
In this blog post, I am going to show how we can use mysqlshell to run ad-hoc data visualizations and use machine learning to predict new outcomes from the data.
Some time ago Oracle released MySQL Shell, a command line client to connect to MySQL using the X protocol. It allows us to use Python or JavaScript scripting capabilities. This unties us from the limitations of SQL, and the possibilities are infinite. It means that MySQL can not only read data from the tables, but also learn from it and predict new values from features never seen before.
Some disclaimers:
It is possible to start mysqlshell with JavaScript or Python interpreter. Since we are going to use Pandas, NumPy and Scikit, Python will be our choice. There is an incompatibility between mysqlshell and Python > 2.7.10 that gives an error when loading some external libraries, so make sure you use 2.7.10.
We’ll work the “employees” database that can be downloaded here. In order to make everything easier and avoid several lines of data parsing, I have created a new table that summarizes the data we are going to work with, generated using the following structure and query:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> show create table dataG *************************** 1. row *************************** Create Table: CREATE TABLE `data` ( `emp_no` int(11) NOT NULL, `age` int(11) DEFAULT NULL, `hired` int(11) DEFAULT NULL, `gender` int(11) DEFAULT NULL, `salary` int(11) DEFAULT NULL, `department` int(11) DEFAULT NULL, PRIMARY KEY (`emp_no`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
|
1 2 3 |
mysql> INSERT INTO data SELECT employees.emp_no, YEAR(now()) - YEAR(birth_date) as age, YEAR(now()) - YEAR(hire_date) as hired, IF(gender='M',0,1) as gender, max(salary) as salary, RIGHT(dept_no,1) as department from employees, salaries, dept_emp WHERE employees.emp_no = salaries.emp_no and employees.emp_no = dept_emp.emp_no and dept_emp.to_date="9999-01-01" GROUP BY emp_no, dept_emp.dept_no; |
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from data limit 5; +--------+------+-------+--------+--------+------------+ | emp_no | age | hired | gender | salary | department | +--------+------+-------+--------+--------+------------+ | 10001 | 64 | 31 | 0 | 88958 | 5 | | 10002 | 53 | 32 | 1 | 72527 | 7 | | 10003 | 58 | 31 | 0 | 43699 | 4 | | 10004 | 63 | 31 | 0 | 74057 | 4 | | 10005 | 62 | 28 | 0 | 94692 | 3 | +--------+------+-------+--------+--------+------------+ |
The data is:
It only includes people currently working at the company.
Now that the data is ready, let’s start with mysqlshell. Everything that follows was done directly from the shell itself.
|
1 |
mysqlsh -uroot -p -h127.0.0.1 --py |
Once the login is validated, we will see the following prompt:
|
1 |
mysql-py> |
That means we are using the shell in Python mode. We can start loading our libraries:
|
1 2 3 4 5 |
mysql-py> import pandas as pd mysql-py> import numpy as np mysql-py> import seaborn mysql-py> import matplotlib.pyplot as plt mysql-py> from sklearn import tree |
Now, we read each column from the table and store it in its own variable:
|
1 2 3 4 5 6 7 8 9 10 |
mysql-py> use employees mysql-py> def column_to_list(column_name): temp_var = db.data.select([column_name]).execute().fetch_all() return [val for sublist in temp_var for val in sublist] mysql-py> gender = column_to_list("gender") mysql-py> salary = column_to_list("salary") mysql-py> age = column_to_list("age") mysql-py> hired = column_to_list("hired") mysql-py> department = column_to_list("department") |
And create a Pandas dataframe used to generate the visualizations:
|
1 2 3 4 5 6 |
df = pd.DataFrame({'Gender': gender, 'Salary': salary, 'Age': age, 'Hired': hired, 'Department': department }) |
Now, let’s investigate the data. Some basic statistics to get age, hired and salary overview:
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql-py> print df[["Salary","Age","Hired",]].describe(percentiles=(.75,.90,.99)) Salary Age Hired count 240124.000000 240124.000000 240124.000000 mean 72041.332178 58.918226 27.413782 std 17305.819632 3.750406 3.525041 min 40000.000000 52.000000 17.000000 50% 69827.000000 59.000000 28.000000 75% 82570.000000 62.000000 30.000000 90% 96125.000000 64.000000 32.000000 99% 119229.390000 65.000000 32.000000 max 158220.000000 65.000000 32.000000 |
Those statistics already give us good information. The employees range from 52 to 65, having an average of 59. They have been working at the company for 27 years on average with a salary of 72041.
But let’s forget about numbers. The human brain works much better and faster interpreting graphs than reading a table full of numbers. Let’s create some graphs and see if we can find any relationship.
