
In this blog post, we’ll discuss how we’ve improved TokuDB and PerconaFT fragmented data file performance.
Through our internal benchmarking and some user reports, we have found that with long term heavy write use TokuDB/PerconaFT performance can degrade significantly on large data files. Using smaller node sizes makes the problem worse (which is one of our performance tuning recommendations when you have faster storage). The problem manifests as low CPU utilization, a drop in overall TPS and high client response times during prolonged checkpointing.
This post explains a little about how PerconaFT structures dictionary files and where the current implementation breaks down. Hopefully, it explains the nature of the issue, and how our solution helps addresses it. It also provides some contrived benchmarks that prove the solution.
NOTE. This post uses the terms index, data file, and dictionary are somewhat interchangeable. We will use the PerconaFT term “dictionary” to refer specifically to a PerconaFT key/value data file.
PerconaFT stores every dictionary in its own data file on disk. TokuDB stores each index in a PerconaFT dictionary, plus one additional dictionary per table for some metadata. For example, if you have one TokuDB table with two secondary indices, you would have four data files or dictionaries: one small metadata dictionary for the table, one dictionary for the primary key/index, and one for each secondary index.
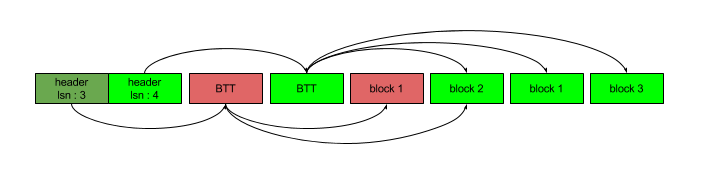
Each dictionary file has three major parts:
Each dictionary file contains two versions of the header stored on disk, and only one is valid at any given point in time. Since we fix the size of the header structure, we always know their locations. The first at offset zero, the other is immediately after the first. The header that is currently valid is the header with the later/larger CLSN.
We write the header and the BTT to disk during a checkpoint or when a dictionary is closed (the only time we do so). The header overwrites the older header (the one with the older CLSN) on disk. From that moment onward, the disk space used by the previous version of the dictionary (the whole thing, not just the header) that is not also used by the latest version, is considered immediately free.
There is much more magic to how the PerconaFT does checkpoint and consistency, but that is really out of the scope of this post. Maybe a later post that addresses the sharp checkpoint of the PerconaFT can dive into this.
The block allocator is the algorithm and container that manages the list of known used blocks and unused holes within an open dictionary file. When a node gets written, it is the responsibility of the block allocator to find a suitable location in the file for the nodes data. It is always placed into a new block, never overwrites an existing block (except for reclaimed block space from blocks that are removed or moved and recorded during the last checkpoint). Conversely, when a node gets destroyed it is the responsibility of the block allocator to release that used space and create a hole out of the old block. That hole also must be merged with any other holes that are adjacent to it to have a record of just one large hole rather than a series of consecutive smaller holes.
The current implementation of the PerconaFT block allocator maintains a simple array of used blocks in memory for each open dictionary. The used blocks are ordered ascending by their offset in the file. The holes between the blocks are calculated by knowing the offset and size of the two bounding blocks. For example, one can calculate the hole offset and size between two adjacent blocks as: b[n].offset + b[n].size and b[n+1].offset – (b[n].offset + b[n].size), respectively.

To find a suitable hole to place node data, the current block allocator starts at the first block in the array. It iterates through the blocks looking for a hole between blocks that is large enough to hold the nodes data. Once we find a hole, we cut the space needed for the node out of the hole and the remainder is left as a hole for another block to possibly use later.
Note. Forcing alignment to 512 offsets for direct I/O has overhead, regardless if direct I/O is used or not.
This linear search severely degrades the PerconaFT performance for very large and fragmented dictionary files. We have some solid evidence from the field that this does occur. We can see it via various profiling tools as a lot of time spent within block_allocator_strategy::first_fit. It is also quite easy to create a case by using very small node (block) sizes and small fanouts (forces the existence of more nodes, and thus more small holes). This fragmentation can and does cause all sorts of side effects as the search operation locks the entire structure within memory. It blocks nodes from translating their node/block IDs into file locations.
In this block storage paradigm, fragmentation is inevitable. We can try to dance around and propose different ways to prevent fragmentation (at the expense of higher CPU costs, online/offline operations, etc…). Or, we can look at the way the block allocator works and try to make it more efficient. Attacking the latter of the two options is a better strategy (not to say we aren’t still actively looking into the former).
The linear search block allocator has no idea where bigger and smaller holes might be located within the set (a core limitation). It must use brute force to find a hole big enough for the data it needs to store. To address this, we implemented a new in-memory, tree-based algorithm (red-black tree). This replaces the current in-memory linear array and integrates the hole size search into the tree structure itself.
In this new block allocator implementation, we store the set of known in-use blocks within the node structure of a binary tree instead of a linear array. We order the tree by the file offset of the blocks. We then added a little extra data to each node of this new tree structure. This data tells us the maximum hole we can expect to find in each child subtree. So now when searching for a hole, we can quickly drill down the tree to find an available hole of the correct size without needing to perform a fully linear scan. The trade off is that merging holes together and updating the parental max hole sizes is slightly more intricate and time-consuming than in a linear structure. The huge improvement in search efficiency makes this extra overhead pure noise.
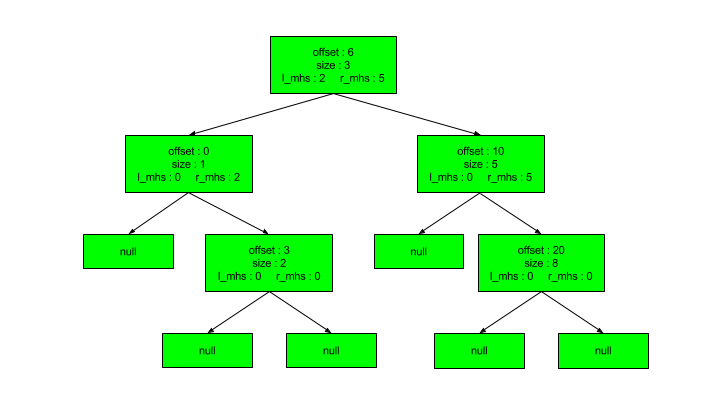
We can see in this overly simplified diagram, we have five blocks:
We can calculate four holes in between those blocks:
We see that the search for a 4-byte hole traverses down the right side of the tree. It discovers a hole at offset 15. This hole is a big enough for our 4 bytes. It does this without needing to visit the nodes at offsets 0 and 3. For you algorithmic folks out there, we have gone from an O(n) to O(log n) search. This is tremendously more efficient when we get into severe fragmentation states. A side effect is that we tend to allocate blocks from holes closer to the needed size rather than from the first one big enough to fit. The small hole fragmentation issue may actually increase over time, but that has yet to be seen in our testing.
As our CTO Vadim Tkachenko asserts, there are “Lies, Damned Lies and Benchmarks.” We’re going to show a simple test case where we thought, “What is the worst possible scenario that I can come up with in a small-ish benchmark to show the differences?“. So, rather than try and convince you using some pseudo-real-world benchmark that uses sleight of hand, I’m telling you up front that this example is slightly absurd, but pushes the issue to the foreground.
That scenario is actually pretty simple. We shape the tree to have as many nodes as possible, and intentionally use settings that reduce concurrency. We will use a standard sysbench OLTP test, and run it for about three hours after the prepare stage has completed:



