
In this blog post, I am going to show you how can you use Orchestrator and ProxySQL together.
In my previous blog post, I showed how to use bash scripts and move virtual IPs with Orchestrator. As in that post, I assume you already have Orchestrator working. If not, you can find the installation steps here.
In the case of a failover, Orchestrator changes the MySQL topology and promotes a new master. But who lets the application know about this change? This is where ProxySQL helps us.
In our test, we use the following topology:
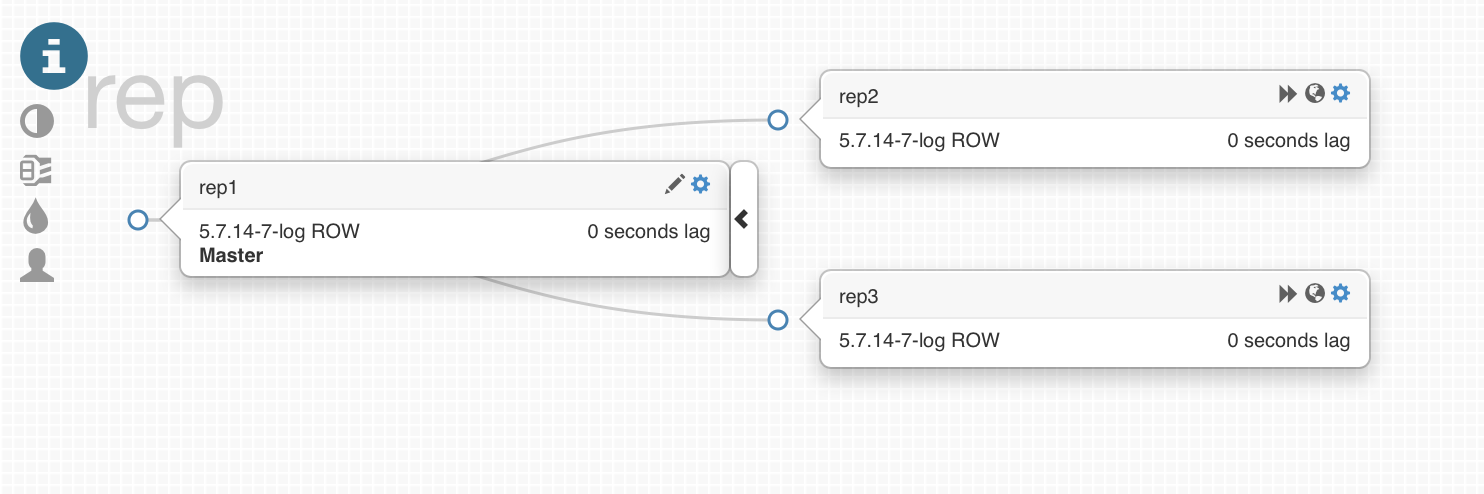
For this topology we need the next rules in “ProxySQL”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.56.107',601,3306,1000,10); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.56.106',601,3306,1000,10); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.56.105',601,3306,1000,0); INSERT INTO mysql_servers (hostname,hostgroup_id,port,weight,max_replication_lag) VALUES ('192.168.56.105',600,3306,1000,0); INSERT INTO mysql_replication_hostgroups VALUES (600,601,''); LOAD MYSQL SERVERS TO RUNTIME; SAVE MYSQL SERVERS TO DISK; insert into mysql_query_rules (username,destination_hostgroup,active) values('testuser_w',600,1); insert into mysql_query_rules (username,destination_hostgroup,active) values('testuser_r',601,1); insert into mysql_query_rules (username,destination_hostgroup,active,retries,match_digest) values('testuser_rw',601,1,3,'^SELECT'); LOAD MYSQL QUERY RULES TO RUNTIME;SAVE MYSQL QUERY RULES TO DISK; insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('testuser_w','Testpass1.',1,600,'test',1); insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('testuser_r','Testpass1.',1,601,'test',1); insert into mysql_users (username,password,active,default_hostgroup,default_schema,transaction_persistent) values ('testuser_rw','Testpass1.',1,600,'test',1); LOAD MYSQL USERS TO RUNTIME;SAVE MYSQL USERS TO DISK; |
See the connection pool:
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from stats_mysql_connection_pool where hostgroup between 600 and 601 order by hostgroup,srv_host desc; +-----------+----------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | hostgroup | srv_host | srv_port | status | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms | +-----------+----------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | 600 | 192.168.56.105 | 3306 | ONLINE | 4 | 0 | 4 | 0 | 2833 | 224351 | 0 | 3242 | | 601 | 192.168.56.107 | 3306 | ONLINE | 1 | 1 | 11 | 0 | 275443 | 11785750 | 766914785 | 431 | | 601 | 192.168.56.106 | 3306 | ONLINE | 1 | 1 | 10 | 0 | 262509 | 11182777 | 712120599 | 1343 | | 601 | 192.168.56.105 | 3306 | ONLINE | 1 | 1 | 2 | 0 | 40598 | 1733059 | 111830195 | 3242 | +-----------+----------------+----------+--------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ 4 rows in set (0.00 sec) |
It shows us “192.168.57.105” is in “hostgroup” 600, which means that server is the master.
