

This blog post looks at MongoDB and MySQL, and covers high-level MongoDB strengths, weaknesses, features, and uses from the perspective of an SQL user.
Delving into NoSQL coming from an exclusively SQL background can seem like a daunting task. I have worked with SQL in both small MySQL environments and large Oracle SQL environments.
MongoDB is an incredibly robust, scalable, and operator-friendly database solution. MongoDB is a good choice when your developers will also be responsible for the database environment. In small shops and startups, this might be the case. MongoDB stores information in BSON (binary JSON). BSON is the native JSON (JavaScript Object Notation) language used by MongoDB to retrieve information stored in BSON on the back end. JSON is easily relatable to other programming languages, and many developers will already have experience with it.
MongoDB is also a good option when you expect a great deal of your traffic to be writes. This is not to say that MySQL does not have good options when dealing with write-heavy environments, but MongoDB handles this with relative ease. Facebook designed the RocksDB storage engine for write-heavy environments, and performs well (with benchmark testing demonstrating this).
MongoDB is a good choice when you need a schemaless, or schema-flexible, data structure. MongoDB handles changes to your data organization with relative ease and grace. This is the selling point of NoSQL solutions. There have been many improvements in the MySQL world that make online schema changes possible, but the ease at which this is done in MongoDB has not yet been matched. The ability to create records without defining structure gives MongoDB added flexibility.
Another reason to choose MongoDB is its functionality with regards to replication setup, built-in sharding, and auto elections. Setting up a replicated environment in MongoDB is easy, and the auto-election process allows a secondary to take over in the event of a primary database failure. Built-in sharding allows for easy horizontal scaling, which can be more complicated to manage, setup and configure in a MySQL environment.
MongoDB is a great choice for some use cases. It is also not a great choice for others. MongoDB might not be the right choice when your data is highly relational and structured. MongoDB does not support transactions, but on a document level there is atomicity. There are configuration considerations to make for a replicated environment with regards to write concern, but these come at the cost of performance. Write concern verifies that replicas have written the information. By default, MongoDB sets the write concern to request acknowledgment from the primary only, not replicas. This can lead to consistency issues if there is a problem with the replicas.
Many concepts in the SQL world are relatable to the document structure of MongoDB. Let’s take a look at the high-level structure of a simple MongoDB environment to better understand how MongoDB is laid out.
The below chart relates MySQL to MongoDB (which is found in MongoDB’s documentation).
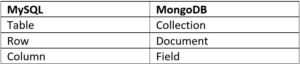
Another interesting note is the mongod process. This is a daemon that processes data requests, much the same as the mysqld process for MySQL. This is the process that listens for MongoDB requests, and manages access to the database. As with MySQL, there are a number of start-up options for the mongod process. One of the most important configuration options is
--config which specifies a config file to use for your mongod instance. Slightly different from MySQL, this file uses YAML formatting. Below is an example config file for MongoDB. Please note this is to demonstrate formatting. It isn’t optimized for any production database.
By definition, MongoDB is a document store database. This chart gives you some idea of how that relates to the structure of MySQL or any SQL flavor. Instead of building a table and adding data, you can immediately insert documents into a collection without having to define a structure. This is one of the advantages in flexibility that MongoDB offers over MySQL. It is important to note that just because MongoDB offers this flexibility does not mean that organizing a highly functional production MongoDB database is effortless. Similar to choosing any database, thought should be put into the structure and goal of the database to avoid pitfalls down the line.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
# mongod.conf, Percona Server for MongoDB # for documentation of all options, see: # http://docs.mongodb.org/manual/reference/configuration-options/ # Where and how to store data. storage: dbPath: /var/lib/mongodb journal: enabled: true engine: rocksdb # where to write logging data. systemLog: destination: file logAppend: true path: /var/log/mongodb/mongod.log processManagement: fork: true pidFilePath: /var/run/mongod.pid # network interfaces net: port: 27017 bindIp: 127.0.0.1 |
NOTE: YAML formatting does not handle tab. Use spaces to indent.
Interacting with the database via the shell also offers something slightly different from SQL. JSON queries MongoDB. Again, this should be familiar to web developers which is one of the appeals of using MongoDB. Below is an example of a query translated from SQL to MongoDB. We have a user table with just usernames and an associated ID.
In SQL:
|
1 |
select username from user where id = 2; |
In MongoDB:
|
1 |
db.user.find({_id:2},{"username":1}) |
In the JSON format, we specify the user collection to query from and then the ID associated with the document we are interested in. Finally, the field is specified from which we want the value. The result of this query would be the username of the user that has an ID of 2.
