset_my_name The replica state name of the current member # TYPE mongodb_mongod_replset_my_name gauge mongodb_mongod_replset_my_name{name="localhost:27017",set="test1"} 1 # HELP mongodb_mongod_replset_my_state An integer between 0 and 10 that represents the replica state of the current member # TYPE mongodb_mongod_replset_my_state gauge mongodb_mongod_replset_my_state{set="test1"} 1 # HELP mongodb_mongod_replset_number_of_members The number of replica set mebers # TYPE mongodb_mongod_replset_number_of_members gauge mongodb_mongod_replset_number_of_members{set="test1"} 2 # HELP mongodb_mongod_replset_oplog_head_timestamp The timestamp of the newest change in the oplog # TYPE mongodb_mongod_replset_oplog_head_timestamp gauge mongodb_mongod_replset_oplog_head_timestamp 1.488833953e+09 # HELP mongodb_mongod_replset_oplog_items_total The total number of changes in the oplog # TYPE mongodb_mongod_replset_oplog_items_total gauge mongodb_mongod_replset_oplog_items_total 70202 # HELP mongodb_mongod_replset_oplog_size_bytes Size of oplog in bytes # TYPE mongodb_mongod_replset_oplog_size_bytes gauge mongodb_mongod_replset_oplog_size_bytes{type="current"} 1.273140034e+09 mongodb_mongod_replset_oplog_size_bytes{type="storage"} 1.273139968e+09 # HELP mongodb_mongod_replset_oplog_tail_timestamp The timestamp of the oldest change in the oplog # TYPE mongodb_mongod_replset_oplog_tail_timestamp gauge mongodb_mongod_replset_oplog_tail_timestamp 1.488818198e+09 # HELP mongodb_mongod_replset_term The election count for the replica set, as known to this replica set member # TYPE mongodb_mongod_replset_term gauge mongodb_mongod_replset_term{set="test1"} 1 # HELP mongodb_mongod_rocksdb_background_errors The total number of background errors in RocksDB # TYPE mongodb_mongod_rocksdb_background_errors gauge mongodb_mongod_rocksdb_background_errors 0 # HELP mongodb_mongod_rocksdb_block_cache_bytes The current bytes used in the RocksDB Block Cache # TYPE mongodb_mongod_rocksdb_block_cache_bytes gauge mongodb_mongod_rocksdb_block_cache_bytes 2.5165824e+07 # HELP mongodb_mongod_rocksdb_block_cache_hits_total The total number of hits to the RocksDB Block Cache # TYPE mongodb_mongod_rocksdb_block_cache_hits_total counter mongodb_mongod_rocksdb_block_cache_hits_total 519483 # HELP mongodb_mongod_rocksdb_block_cache_misses_total The total number of misses to the RocksDB Block Cache # TYPE mongodb_mongod_rocksdb_block_cache_misses_total counter mongodb_mongod_rocksdb_block_cache_misses_total 219214 # HELP mongodb_mongod_rocksdb_bloom_filter_useful_total The total number of times the RocksDB Bloom Filter was useful # TYPE mongodb_mongod_rocksdb_bloom_filter_useful_total counter mongodb_mongod_rocksdb_bloom_filter_useful_total 130251 # HELP mongodb_mongod_rocksdb_bytes_read_total The total number of bytes read by RocksDB # TYPE mongodb_mongod_rocksdb_bytes_read_total counter mongodb_mongod_rocksdb_bytes_read_total{type="compation"} 7.917332498e+09 mongodb_mongod_rocksdb_bytes_read_total{type="iteration"} 3.94838428e+09 mongodb_mongod_rocksdb_bytes_read_total{type="point_lookup"} 2.655612381e+09 # HELP mongodb_mongod_rocksdb_bytes_written_total The total number of bytes written by RocksDB # TYPE mongodb_mongod_rocksdb_bytes_written_total counter mongodb_mongod_rocksdb_bytes_written_total{type="compaction"} 9.531638929e+09 mongodb_mongod_rocksdb_bytes_written_total{type="flush"} 2.525874187e+09 mongodb_mongod_rocksdb_bytes_written_total{type="total"} 2.548843861e+09 # HELP mongodb_mongod_rocksdb_compaction_average_seconds The average time per compaction between levels N and N+1 in RocksDB # TYPE mongodb_mongod_rocksdb_compaction_average_seconds