ProxySQL does not know what the topology looks like, which is really important. ProxySQL is monitoring the “read_only” variables on the MySQL servers, and the server where read_only=off is going to get the writes. If the old master went down and we changed our topology, we have to change the read_only variables on the new master. Of course, applications like MHA or Orchestrator can do that for us.
We have two possibilities here: the master went down, or we want to promote a new master.
If the master goes down, Orchestrator is going to change the topology and set the read_only = OFF on the promoted master. ProxySQL is going to realize the master went down and send the write traffic to the server where read_only=OFF.
Let’s do a test. After we stopped MySQL on “192.168.56.105”, Orchestrator promoted “192.168.56.106” as the new master. ProxySQL is using it now as a master:
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from stats_mysql_connection_pool where hostgroup between 600 and 601 order by hostgroup,srv_host desc; +-----------+----------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | hostgroup | srv_host | srv_port | status | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms | +-----------+----------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | 600 | 192.168.56.106 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 790 | | 601 | 192.168.56.107 | 3306 | ONLINE | 0 | 0 | 13 | 0 | 277953 | 11894400 | 774312665 | 445 | | 601 | 192.168.56.106 | 3306 | ONLINE | 0 | 0 | 10 | 0 | 265056 | 11290802 | 718935768 | 790 | | 601 | 192.168.56.105 | 3306 | SHUNNED | 0 | 0 | 2 | 0 | 42961 | 1833016 | 117959313 | 355 | +-----------+----------------+----------+---------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ 4 rows in set (0.00 sec) |
This happens quickly and does not require any application, VIP or DNS modification.
When we perform a graceful-master-takeover with Orchestrator, it promotes a slave as a new master, removes the old master from the replicaset and sets read_only=ON.
From Orchestrator’s point of view, this is great. It promoted a slave as a new master, and old master is not part of the replicaset anymore. But as I mentioned earlier, ProxySQL does not know what the replicaset looks like.
It only knows we changed the read_only variables on some servers. It is going to send reads to the old master, but it does not have up-to-date data anymore. This is not good at all.
We have two options to avoid this.
If the master is not part of the read hostgroup, ProxySQL won’t send any traffic there after we promote a new master. But in this case, if we lose the slaves, ProxySQL cannot redirect the reads to the master. If we have a lot of slaves, and the replication stopped on the saves because of an error or mistake, the master probably won’t be able to handle all the read traffic. But if we only have a few slaves, it would be good if the master can also handle reads if there is an issue on the slaves.
In this great blog post from Marco Tusa, we can see that ProxySQL can use “Schedulers”. We can use the same idea here as well. I wrote a script based on Marco’s that can recognize if the old master is no longer a part of the replicaset.
The script checks the followings:
If the read_only=ON, it means the server is not the master at the moment. But if the repl_lag is NULL, it means the server is not replicating from anywhere, and it probably was a master. It has to be removed from the Hostgroup.
|
1 2 |
INSERT INTO scheduler (id,interval_ms,filename,arg1) values (10,2000,"/var/lib/proxysql/server_monitor.pl","-u=admin -p=admin -h=127.0.0.1 -G=601 -P=6032 --debug=0 --log=/var/lib/proxysql/server_check"); LOAD SCHEDULER TO RUNTIME;SAVE SCHEDULER TO DISK; |
The script has parameters like username, password or port. But we also have to define the read Hostgroup (-G).
Let’s see what happens with ProsySQL after we run the command orchestrator -c graceful-master-takeover -i rep1 -d rep2 :
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from stats_mysql_connection_pool where hostgroup between 600 and 601 order by hostgroup,srv_host desc; +-----------+----------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | hostgroup | srv_host | srv_port | status | ConnUsed | ConnFree | ConnOK | ConnERR | Queries | Bytes_data_sent | Bytes_data_recv | Latency_ms | +-----------+----------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ | 600 | 192.168.56.106 | 3306 | ONLINE | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 504 | | 601 | 192.168.56.107 | 3306 | ONLINE | 0 | 2 | 2 | 0 | 6784 | 238075 | 2175559 | 454 | | 601 | 192.168.56.106 | 3306 | ONLINE | 0 | 0 | 2 | 0 | 6761 | 237409 | 2147005 | 504 | | 601 | 192.168.56.105 | 3306 | OFFLINE_HARD | 0 | 0 | 2 | 0 | 6170 | 216001 | 0 | 435 | +-----------+----------------+----------+--------------+----------+----------+--------+---------+---------+-----------------+-----------------+------------+ 4 rows in set (0.00 sec) |
As we can see, the status changed to OFFLINE_HARD:
|
1 2 3 4 5 6 7 8 9 10 |
mysql> select * from mysql_servers; +--------------+----------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+ | hostgroup_id | hostname | port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment | +--------------+----------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+ | 601 | 192.168.56.107 | 3306 | ONLINE | 1000 | 0 | 1000 | 10 | 0 | 0 | | | 601 | 192.168.56.106 | 3306 | ONLINE | 1000 | 0 | 1000 | 10 | 0 | 0 | | | 9601 | 192.168.56.105 | 3306 | ONLINE | 1000 | 0 | 1000 | 0 | 0 | 0 | | | 600 | 192.168.56.106 | 3306 | ONLINE | 1000 | 0 | 1000 | 10 | 0 | 0 | | +--------------+----------------+------+--------+--------+-------------+-----------------+---------------------+---------+----------------+---------+ 4 rows in set (0.00 sec) |
This is because we changed the “hostgroup_id” to 9601. This is what we wanted so that the old master won’t get more traffic.