MongoDB is not a silver bullet to your MySQL woes. As both databases continue to evolve, their weaknesses and strengths slowly start to blend together. Do not let the flexibility of MongoDB’s structure fool you into thinking that you must not have a plan for your database environment. This will surely lead to headaches down the road. The flexibility should allow for dynamic, fast changes not thoughtless ones. I encourage any MySQL user to get their hands on a MongoDB instance for testing purposes. MongoDB is a popular option in the e-commerce and gaming world because of its flexibility in schema design and its ability to scale horizontally with large amounts of data.





When you state, “MongoDB might not be the right choice when your data is highly relational and structured,” could you please give an example with some sample data. In my 3 years of working with large data sets in a mixed environment of MySQL and MongoDB I’ve found exactly the opposite to be true. The more relational, complex and structured a set of data is, the better it can be defined in terms of JSON objects. A one-to-many relationship as we commonly find in everyday life, like inventory management or purchase orders, is ill-suited to the simplistic two-dimensional rows/columns structure of a “relational” database.
We worked ourselves into a convoluted mess developing an application over a period of 4 years that relied completely on highly normalized data with foreign key constraints. The amount of application infrastructure needed (read ORM) just to deal with this impedance mismatch is a major source of wasted development time from the standpoint of application developers. Application developers should be spending most of their time on business logic, not on the mechanics of getting data in and out of a container.
Web developers also need to focus on performance. Getting all the data they need for rendering a web page from a single query that represents complex, nested data that mimics real life data, e.g. a purchase order with several products being ordered, the history of actions on this purchase order (the requestor who created it, approvals, revisions, cancellations, etc.), shipping/tracking of each item, etc. Having to construct this specific set of data from scratch each and every time the page is loaded from multiple database tables (a very simplistic, incomplete set would look something like this: users, item_catalog, inventory_pricing, vendors, orders, order_activity_log, order_status, etc.) via complex SQL “joins” is neither intuitive for anyone without a background in “relational” databases, nor is it the most efficient way to develop a website from a backend developer’s perspective.
Extensive benchmarking of two branches of code, the only difference being MySQL (using extensive joins and GROUP BY functions) and MongoDB (using complex aggregate queries) for a specific web application show a near doubling of average speed to load up the data using MongoDB, both running on the same hardware, same machine load, and same page results. Time stamps before queries and after query results were captured with microsecond precision.
Hi John,
You have highlighted one of the best use-cases for MongoDB. I am happy that MongoDB has brought you operational efficiency as well as performance improvements when compared to how your application ran on MySQL.
The structured and relational comment you’re referring to was with regards to the data-set having no tolerance for data inconsistencies or duplication. In terms of relationships, I was referring to an application whose data has many many-to-many relationships – for example, a social networking site. https://www.percona.com/blog/2014/03/27/a-conversation-with-5-facebook-mysql-gurus/
Fernando brings up some great points with regards to optimization at scale. There are many options to tackle this and no database – MySQL, MongoDB, or otherwise – is immune to those challenges. At a large scale, choosing the right tool for the right job is important. This is why Facebook also utilizes many technologies, including NoSQL solutions, in portions of their application.
I would love to learn more about the improvements you saw when comparing MySQL and MongoDB for your specific application. Is it possible for you to share this? I think it’d make an interesting blog post!
John, what I get from your comment is that if you’re not familiar with SQL and the relational model (I like that you quote relational, by the way, SQL is a poor implementation of that model and not really set oriented, I don’t quote the word but typically refer to such databases as “relationally inspired”), then it will be difficult to use such a database for your data persistence needs, and something like MongoDB will be easier. I won’t dispute that, but I can tell you the reverse is also true: I find it very difficult to translate what to me are simple joins with group by and/or order by expressions into MongoDB queries, that is when they’re possible to translate properly.
Also, if I read “Getting all the data they need for rendering a web page from a single query that represents complex, nested data that mimics real life data” as an isolated statement, I would assume you’re referring to SQL, since you can get this complex, nested data with a single query if you know how to write it. Granted, for some queries and in some database products, optimization will be poor and you may end up doing part of the aggregate on the application’s side, or denormalizing some of your tables (or using something like FlexViews to support both the normalized and denormalized versions), but it is a choice that you need to make when scale pushes to it. For someone with an SQL database background, making that choice early on when there may not even be a need for it makes little sense.
In a way, I see SQL as analogous to higher level programming languages like Ruby or Python, while I see NoSQL solutions as more analogous to assembly. I prefer to use SQL and only mess with manual workarounds when the model breaks, among other things, because every now and then, vendors will ship an upgrade that improves the performance of some specific SQL constructs, giving you a performance boost ‘for free’, the same way that can happen when, say, the garbage collector on a specific language implementation is improved.
Fernando, I appreciate your comments and insight into the topic of what is relational and what is not. You have also touched on some other concepts that are worthy of discussion.
