
 This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In this blog post, I hope to cover some areas to watch with Percona Monitoring and Management (PMM) when running MMAPv1. The graph examples from this article are from the MMAPv1 dashboard that will be released for the first time in PMM 1.1.2.
This blog post is another in the series on the Percona Server for MongoDB 3.4 bundle release. In this blog post, I hope to cover some areas to watch with Percona Monitoring and Management (PMM) when running MMAPv1. The graph examples from this article are from the MMAPv1 dashboard that will be released for the first time in PMM 1.1.2.
Since the very beginning of MongoDB, the MMAPv1 storage engine has existed. MongoDB 3.0 added a pluggable storage engine API. You could only use MMAPv1 with MongoDB before that. While MMAPv1 often offers good read performance, it has become famous for its poor write performance and fragmentation at scale. This means there are many areas to watch for regarding performance and monitoring.
Percona Monitoring and Management (PMM)
Percona Monitoring and Management (PMM) is an open-source platform for managing and monitoring MySQL and MongoDB. It was developed by Percona on top of open-source technology. Behind the scenes, the graphing features this article covers use Prometheus (a popular time-series data store), Grafana (a popular visualization tool), mongodb_exporter (our MongoDB database metric exporter) plus other technologies to provide database and operating system metric graphs for your database instances.
(Beware of) MMAPv1
mmap() is a system-level call that causes the operating system kernel to map on-disk files to memory while it is being read and written by a program.
As mmap() is a core feature of the Unix/Linux operating system kernel (and not the MongoDB code base), I’ve always felt that calling MMAPv1 a “storage engine” is quite misleading, although it does allow for a simpler explanation. The distinction and drawbacks of the storage logic being in the operating system kernel vs. the actual database code (like most database storage engines) becomes very important when monitoring MMAPv1.
As Unix/Linux are general-purpose operating systems that can have many processes, users and uses cases, they offer limited OS-level metrics in terms of activity, latency and performance of mmap(). Those metrics are for the entire operating system, not just for the MongoDB processes.
mmap() uses memory from available OS-level buffers/caches for mapping the MMAPv1 data to RAM — memory that can be “stolen” away by any other operating system process that asks for it. As many deployments “micro-shard” MMAPv1 to reduce write locks, this statement can become exponentially more important. If 3 x MongoDB instances run on a single host, the kernel fights to cache and evict memory pages created by 3 x different instances with no priority or queuing, essentially at random, while creating contention. This causes inefficiencies and less-meaningful monitoring values.
When monitoring MMAPv1, you should consider MongoDB AND the operating system as one “component” more than most engines. Due to this, it is critical that a database host runs a single MongoDB instance with no other processes except database monitoring tools such as PMM’s client. This allows MongoDB to be the only user of the operating system filesystem cache that MMAPv1 relies on. This also makes OS-level memory metrics more accurate because MongoDB is the only user of memory. If you need to “micro-shard” instances, I recommend using containers (Docker or plain cgroups) or virtualization to separate your memory for each MongoDB instance, with just one MongoDB instance per container.
Locking
MMAPv1’s has locks for both reads and writes. In the early days the lock was global only. Locking became per-database in v2.2 and per-collection in v3.0.
Locking is the leading cause of the performance issues we see on MMAPv1 systems, particularly write locking. To measure how much locking an MMAPv1 instance is waiting on, first we look at the “MMAPv1 Lock Ratio”:
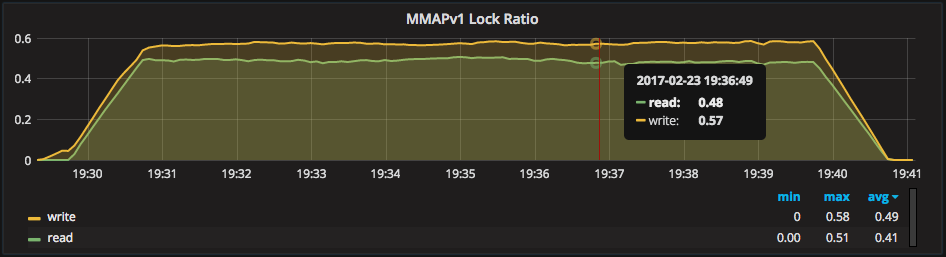
Another important metric to watch is “MongoDB Lock Wait Time”, breaking down a number of time operations spend waiting on locks:
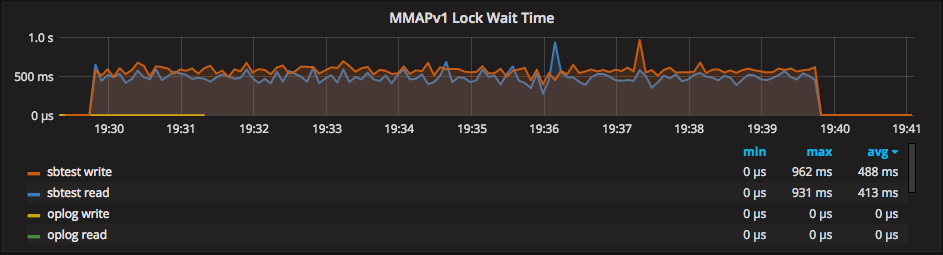
Three factors in combination influence locking:
Page Faults
Page faults happen when MMAPv1 data is not available in the cache and needs to be fetched from disk. On systems with data that is smaller than memory page faults usually only occur on reboot, or if the file system cache is dumped. On systems where data exceeds memory, this happens more frequently — MongoDB is asked for data not in memory.