gauge mongodb_mongod_rocksdb_compaction_average_seconds{level="L0"} 0.505 mongodb_mongod_rocksdb_compaction_average_seconds{level="L5"} 3.606 mongodb_mongod_rocksdb_compaction_average_seconds{level="L6"} 14.579 mongodb_mongod_rocksdb_compaction_average_seconds{level="total"} 4.583 # HELP mongodb_mongod_rocksdb_compaction_bytes_per_second The rate at which data is processed during compaction between levels N and N+1 in RocksDB # TYPE mongodb_mongod_rocksdb_compaction_bytes_per_second gauge mongodb_mongod_rocksdb_compaction_bytes_per_second{level="L0",type="write"} 1.248854016e+08 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="L5",type="read"} 7.45537536e+07 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="L5",type="write"} 7.45537536e+07 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="L6",type="read"} 2.44318208e+07 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="L6",type="write"} 2.06569472e+07 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="total",type="read"} 2.70532608e+07 mongodb_mongod_rocksdb_compaction_bytes_per_second{level="total",type="write"} 3.2505856e+07 # HELP mongodb_mongod_rocksdb_compaction_file_threads The number of threads currently doing compaction for levels in RocksDB # TYPE mongodb_mongod_rocksdb_compaction_file_threads gauge mongodb_mongod_rocksdb_compaction_file_threads{level="L0"} 0 mongodb_mongod_rocksdb_compaction_file_threads{level="L5"} 0 mongodb_mongod_rocksdb_compaction_file_threads{level="L6"} 0 mongodb_mongod_rocksdb_compaction_file_threads{level="total"} 0 # HELP mongodb_mongod_rocksdb_compaction_score The compaction score of RocksDB levels # TYPE mongodb_mongod_rocksdb_compaction_score gauge mongodb_mongod_rocksdb_compaction_score{level="L0"} 0 mongodb_mongod_rocksdb_compaction_score{level="L5"} 0.9 mongodb_mongod_rocksdb_compaction_score{level="L6"} 0 mongodb_mongod_rocksdb_compaction_score{level="total"} 0 # HELP mongodb_mongod_rocksdb_compaction_seconds_total The time spent doing compactions between levels N and N+1 in RocksDB # TYPE mongodb_mongod_rocksdb_compaction_seconds_total counter mongodb_mongod_rocksdb_compaction_seconds_total{level="L0"} 20 mongodb_mongod_rocksdb_compaction_seconds_total{level="L5"} 25 mongodb_mongod_rocksdb_compaction_seconds_total{level="L6"} 248 mongodb_mongod_rocksdb_compaction_seconds_total{level="total"} 293 # HELP mongodb_mongod_rocksdb_compaction_write_amplification The write amplification factor from compaction between levels N and N+1 in RocksDB # TYPE mongodb_mongod_rocksdb_compaction_write_amplification gauge mongodb_mongod_rocksdb_compaction_write_amplification{level="L5"} 1 mongodb_mongod_rocksdb_compaction_write_amplification{level="L6"} 1.7 mongodb_mongod_rocksdb_compaction_write_amplification{level="total"} 3.8 # HELP mongodb_mongod_rocksdb_compactions_total The total number of compactions between levels N and N+1 in RocksDB # TYPE mongodb_mongod_rocksdb_compactions_total counter mongodb_mongod_rocksdb_compactions_total{level="L0"} 40 mongodb_mongod_rocksdb_compactions_total{level="L5"} 7 mongodb_mongod_rocksdb_compactions_total{level="L6"} 17 mongodb_mongod_rocksdb_compactions_total{level="total"} 64 # HELP mongodb_mongod_rocksdb_estimate_table_readers_memory_bytes The estimate RocksDB table-reader memory bytes # TYPE mongodb_mongod_rocksdb_estimate_table_readers_memory_bytes gauge mongodb_mongod_rocksdb_estimate_table_readers_memory_bytes 2.10944e+06 # HELP mongodb_mongod_rocksdb_files The number of files in a RocksDB level # TYPE mongodb_mongod_rocksdb_files gauge mongodb_mongod_rocksdb_files{level="L0"} 0 mongodb_mongod_rocksdb_files{level="L5"} 2 mongodb_mongod_rocksdb_files{level="L6"} 