So as you can see: amazing results, right? Sustained throughput, immensely better response time and better utilization of available CPU resources. Of course, this is all fake with a tree shape that no sane user would implement. It illustrates what happens when the linear list contains small holes: exactly what we set out to fix!
Look for this improvement to appear in Percona Server 5.6.32-78.0 and 5.7.14-7. It’s a good one for you if you have huge TokuDB data files with lots and lots of nodes.
Throughout this post, I referred to “we” numerous times. That “we” encompasses a great many people that have looked into this in the past and implemented the current solution. Some are current and former Percona and Tokutek employees that you may already know by name. Some are newer at Percona. I got to take their work and research, incorporate it into the current codebase, test and benchmark it, and report it here for all to see. Many thanks go out to Jun Yuan, Leif Walsh, John Esmet, Rich Prohaska, Bradley Kuszmaul, Alexey Stroganov, Laurynas Biveinis, Vlad Lesin, Christian Rober and others for all of the effort in diagnosing this issue, inventing a solution, and testing and reviewing this change to the PerconaFT library.





I’ve heard many times over the years that a major advantage of fractal tree over B tree is that it doesn’t fragment. It is a fundamental property of the fractal tree data structure: it cannot fragment.
For example, an early Percona blog post (https://www.percona.com/blog/2010/11/17/avoiding-fragmentation-with-fractal-trees/) said:
“Fractal trees don’t fragment. They can’t fragment. That means the primary table isn’t fragmented, and neither are the secondary indexes.”
But now it turns out fractal tree fragments just like B-tree does? So is fractal tree still a better choice than B-tree for write/update heavy workloads? Is there any benchmark to compare the two?
Interesting. This is the first time I have heard anyone assert that a fractal tree is immune from logical fragmentation. This is an old blog post from a former Tokutek employee whom I have never communicated with. It asserts that a fractal tree can not fragment but it presents no explanation how or why and presents no evidence to prove the case.
In essence, a fractal tree IS a BTree and the fractal tree files are just as susceptible to _disk_ based fragmentation as any other file. The tree structure itself might be less prone to logical data fragmentation but I believe that is simply a function of the node maintenance and tree balancing algorithms (splitting and merging) and can just as easily be implemented within any traditional BTree data structure.
Regardless, fractal trees do not gain their performance benefit because of this ‘never fragment’ assertion. They gain their performance in specific write heavy use cases through write collecting and deferred work (messaging).
The issue I describe in this blog post has little to do with the fractal tree itself though. The issue exists in the block file implementation that is used as the underlying storage mechanism for the fractal trees and the data structure it uses to track and locate unused regions within the file. It is very much like the way an in-memory allocator works, except that it is on disk. Perhaps fragmentation is not the best term that I could have used to describe this phenomenon but I could not think of another that was more suitable.
As far as blog posts and benchmarks, Vadim has made several over the years on different positive and negative aspects of TokuDB right here on the Percona Performance Blog. In a nutshell, if you are looking at TokuDB purely from a performance use case and ignore the space savings and SSD wear benefits, then slow storage, low concurrency, huge ratio of data to available memory and extremely heavy write load is where you will see TokuDB outperform InnoDB. Invert any of these conditions and the likelihood of the current iteration of TokuDB outperforming InnoDB starts to diminish quickly. I like to say that if you do not know specifically why you want to use TokuDB and what results you are expecting, then you are probably not going to be happy with it. It is a specific tool for a specific job, not a multi-tool for every job, at least not yet, we’re working on that 🙂
Thanks for the question!