
 In this blog post, we’ll discuss how to improve the performance of slow MySQL queries using Apache Spark.
In this blog post, we’ll discuss how to improve the performance of slow MySQL queries using Apache Spark.
In my previous blog post, I wrote about using Apache Spark with MySQL for data analysis and showed how to transform and analyze a large volume of data (text files) with Apache Spark. Vadim also performed a benchmark comparing the performance of MySQL and Spark with Parquet columnar format (using Air traffic performance data). That works great, but what if we don’t want to move our data from MySQL to another storage (i.e., columnar format), and instead want to use “ad hock” queries on top of an existing MySQL server? Apache Spark can help here as well.
Using Apache Spark on top of the existing MySQL server(s) (without the need to export or even stream data to Spark or Hadoop), we can increase query performance more than ten times. Using multiple MySQL servers (replication or Percona XtraDB Cluster) gives us an additional performance increase for some queries. You can also use the Spark cache function to cache the whole MySQL query results table.
The idea is simple: Spark can read MySQL data via JDBC and can also execute SQL queries, so we can connect it directly to MySQL and run the queries. Why is this faster? For long-running (i.e., reporting or BI) queries, it can be much faster as Spark is a massively parallel system. MySQL can only use one CPU core per query, whereas Spark can use all cores on all cluster nodes. In my examples below, MySQL queries are executed inside Spark and run 5-10 times faster (on top of the same MySQL data).
In addition, Spark can add “cluster” level parallelism. In the case of MySQL replication or Percona XtraDB Cluster, Spark can split the query into a set of smaller queries (in the case of a partitioned table it will run one query per each partition for example) and run those in parallel across multiple slave servers of multiple Percona XtraDB Cluster nodes. Finally, it will use map/reduce the type of processing to aggregate the results.
I’ve used the same “Airlines On-Time Performance” database as in previous posts. Vadim created some scripts to download data and upload it to MySQL. You can find the scripts here: https://github.com/Percona-Lab/ontime-airline-performance. I’ve also used Apache Spark 2.0, which was released July 26, 2016.
Starting Apache Spark in standalone mode is easy. To recap:
Example:
|
1 2 3 4 5 6 |
root@thor:~/spark# ./sbin/start-master.sh less ../logs/spark-root-org.apache.spark.deploy.master.Master-1-thor.out 15/08/25 11:21:21 INFO Master: Starting Spark master at spark://thor:7077 15/08/25 11:21:21 INFO Utils: Successfully started service 'MasterUI' on port 8080. 15/08/25 11:21:21 INFO MasterWebUI: Started MasterWebUI at http://10.60.23.188:8080 root@thor:~/spark# ./sbin/start-slave.sh spark://thor:7077 |
To connect to Spark we can use spark-shell (Scala), pyspark (Python) or spark-sql. Since spark-sql is similar to MySQL cli, using it would be the easiest option (even “show tables” works). I also wanted to work with Scala in interactive mode so I’ve used spark-shell as well. In all the examples I’m using the same SQL query in MySQL and Spark, so working with Spark is not that different.
To work with MySQL server in Spark we need Connector/J for MySQL. Download the package and copy the mysql-connector-java-5.1.39-bin.jar to the spark directory, then add the class path to the conf/spark-defaults.conf:
|
1 2 |
spark.driver.extraClassPath = /usr/local/spark/mysql-connector-java-5.1.39-bin.jar spark.executor.extraClassPath = /usr/local/spark/mysql-connector-java-5.1.39-bin.jar |
For this test I was using one physical server with 12 CPU cores (older Intel(R) Xeon(R) CPU L5639 @ 2.13GHz) and 48G of RAM, SSD disks. I’ve installed MySQL and started spark master and spark slave on the same box.
Now we are ready to run MySQL queries inside Spark. First, start the shell (from the Spark directory, /usr/local/spark in my case):
|
1 |
$ ./bin/spark-shell --driver-memory 4G --master spark://server1:7077 |
Then we will need to connect to MySQL from spark and register the temporary view:
|
1 2 3 4 5 6 7 8 |
val jdbcDF = spark.read.format("jdbc").options( Map("url" -> "jdbc:mysql://localhost:3306/ontime?user=root&password=", "dbtable" -> "ontime.ontime_part", "fetchSize" -> "10000", "partitionColumn" -> "yeard", "lowerBound" -> "1988", "upperBound" -> "2016", "numPartitions" -> "28" )).load() jdbcDF.createOrReplaceTempView("ontime") |
So we have created a “datasource” for Spark (or in other words, a “link” from Spark to MySQL). The Spark table name is “ontime” (linked to MySQL ontime.ontime_part table) and we can run SQL queries in Spark, which in turn parse it and translate it in MySQL queries.