23 mongodb_mongod_rocksdb_files{level="total"} 25 # HELP mongodb_mongod_rocksdb_immutable_memtables The total number of immutable MemTables in RocksDB # TYPE mongodb_mongod_rocksdb_immutable_memtables gauge mongodb_mongod_rocksdb_immutable_memtables 0 # HELP mongodb_mongod_rocksdb_iterations_total The total number of iterations performed by RocksDB # TYPE mongodb_mongod_rocksdb_iterations_total counter mongodb_mongod_rocksdb_iterations_total{type="backward"} 1955 mongodb_mongod_rocksdb_iterations_total{type="forward"} 206563 # HELP mongodb_mongod_rocksdb_keys_total The total number of RocksDB key operations # TYPE mongodb_mongod_rocksdb_keys_total counter mongodb_mongod_rocksdb_keys_total{type="read"} 209546 mongodb_mongod_rocksdb_keys_total{type="written"} 281332 # HELP mongodb_mongod_rocksdb_live_versions The current number of live versions in RocksDB # TYPE mongodb_mongod_rocksdb_live_versions gauge mongodb_mongod_rocksdb_live_versions 1 # HELP mongodb_mongod_rocksdb_memtable_bytes The current number of MemTable bytes in RocksDB # TYPE mongodb_mongod_rocksdb_memtable_bytes gauge mongodb_mongod_rocksdb_memtable_bytes{type="active"} 2.5165824e+07 mongodb_mongod_rocksdb_memtable_bytes{type="total"} 2.5165824e+07 # HELP mongodb_mongod_rocksdb_memtable_entries The current number of Memtable entries in RocksDB # TYPE mongodb_mongod_rocksdb_memtable_entries gauge mongodb_mongod_rocksdb_memtable_entries{type="active"} 4553 mongodb_mongod_rocksdb_memtable_entries{type="immutable"} 0 # HELP mongodb_mongod_rocksdb_oldest_snapshot_timestamp The timestamp of the oldest snapshot in RocksDB # TYPE mongodb_mongod_rocksdb_oldest_snapshot_timestamp gauge mongodb_mongod_rocksdb_oldest_snapshot_timestamp 0 # HELP mongodb_mongod_rocksdb_pending_compactions The total number of compactions pending in RocksDB # TYPE mongodb_mongod_rocksdb_pending_compactions gauge mongodb_mongod_rocksdb_pending_compactions 0 # HELP mongodb_mongod_rocksdb_pending_memtable_flushes The total number of MemTable flushes pending in RocksDB # TYPE mongodb_mongod_rocksdb_pending_memtable_flushes gauge mongodb_mongod_rocksdb_pending_memtable_flushes 0 # HELP mongodb_mongod_rocksdb_read_latency_microseconds The read latency in RocksDB in microseconds by level # TYPE mongodb_mongod_rocksdb_read_latency_microseconds gauge mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="P50"} 9.33 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="P75"} 17.03 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="P99"} 1972.31 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="P99.9"} 9061.44 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="P99.99"} 18098.3 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="avg"} 87.3861 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="max"} 26434 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="median"} 9.3328 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="min"} 0 mongodb_mongod_rocksdb_read_latency_microseconds{level="L0",type="stddev"} 607.16 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="P50"} 10.85 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="P75"} 28.46 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="P99"} 4208.33 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="P99.9"} 13079.55 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="P99.99"} 23156.25 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="avg"} 216.3736 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="max"} 34585 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="median"} 10.8461 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="min"} 0 