Because ProxySQL redirects the traffic based on the read_only variables, it is important to start the servers with read_only=ON (even on the master). In that case, we can avoid getting writes on many servers at the same time.
If we want to use graceful-master-takeover with Orchestrator, we have to use a scheduler that can remove the old master from the read Hostgroup.





The approach of choosing the master node based on reading the
read_onlyvalue will work in most cases: orchestrator, or another tool, would remove that property from the demoted master, set it on the new master and we’re happy.Or, you’d set
read_only=1in/etc/my.cnffor all your servers, such that a server that panics and restarts always starts up asread_only.However the approach does not work in the event of network partitioning of the master: to the world it would appear to be truly dead. But no one is able to
set read_only=0on that master. If it suddenly recovers from the network partitioning, during or after new master promotion, you end up with two different servers, both claiming to beread_only=0.To mitigate this you’d need to be able to shoot the failing node node (e.g. if it’s AWS you can halt/restart it) through the
orchestratorfailover scripts.Otherwise it would be best to find a more holistic approach to deciding which is the true master. A service discovery (consul/zk) would be a good candidate for that. Orchestrator would be able to tell
consul: oh hey, I just demoted _that_ master and promoted _that_ one; ProxySQL would periodically consult withconsulas for identify of master and route write queries based on that info.Also see this discussion: https://github.com/sysown/proxysql/issues/789 coincidentally taking place at the same day this post was published.
Hi Shlomi,
Thanks for your great comment. Yes, I have seen that discussion after the post was published and I am already testing/working on an Orchestrator+Consul+ProxySQL setup.
I am also thinking about that, if it is just a traditional replicaset normal master-slave (not galera), ProxySQL might should disable writes if there are two servers with
read_only=OFFin the same hostgroup. It might better not having writes for a short period than writing two nodes and might corrupting your data (of course this is depending on the application and the use cases). I am going to ask Rene what is his opinion about this.I think even a scheduler can do this but in that case writes could go to two nodes until the scheduler runs and changes the hostgroups etc..
Thanks,
Tibi
Hello
thank you for this aricle
I would like to know if the script server_monitor.pl should have existed in the directory / var / lib / proxysql /
thank you
Hello Tibor, I have been working closely for Orchestrator setup with proxysql along with the server_monitor.pl script for changing the hostgroup id when server comes back online. It works perfect for the first time. But when i try to change the hostgroup id from 9002 to 2, mysql_servers table doesn’t have things changed for hostgroup id column. Then i tried doing ” load mysql servers from config” and then i made it available somehow with the desired hostgroup. But then if another failover happens to new master and when servers comes back online then server_monitor.pl script is not working.
Ref :
mysql> select * from runtime_mysql_servers;
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
| 1 | 192.168.13.25 | 3306 | 0 | ONLINE | 1000 | 0 | 10000 | 300 | 0 | 0 | |
| 9002 | 192.168.13.58 | 3306 | 0 | ONLINE | 100 | 0 | 10000 | 0 | 0 | 0 | |
| 2 | 192.168.13.25 | 3306 | 0 | ONLINE | 1000 | 0 | 10000 | 300 | 0 | 0 | |
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
3 rows in set (0.01 sec)
mysql> update mysql_servers set hostgroup_id=2 where hostgroup_id=9002;
Query OK, 1 row affected (0.00 sec)
mysql> select * from mysql_servers;
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
| 9002 | 192.168.13.58 | 3306 | 0 | ONLINE | 100 | 0 | 10000 | 0 | 0 | 0 | |
| 1 | 192.168.13.25 | 3306 | 0 | ONLINE | 1000 | 0 | 10000 | 300 | 0 | 0 | |
| 2 | 192.168.13.25 | 3306 | 0 | ONLINE | 1000 | 0 | 10000 | 300 | 0 | 0 | |
+————–+—————+——+———–+——–+——–+————-+—————–+———————+———+—————-+———+
3 rows in set (0.00 sec)
Can you help me in resolving this ? As this is creating blocker for implementation in our environment.
Thanks.
Chaitanya Tondlekar
[email protected]