“partitionColumn” is very important here. It tells Spark to run multiple queries in parallel, one query per each partition.
Now we can run the query:
|
1 2 |
val sqlDF = sql("select min(year), max(year) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') and (origin = 'RDU' or dest = 'RDU') GROUP by carrier HAVING cnt > 100000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10") sqlDF.show() |
Let’s go back to MySQL for a second and look at the query example. I’ve chosen the following query (from my older blog post):
|
1 2 3 4 5 6 7 8 9 10 11 |
select min(year), max(year) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 100000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10 |
The query will find the total number of delayed flights per each airline. In addition, the query will calculate the smart “ontime” rating, taking into consideration the number of flights (we do not want to compare smaller air carriers with the large ones, and we want to exclude the older airlines who are not in business anymore).
The main reason I’ve chosen this query is that it is hard to optimize it in MySQL. All conditions in the “where” clause will only filter out ~70% of rows. I’ve done a basic calculation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> select count(*) FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI'); +-----------+ | count(*) | +-----------+ | 108776741 | +-----------+ mysql> select count(*) FROM ontime; +-----------+ | count(*) | +-----------+ | 152657276 | +-----------+ mysql> select round((108776741/152657276)*100, 2); +-------------------------------------+ | round((108776741/152657276)*100, 2) | +-------------------------------------+ | 71.26 | +-------------------------------------+ |
Table structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
CREATE TABLE `ontime_part` ( `YearD` int(11) NOT NULL, `Quarter` tinyint(4) DEFAULT NULL, `MonthD` tinyint(4) DEFAULT NULL, `DayofMonth` tinyint(4) DEFAULT NULL, `DayOfWeek` tinyint(4) DEFAULT NULL, `FlightDate` date DEFAULT NULL, `UniqueCarrier` char(7) DEFAULT NULL, `AirlineID` int(11) DEFAULT NULL, `Carrier` char(2) DEFAULT NULL, `TailNum` varchar(50) DEFAULT NULL, ... `id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`,`YearD`), KEY `covered` (`DayOfWeek`,`OriginState`,`DestState`,`Carrier`,`YearD`,`ArrDelayMinutes`) ) ENGINE=InnoDB AUTO_INCREMENT=162668935 DEFAULT CHARSET=latin1 /*!50100 PARTITION BY RANGE (YearD) (PARTITION p1987 VALUES LESS THAN (1988) ENGINE = InnoDB, PARTITION p1988 VALUES LESS THAN (1989) ENGINE = InnoDB, PARTITION p1989 VALUES LESS THAN (1990) ENGINE = InnoDB, PARTITION p1990 VALUES LESS THAN (1991) ENGINE = InnoDB, PARTITION p1991 VALUES LESS THAN (1992) ENGINE = InnoDB, PARTITION p1992 VALUES LESS THAN (1993) ENGINE = InnoDB, PARTITION p1993 VALUES LESS THAN (1994) ENGINE = InnoDB, PARTITION p1994 VALUES LESS THAN (1995) ENGINE = InnoDB, PARTITION p1995 VALUES LESS THAN (1996) ENGINE = InnoDB, PARTITION p1996 VALUES LESS THAN (1997) ENGINE = InnoDB, PARTITION p1997 VALUES LESS THAN (1998) ENGINE = InnoDB, PARTITION p1998 VALUES LESS THAN (1999) ENGINE = InnoDB, PARTITION p1999 VALUES LESS THAN (2000) ENGINE = InnoDB, PARTITION p2000 VALUES LESS THAN (2001) ENGINE = InnoDB, PARTITION p2001 VALUES LESS THAN (2002) ENGINE = InnoDB, PARTITION p2002 VALUES LESS THAN (2003) ENGINE = InnoDB, PARTITION p2003 VALUES LESS THAN (2004) ENGINE = InnoDB, PARTITION p2004 VALUES LESS THAN (2005) ENGINE = InnoDB, PARTITION p2005 VALUES LESS THAN (2006) ENGINE = InnoDB, PARTITION p2006 VALUES LESS THAN (2007) ENGINE = InnoDB, PARTITION p2007 VALUES LESS THAN (2008) ENGINE = InnoDB, PARTITION p2008 VALUES LESS THAN (2009) ENGINE = InnoDB, PARTITION p2009 VALUES LESS THAN (2010) ENGINE = InnoDB, PARTITION p2010 VALUES LESS THAN (2011) ENGINE = InnoDB, PARTITION p2011 VALUES LESS THAN (2012) ENGINE = InnoDB, PARTITION p2012 VALUES LESS THAN (2013) ENGINE = InnoDB, PARTITION p2013 VALUES LESS THAN (2014) ENGINE = InnoDB, PARTITION p2014 VALUES LESS THAN (2015) ENGINE = InnoDB, PARTITION p2015 VALUES LESS THAN (2016) ENGINE = InnoDB, PARTITION p_new VALUES LESS THAN MAXVALUE ENGINE = InnoDB) */ |