mongodb_mongod_rocksdb_read_latency_microseconds{level="L5",type="stddev"} 978.48 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="P50"} 9.42 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="P75"} 30.69 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="P99"} 6037.87 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="P99.9"} 15482.63 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="P99.99"} 30125.5 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="avg"} 294.9574 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="max"} 61051 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="median"} 9.4245 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="min"} 0 mongodb_mongod_rocksdb_read_latency_microseconds{level="L6",type="stddev"} 1264.12 # HELP mongodb_mongod_rocksdb_reads_total The total number of read operations in RocksDB # TYPE mongodb_mongod_rocksdb_reads_total counter mongodb_mongod_rocksdb_reads_total{level="L0"} 59017 mongodb_mongod_rocksdb_reads_total{level="L5"} 42125 mongodb_mongod_rocksdb_reads_total{level="L6"} 118745 # HELP mongodb_mongod_rocksdb_seeks_total The total number of seeks performed by RocksDB # TYPE mongodb_mongod_rocksdb_seeks_total counter mongodb_mongod_rocksdb_seeks_total 156184 # HELP mongodb_mongod_rocksdb_size_bytes The total byte size of levels in RocksDB # TYPE mongodb_mongod_rocksdb_size_bytes gauge mongodb_mongod_rocksdb_size_bytes{level="L0"} 0 mongodb_mongod_rocksdb_size_bytes{level="L5"} 1.2969836544e+08 mongodb_mongod_rocksdb_size_bytes{level="L6"} 1.46175688704e+09 mongodb_mongod_rocksdb_size_bytes{level="total"} 1.59145525248e+09 # HELP mongodb_mongod_rocksdb_snapshots The current number of snapshots in RocksDB # TYPE mongodb_mongod_rocksdb_snapshots gauge mongodb_mongod_rocksdb_snapshots 0 # HELP mongodb_mongod_rocksdb_stall_percent The percentage of time RocksDB has been stalled # TYPE mongodb_mongod_rocksdb_stall_percent gauge mongodb_mongod_rocksdb_stall_percent 0 # HELP mongodb_mongod_rocksdb_stalled_seconds_total The total number of seconds RocksDB has spent stalled # TYPE mongodb_mongod_rocksdb_stalled_seconds_total counter mongodb_mongod_rocksdb_stalled_seconds_total 0 # HELP mongodb_mongod_rocksdb_stalls_total The total number of stalls in RocksDB # TYPE mongodb_mongod_rocksdb_stalls_total counter mongodb_mongod_rocksdb_stalls_total{type="level0_numfiles"} 0 mongodb_mongod_rocksdb_stalls_total{type="level0_numfiles_with_compaction"} 0 mongodb_mongod_rocksdb_stalls_total{type="level0_slowdown"} 0 mongodb_mongod_rocksdb_stalls_total{type="level0_slowdown_with_compaction"} 0 mongodb_mongod_rocksdb_stalls_total{type="memtable_compaction"} 0 mongodb_mongod_rocksdb_stalls_total{type="memtable_slowdown"} 0 # HELP mongodb_mongod_rocksdb_total_live_recovery_units The total number of live recovery units in RocksDB # TYPE mongodb_mongod_rocksdb_total_live_recovery_units gauge mongodb_mongod_rocksdb_total_live_recovery_units 5 # HELP mongodb_mongod_rocksdb_transaction_engine_keys The current number of transaction engine keys in RocksDB # TYPE mongodb_mongod_rocksdb_transaction_engine_keys gauge mongodb_mongod_rocksdb_transaction_engine_keys 0 # HELP mongodb_mongod_rocksdb_transaction_engine_snapshots The current number of transaction engine snapshots in RocksDB # TYPE mongodb_mongod_rocksdb_transaction_engine_snapshots gauge mongodb_mongod_rocksdb_transaction_engine_snapshots 0 # HELP mongodb_mongod_rocksdb_write_ahead_log_bytes_per_second The number of bytes written per second by the Write-Ahead-Log in RocksDB # TYPE mongodb_mongod_rocksdb_write_ahead_log_bytes_per_second gauge mongodb_mongod_rocksdb_write_ahead_log_bytes_per_second 157286.4 # HELP mongodb_mongod_rocksdb_write_ahead_log_writes_per_sync The number of writes per Write-Ahead-Log sync in RocksDB # TYPE mongodb_mongod_rocksdb_write_ahead_log_writes_per_sync gauge mongodb_mongod_rocksdb_write_ahead_log_writes_per_sync 70538 # HELP mongodb_mongod_rocksdb_writes_per_batch The number of writes per batch in RocksDB # TYPE mongodb_mongod_rocksdb_writes_per_batch gauge mongodb_mongod_rocksdb_writes_per_batch 2.54476812288e+09 # HELP mongodb_mongod_rocksdb_writes_per_second The number of writes per second in RocksDB # TYPE mongodb_mongod_rocksdb_writes_per_second gauge mongodb_mongod_rocksdb_writes_per_second 157286.4 # HELP mongodb_mongod_storage_engine The storage engine used by the MongoDB instance # TYPE mongodb_mongod_storage_engine counter mongodb_mongod_storage_engine{engine="rocksdb"} 1 |
Grafana
PMM uses Grafana to visualize metrics stored in Prometheus. Grafana uses a concept of “dashboards” to store the definitions of what it should visualize. PMM’s dashboards are hosted under the GitHub project: percona/grafana-dashboards.
Grafana can support multiple “data sources” for metrics. As Percona Monitoring and Management uses Prometheus for metric storage, this is the “data source” used in Grafana.
Adding Custom Graphs to Grafana
In this section I will create an example graph to help indicate the “efficiency” of queries on a Mongod instance over the last 5 minutes. This is a good example to use because we plan to add this exact metric in an upcoming version of PMM.
This graph will rely on two metrics that are already provided to PMM via percona/mongodb_exporter since at least version 1.0.0 (“$host” = the hostname of a given node – explained later):
The graph will compute the change in these two metrics over five minutes and create a percentage/ratio of scanned vs. returned documents. A host with ten scanned documents and one document returned would have 10% efficiency and a host that scanned 100 documents to return 100 documents would have 100% efficiency (a 1:1 ratio).
Often you will encounter Prometheus metrics that are “total” metric counters that increment from the time the server is (re)started. Both of the metrics our new graph requires are incremented counters and thus need to be “scaled” or “trimmed” to only show the last five minutes of metrics (in this example), not the total since the server was (re)started.
Prometheus offers a very useful query function for incremented counters called “increase()”: https://prometheus.io/docs/querying/functions/#increase(). The Prometheus increase() function allows queries to return the amount a metric counter has increased over a given time period, making this trivial to do! It is also unaffected by counter “resets” due to server restarts as increase() only returns increases in counters.
The increase() syntax requires a time range to be specified before the closing round-bracket. In our case we will as increase() to consider the last five minutes, which is expressed with “[5m]” at the end of the increase() function, seen in the following example.
The full Prometheus query I will use to create query efficiency graph is:
|
1 2 3 4 5 6 7 |
sum( increase(mongodb_mongod_metrics_query_executor_total{instance="$host", state="scanned_objects"}[5m]) ) / sum( increase(mongodb_mongod_metrics_document_total{instance="$host", state="returned"}[5m]) ) |
Note: sum() is required around the increase() functions when dividing two numbers in Prometheus queries.
Now, let’s make this a new graph! To do this you can create a new dashboard in PMM’s Grafana or add to an existing dashboard. In this example I’ll create a new dashboard with a single graph.