Relation between Gender and Salary:
|
1 2 |
mysql-py> df.groupby(['Gender']).mean()['Salary'].plot(kind='bar') mysql-py> plt.show() |
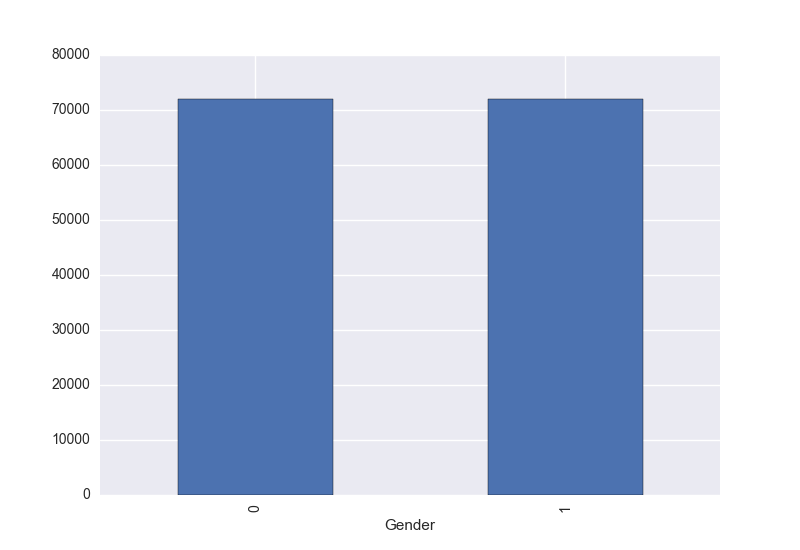
Relation between Age and Salary:
|
1 2 |
mysql-py> df.groupby(['Age']).mean()['Salary'].plot(kind='bar') mysql-py> plt.show() |
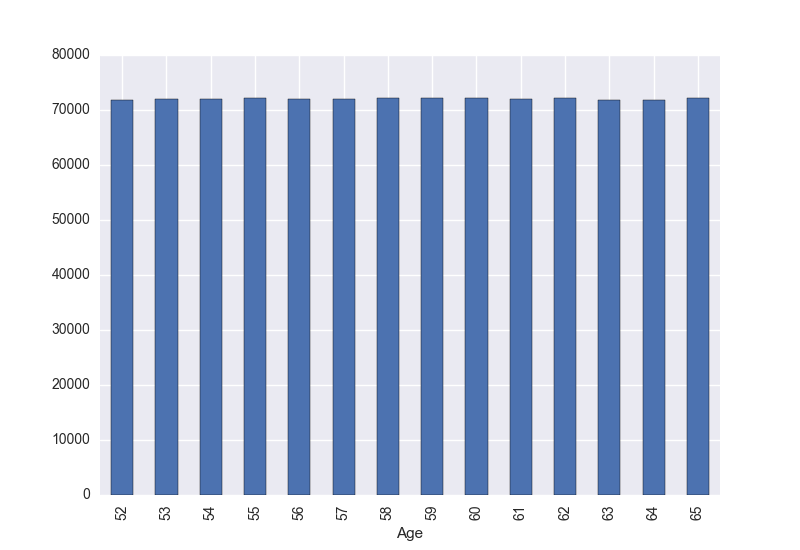
Relation between Department and Salary:
|
1 2 |
mysql-py> df.groupby(['Department']).mean()['Salary'].plot(kind='bar') mysql-py> plt.show() |
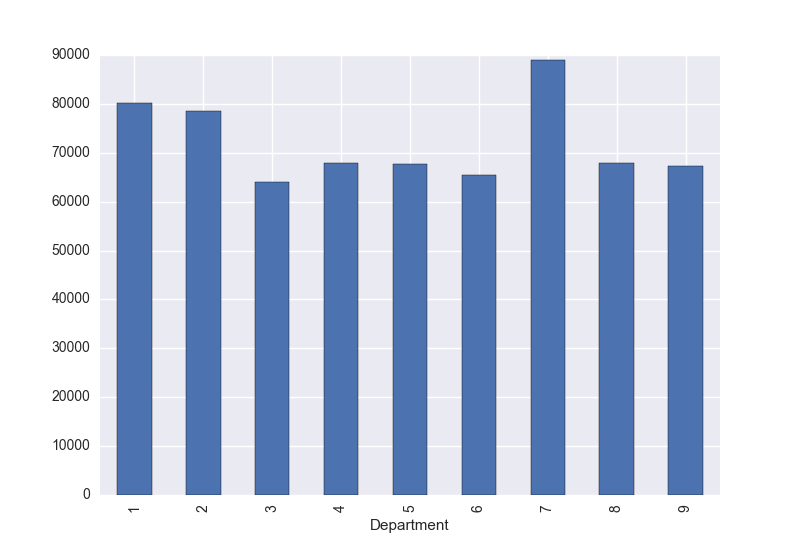
Relation between Hired and Salary:
|
1 2 |
mysql-py> df.groupby(['Hired']).mean()['Salary'].plot(kind='bar') mysql-py> plt.show() |
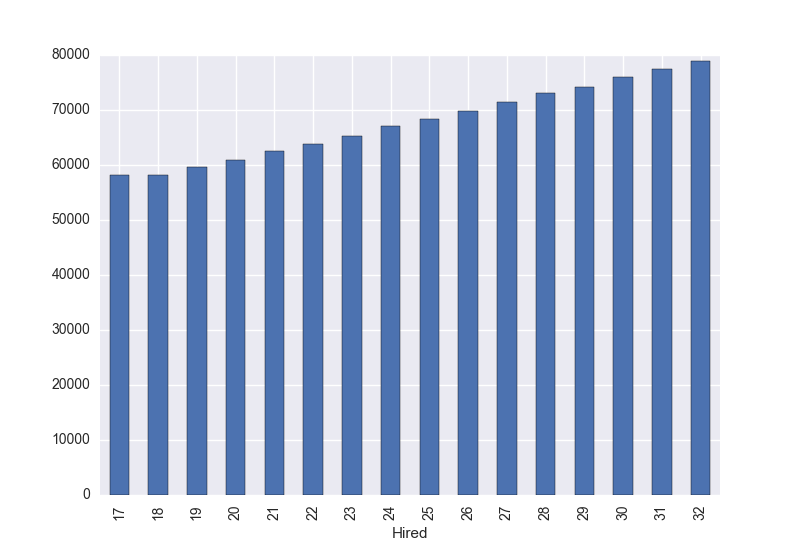
Now everything is more clear. There is no real relationship between gender and salary (yay!) or between age and salary. Seems that the average salary is related to the years that an employee has been working at the company, It also shows some differences depending on the department he/she belongs to.
Up to this point we have been using matplotlib, Pandas and NumPy to investigate and create graphs from the data stored in MySQL. Everything is from the shell itself. Amazing, eh? 🙂 Now let’s take a step forward. We are going to use machine learning so our MySQL client is not only able to read the data already stored, but also predict a salary.
Decision Tree Regression from SciKit Learn is the supervised learning algorithm we’ll use. Remember, everything is still from the shell!
Let’s separate the data into features and labels. From Wikipedia:
“Feature is an individual measurable property of a phenomenon being observed.”
Taking into account the graphs we saw before, “hired” and “department” are good features that could be used to predict the correct label (salary). In other words, we will train our Decision Tree by giving it “hired” and “department” data, along with their labels “salary”. The idea is that after the learning phase, we can ask it to predict a salary based on new “hired” and “department” data we provide. Let’s do it:
Separate the data in features and labels:
|
1 2 |
mysql-py> features = np.column_stack((hired, department)) mysql-py> labels = np.array(salary) |
Train our decision tree:
|
1 2 |
mysql-py> clf = tree.DecisionTreeRegressor() mysql-py> clf = clf.fit(features, labels) |
Now, MySQL, tell me:
What do you think the salary of a person that has been working 25 years at the company, currently in department number 2, should be?
|
1 2 |
mysql-py> clf.predict([[25, 2]]) array([ 75204.21140143]) |
It predicts that the employee should have a salary of 75204. A person working there for 25 years, but in department number 7, should have a greater salary (based on the averages we saw before). What does our Decision Tree say?
|
1 2 |
mysql-py> clf.predict([[25, 7]]) array([ 85293.80606296]) |
Now MySQL can both read data we already know, and it can also predict it! 🙂 mysqlshell is a very powerful tool that can be used to help us in our data analysis tasks. We can calculate statistics, visualize graphs, use machine learning, etc. There are many things you might want to do with your data without leaving the MySQL Shell.





Wonderful article Miguel ! Thank you for writing and sharing this.
Thanks a lot. Shall play it when time allows 🙂
thanks!
Hello,
How do you get the “employees” database “loaded” in mysql-py?
Wanted to read more about mysql-py and mysql-js, any tutorials and good reads?
Thank you
Excellent article. I have been trying to work with the examples, but it has been impossible for me to get MySQLsh and Python 2.7.10. Have tried on Windows 10, and OSX without any luck.
Numpy seems to be the problem… and pandas. Works fine on Python, but not Mysqlsh in Python mode.
It has been impossible to find anything about it for me with Google.