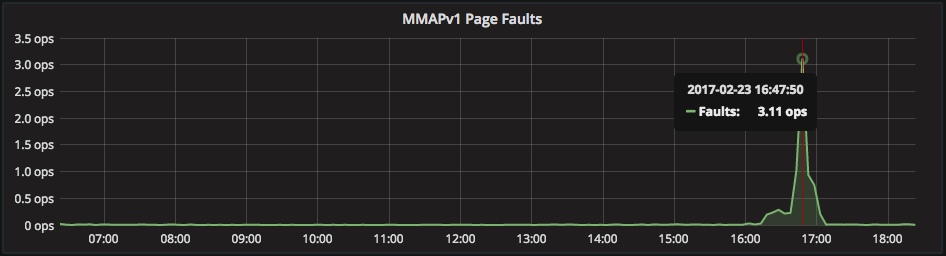
How often this happens depends on how your application accesses your data. If it accesses new or frequently-queried data, it is more likely to be in memory. If it accesses old or infrequent data, more page faults occur.
If page faults suddenly start occurring, check to see if your data set has grown beyond the size of memory. You may be able to reduce your data set by removing fragmentation (explained later).
Journaling
As MMAPv1 eventually flushes changes to disk in batches, journaling is essential for running MongoDB with any real data integrity guarantees. As well as being included in the lock statistic graphs mentioned above, there are some good metrics for journaling (which is a heavy consumer of disk writes).
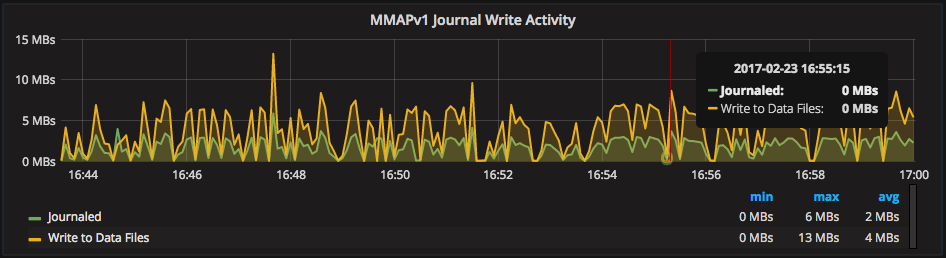
Here we have “MMAPv1 Journal Write Activity”, showing the data rates of journaling (max 19MB/sec):
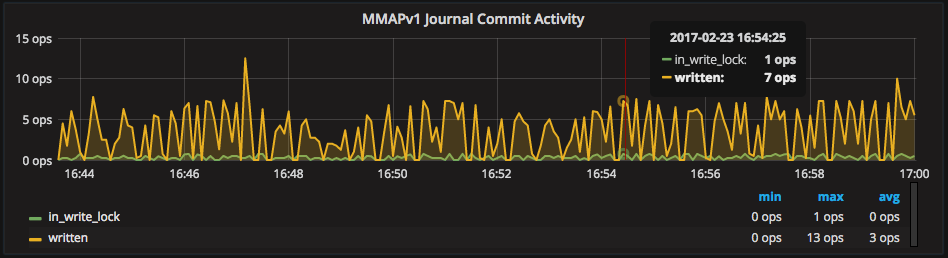
“MMAPv1 Journal Commit Activity” measures the commits to the journal ops/second:
A very useful metric for write query performance is “MMAPv1 Journaling Time” (there is another graph with 99th percentile times):
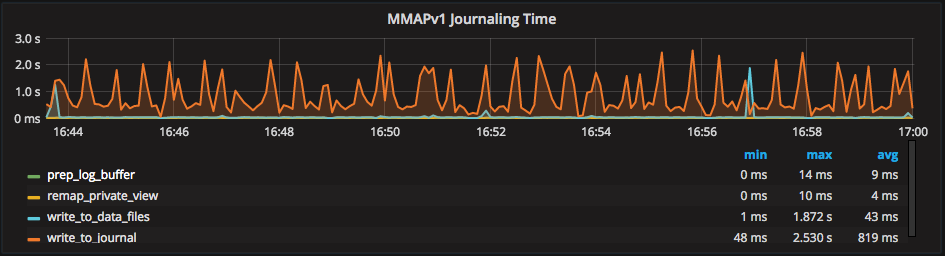
This is important to watch, as write operations need to wait for a journal commit. In the above example, “write_to_journal” and “write_to_data_files” are the main metrics I tend to look at. “write_to_journal” is the rate of changes being written to the journal, and “write_to_data_files” is the rate that changes are written to on-disk data.
If you see very high journal write times, you may need faster disks or in-sharding scenarios. Adding more shards spreads out the disk write load.