To add a new dashboard, press the Dashboard selector in PMM’s Grafana and select “Create New”:
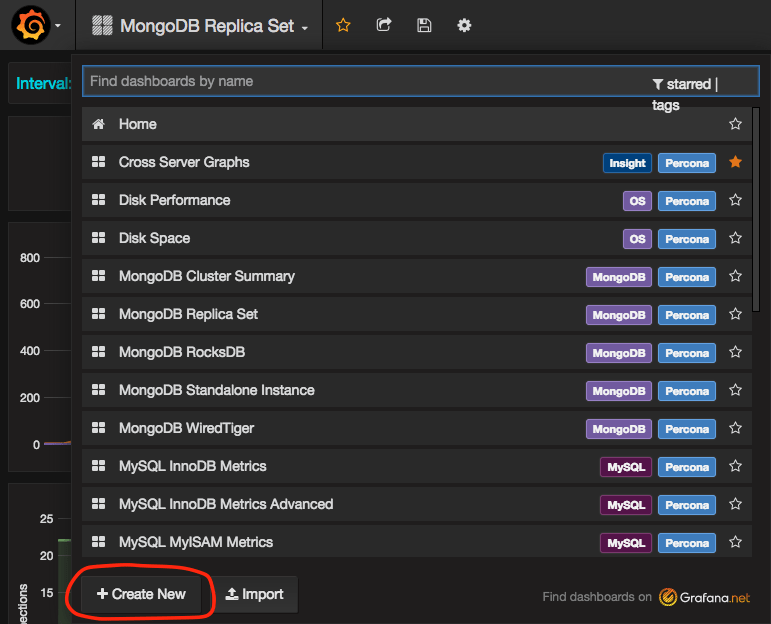
This will create a new dashboard named “New Dashboard”.
Most of PMM’s graphing uses a variable named “$host” in place of a hostname/IP. You’ll notice “$host” was used in the “query efficiency” Prometheus query earlier. The variable is set using a Grafana feature called Templating.
Let’s add a “$host” variable to our new dashboard so we can change what host we graph without modifying our queries. First, press the gear icon at the top of the dashboard and select “Templating”:
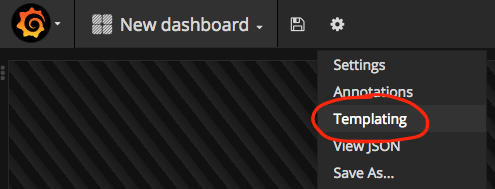
Then press “New” to create a new Templating variable.
Set “Name” to be host, set “Data Source” to Prometheus and set “Query” to label_values(instance). Leave all other settings default:
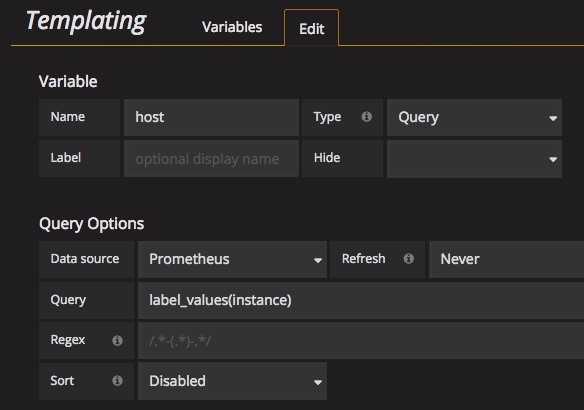
Press “Add” to add the template variable, then save and reload the dashboard.
This will add a drop-down of unique hosts in Prometheus like this:
On the first dashboard row let’s add a new graph by opening the row menu on the far left of the first row and then select “Add Panel”:
Select “Graph” as the type. Click the title of the blank graph to open a menu, press “Edit”:
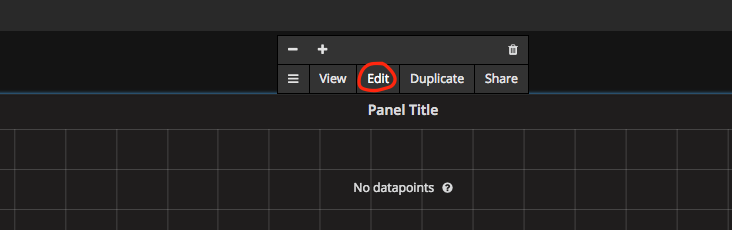
This opens Grafana’s graph editor with an empty graph and some input boxes seen below.