For the record, I come from a scientific background. I was working 8 hours a day writing nothing but code back in the early 80s at Chevron Geosciences (a former subsidary of Standard Oil of California) in a very small R&D group. My first work with SQL started back in 1998. The most challenging SQL queries I ever had to write were for a contracted project for Cisco, a tool with a myriad of filters for their global sales and business planning. We were using Perl CGI and Oracle per our contract with Cisco. On this project it was not unusual to have queries joining 20+ tables with GROUP BY functions, the results from which we would then massage into associative arrays going as deep as 15 levels. I worked 2 years on that project, from 2007 to 2009. So, I think after 18 years of using SQL on a daily basis, and with projects of this complexity, I have a good understanding of SQL and the relational model.
After starting with MongoDB in 2013 and using it daily over the past 3 years, I’ve learned how to get what is needed via the aggregate query pipeline. I’ll admit there is a steep learning curve before one can really use it effectively, but I’ve never run up against a wall where I felt MySQL/PostgreSQL/Oracle would have been a better choice.
I think people like us who come from a strong RDBMS SQL background have gotten too fixated on designing the perfect, hyper-normalized data schemas that most closely represent the data out in the real world. From a MongoDB approach I’ve learned that such an approach doesn’t work very well. I design my collection schemas to match the data I need to display for my reports or web page. Often this results in duplicate data, i.e. collections having some overlap with the same data in other collections. Most of my collections avoid the need to deal with joins because I nest the data I would normally need to join within the parent document, for instance on our support tool, the initial request with its attributes (submitted_by, date, url, request, etc.) is the top-level document and each response gets added to the “responses” field, an array of subdocuments. Things needed for rendering the page, like fullname of the requester and responders are denormalized. This approach is something I learned from this presentation by Randall Wilson of familysearch.org: https://youtu.be/ea-yeyKon00 (it starts to really take off at about 6 minutes into the video). I came across this while playing devil’s advocate trying to find “relational data not suited to the NoSQL approach”. I was thinking, “What could be more ‘relational’ than genealogical data?”
After 6 months of trying to find that elusive data that would be ill-suited to MongoDB, I realized it was time to ditch MySQL completely. That was in December 2014. It will, however, take a couple of years to completely migrate all the 314 MySQL tables and refactor the application code. On one of the more recent web applications I refactored, I carefully analyzed and benchmarked the differences. Despite using the custom ORM-based PHP framework I authored, the MySQL branch of that code required 72% more lines (to be even more objective, the size of the scripts on disk used 82% more code on the MySQL branch than was needed in the final version of the PHP code for doing it in MongoDB). This application is a survey tool, and of course, the stakeholders need copious reports on the results of the completed surveys.
Of course any of the SQL servers can use the piecemeal method of representing hierarchical data via multiple tables and foreign keys, but at what cost? The thing that really intrigued me so much about MongoDB at the very beginning was the functionality I had always hoped for in in the *SQL servers: storing an array of data in a single row of a single column. Finally someone had solved the problem of the one-to-many relationship without the horribly inefficient workaround of needing to create a separate table. And, they took it even one step further, an entire sub-table can be stored there as well!!!
For this new generation of MEAN stack developers, the joy of working with JSON natively and being able to query a DB via JS-syntax is just so intuitive and natural. They find SQL so “old school”. Just 2 days ago one of my direct reports thanked me again for the mentoring I provided regarding an aggregate query she had been working on. She comes from a Python background and was telling me how happy she was to be learning Mongo rather than SQL. Now I too have come to look at SQL as being very COBOL-like. So, in the end, MongoDB can do anything an SQL server can do (misuse it to store single 2-dimensional stiff, boring documents just like a table) except for joins (but actually now you can do that too:
https://docs.mongodb.com/v3.2/reference/operator/aggregation/lookup/ ).
In conclusion, working with MongoDB requires not only a totally different approach to designing queries that use GROUP BY functionality (I’m talking about higher-level design differences, not syntax differences), but also a completely different mindset when designing the collection schemas. The questions one asks oneself are totally different. Instead of asking “Which tables and what schema best describes the total set of data I will be handling in this application?” one needs to ask in the NoSQL world, “Which filters will I need (which fields will be used in my queries) and what data do I have to have in an already denormalized state to render this page or export this report?” The first (SQL) approach seeks to precisely capture the entire data set across all applications/pages/reports in a highly normalized way to avoid storing duplicate data with total disregard for the specific UI/UX challenges of multiple pages/views/reports, and piece it all together, in real time, ASAP, right after the user clicks on the link. I think the Randall Wilson @ familysearch.org presentation clearly shows where this approach can lead. The second (MongoDB) approach seeks to leverage only a small window of the multi-dimensional, denormalized data that pertains to the current UI/UX needs at hand, having it already sliced, diced, seasoned, and hot out the oven ready for the customer to consume, rather than worrying about how fast one can go shopping for the raw ingredients from 11 different stores, drive back to the kitchen, prepare it, and then bake it while the customer is waiting impatiently for it to be served.