Background Flushing
“MMAPv1 Background Flushing Time” graphs the background operation that calls flushes to disk:
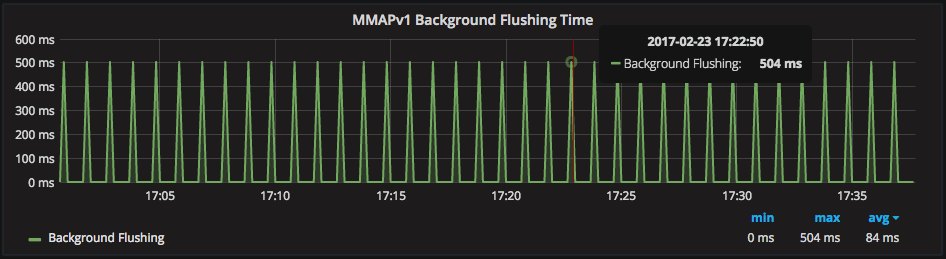
This process does not block the database, but does cause more disk activity.
Fragmentation
Due to the way MMAPv1 writes to disk, it creates a high rate of fragmentation (or holes) in its data files. Fragmentation slows down scan operations, wastes some filesystem cache memory and can use much more disk space than there is actual data. On many systems I’ve seen, the size of MMAPv1 data files on disk take over twice the true data size.
Currently, our Percona Monitoring and Management MMAPv1 support does not track this, but we plan to add it in the future.
To track it manually, look at the output of the “.stats()” command for a given collection (replace “sbtest1” with your collection name):
|
1 2 |
1 - ( db.sbtest1.stats().size / db.sbtest1.stats().storageSize ) 0.14085410557184752 |
Here we can see this collection is about 14% fragmented on disk. To fix fragmentation, the most common fix is dropping and recreating the collection using a backup. Many just remove a replication member, clear the data and let it do a new replication initial sync.
Operating System Memory
In PMM we have graphed the operating system cached memory as it acts as the primary cache for MMAPv1:
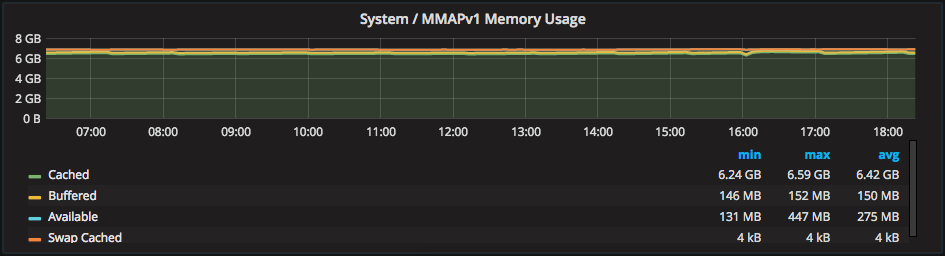
For the most part, “Cached” is the value showing the amount of data that is cached MMAPv1 data (assuming the host is only running MongoDB).
We also graph the dirty memory pages:
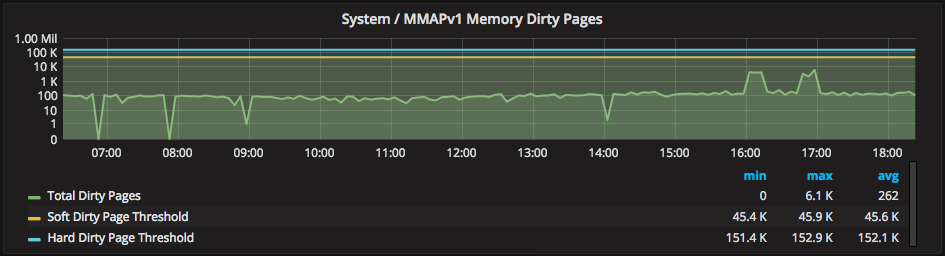
It is important that dirty pages do not exceed the hard dirty page limit (which causes pauses). It is also important that dirty pages don’t accumulate (which wastes cache memory). The “soft” dirty page limit is the limit that starts dirty page cleanup without pausing.
On this host, you could probably lower the soft limit to clean up memory faster, assuming the increase in disk activity is acceptable. This topic is covered in this post: https://www.percona.com/blog/2016/08/12/tuning-linux-for-mongodb/.
What’s Missing?
As mentioned earlier, fragmentation rates are missing for MMAPv1 (this would be a useful addition). Due to the limited nature of the metrics offered for MMAPv1, PMM probably won’t provide the same level of graphs for MMAPv1 compared to what we provide for WiredTiger or RocksDB. There will likely be fewer additions to the graphing capabilities going forward.
If you are using a highly concurrent system, we highly recommend you upgrade to WiredTiger or RocksDB (both also covered in this monitoring series). These engines provide several solutions to MMAPv1 headaches: document-level locking, built-in compression, checkpointing that cause near-zero fragmentation on disk and much-improved visibility for monitoring. We just released Percona Server for MongoDB 3.4, and it provides many exciting features (including these engines).
Look out for more monitoring posts from this series!
Resources
RELATED POSTS