Next, let’s add our “query efficiency” Prometheus query (earlier in this article) to the “Query” input field and add a legend name to “Legend format”:
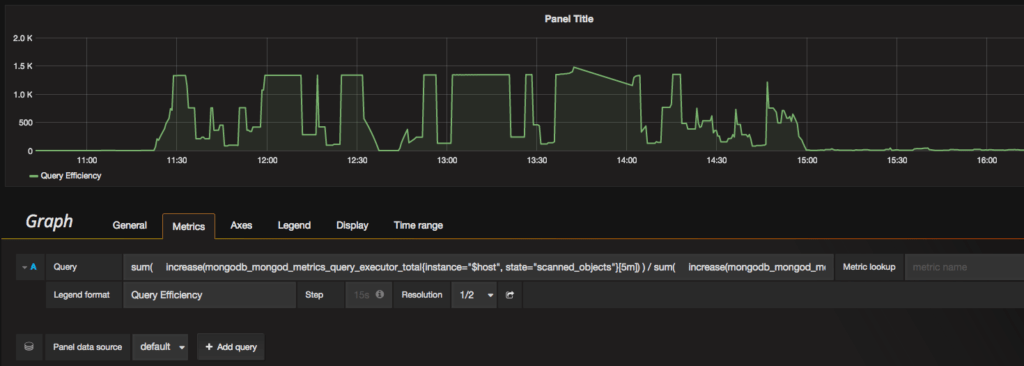
Now we have some graph data, but the Y-axis and title don’t explain very much about the metric. What does “1.0K” on the Y-Axis mean?
As our metric is a ratio, let’s display the Y-axis as a percentage by switching to the “Axes” tab, then selecting “percent (0.0-1.0)” as the “Unit” selection for the “Left Y” axis, like so:
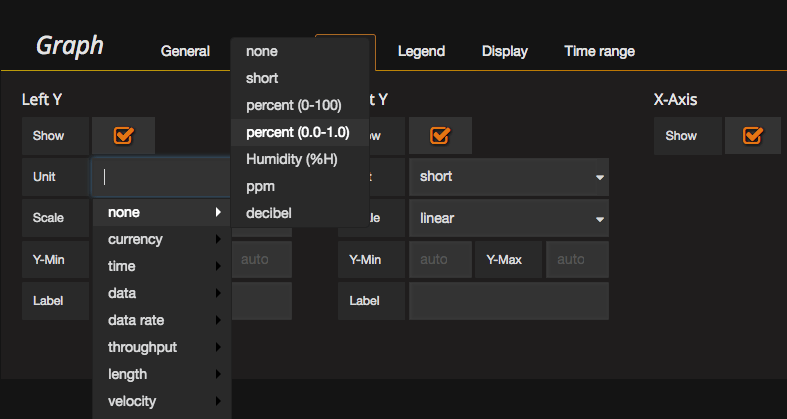
Next let’s set a graph title. To do this, go to the “General” tab of the graph editor and set the “Title” field:
And now we have a “Query Efficiency” graph with an accurate Y-axis and Title(!):
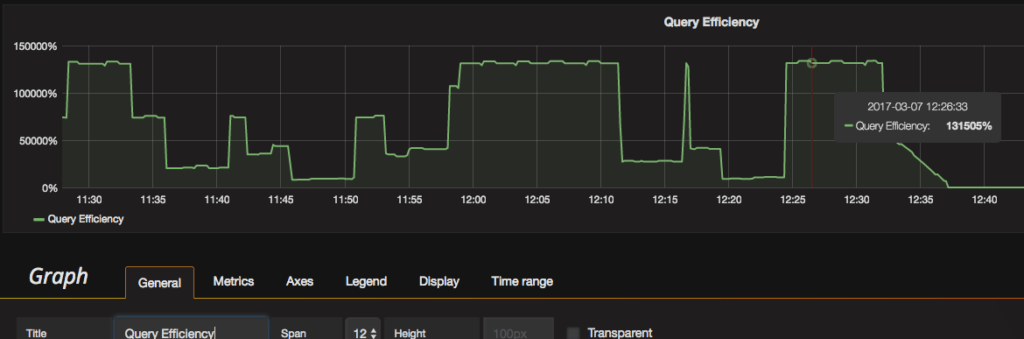
“Back to Dashboard” on the top-right will take you back to the dashboard view. Always remember to save your dashboards after making changes!
Adding Custom Metrics to percona/mongodb_exporter
For those familiar with the Go programming language, adding custom metrics to percona/mongodb_exporter is fairly straightforward. The percona/mongodb_exporter uses the Prometheus Go client to export metrics gathered from queries to MongoDB.
Adding a completely new metric to the exporter is unfortunately too open-ended to explain in a blog. Instead, I will cover how an existing metric is exported by percona/mongodb_exporter. The process for a new metric will be similar.
To follow our previous example, here is an simplified example of how the metric: “mongodb_mongod_metrics_query_executor_total” is exported via percona/mongodb_exporter. This source of this metric is “db.serverStatus().metrics.queryExecutor” from MongoDB shell perspective.
First a new Prometheus metric is defined as a go ‘var’:
|
1 2 3 4 5 6 7 |
var ( metricsQueryExecutorTotal = prometheus.NewCounterVec(prometheus.CounterOpts{ Namespace: Namespace, Name: "metrics_query_executor_total", Help: "queryExecutor is a document that reports data from the query execution system", }, []string{"state"}) ) |
|
1 2 3 4 5 6 7 8 9 10 11 |
// QueryExecutorStats are the stats associated with a query execution. type QueryExecutorStats struct { Scanned float64 `bson:"scanned"` ScannedObjects float64 `bson:"scannedObjects"` } // Export exports the query executor stats. func (queryExecutorStats *QueryExecutorStats) Export(ch chan<- prometheus.Metric) { metricsQueryExecutorTotal.WithLabelValues("scanned").Set(queryExecutorStats.Scanned) metricsQueryExecutorTotal.WithLabelValues("scanned_objects").Set(queryExecutorStats.ScannedObjects) } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// MetricsStats are all stats associated with metrics of the system type MetricsStats struct { Document *DocumentStats `bson:"document"` GetLastError *GetLastErrorStats `bson:"getLastError"` Operation *OperationStats `bson:"operation"` QueryExecutor *QueryExecutorStats `bson:"queryExecutor"` Record *RecordStats `bson:"record"` Repl *ReplStats `bson:"repl"` Storage *StorageStats `bson:"storage"` Cursor *CursorStats `bson:"cursor"` } // Export exports the metrics stats. func (metricsStats *MetricsStats) Export(ch chan<- prometheus.Metric) { if metricsStats.Document != nil { metricsStats.Document.Export(ch) } if metricsStats.GetLastError != nil { metricsStats.GetLastError.Export(ch) } if metricsStats.Operation != nil { metricsStats.Operation.Export(ch) } if metricsStats.QueryExecutor != nil { metricsStats.QueryExecutor.Export(ch) } ... |
For those unfamiliar with Go and/or unable to contribute new metrics to the project, we suggest you open a JIRA ticket for any feature requests for new metrics here: https://jira.percona.com/projects/PMM.
Conclusion
With the flexibility of the monitoring components of Percona Monitoring and Management, the sky is the limit on what can be done with database monitoring! Hopefully this blog gives you a taste of what is possible if you need to add a new graph, a new metric or both to Percona Monitoring and Management. Also, it is worth repeating that a large number of metrics gathered in Percona Monitoring and Management are not graphed. Perhaps what you’re looking for is already collected. See “http://
We are always open to improving our dashboards, and we would love to hear about any custom graphs you create and how they help solve problems!
Resources
RELATED POSTS