Even with a “covered” index, MySQL will have to scan ~70M-100M of rows and create a temporary table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> explain select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime_part WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: ontime_part type: range possible_keys: covered key: covered key_len: 2 ref: NULL rows: 70483364 Extra: Using where; Using index; Using temporary; Using filesort 1 row in set (0.00 sec) |
What is the query response time in MySQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
mysql> select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime_part WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10; +------------+----------+---------+----------+-----------------+------+ | min(yearD) | max_year | Carrier | cnt | flights_delayed | rate | +------------+----------+---------+----------+-----------------+------+ | 2003 | 2013 | EV | 2962008 | 464264 | 0.16 | | 2003 | 2013 | B6 | 1237400 | 187863 | 0.15 | | 2006 | 2011 | XE | 1615266 | 230977 | 0.14 | | 2003 | 2005 | DH | 501056 | 69833 | 0.14 | | 2001 | 2013 | MQ | 4518106 | 605698 | 0.13 | | 2003 | 2013 | FL | 1692887 | 212069 | 0.13 | | 2004 | 2010 | OH | 1307404 | 175258 | 0.13 | | 2006 | 2013 | YV | 1121025 | 143597 | 0.13 | | 2003 | 2006 | RU | 1007248 | 126733 | 0.13 | | 1988 | 2013 | UA | 10717383 | 1327196 | 0.12 | +------------+----------+---------+----------+-----------------+------+ 10 rows in set (19 min 16.58 sec) |
19 minutes is definitely not great.
Now we want to run the same query inside Spark and let Spark read data from MySQL. We will create a “datasource” and execute the query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
scala> val jdbcDF = spark.read.format("jdbc").options( | Map("url" -> "jdbc:mysql://localhost:3306/ontime?user=root&password=mysql", | "dbtable" -> "ontime.ontime_sm", | "fetchSize" -> "10000", | "partitionColumn" -> "yeard", "lowerBound" -> "1988", "upperBound" -> "2015", "numPartitions" -> "48" | )).load() 16/08/02 23:24:12 WARN JDBCRelation: The number of partitions is reduced because the specified number of partitions is less than the difference between upper bound and lower bound. Updated number of partitions: 27; Input number of partitions: 48; Lower bound: 1988; Upper bound: 2015. dbcDF: org.apache.spark.sql.DataFrame = [id: int, YearD: date ... 19 more fields] scala> jdbcDF.createOrReplaceTempView("ontime") scala> val sqlDF = sql("select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime WHERE OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10") sqlDF: org.apache.spark.sql.DataFrame = [min(yearD): date, max_year: date ... 4 more fields] scala> sqlDF.show() +----------+--------+-------+--------+---------------+----+ |min(yearD)|max_year|Carrier| cnt|flights_delayed|rate| +----------+--------+-------+--------+---------------+----+ | 2003| 2013| EV| 2962008| 464264|0.16| | 2003| 2013| B6| 1237400| 187863|0.15| | 2006| 2011| XE| 1615266| 230977|0.14| | 2003| 2005| DH| 501056| 69833|0.14| | 2001| 2013| MQ| 4518106| 605698|0.13| | 2003| 2013| FL| 1692887| 212069|0.13| | 2004| 2010| OH| 1307404| 175258|0.13| | 2006| 2013| YV| 1121025| 143597|0.13| | 2003| 2006| RU| 1007248| 126733|0.13| | 1988| 2013| UA|10717383| 1327196|0.12| +----------+--------+-------+--------+---------------+----+ |
spark-shell does not show the query time. This can be retrieved from Web UI or from spark-sql. I’ve re-run the same query in spark-sql:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
./bin/spark-sql --driver-memory 4G --master spark://thor:7077 spark-sql> CREATE TEMPORARY VIEW ontime > USING org.apache.spark.sql.jdbc > OPTIONS ( > url "jdbc:mysql://localhost:3306/ontime?user=root&password=", > dbtable "ontime.ontime_part", > fetchSize "1000", > partitionColumn "yearD", lowerBound "1988", upperBound "2014", numPartitions "48" > ); 16/08/04 01:44:27 WARN JDBCRelation: The number of partitions is reduced because the specified number of partitions is less than the difference between upper bound and lower bound. Updated number of partitions: 26; Input number of partitions: 48; Lower bound: 1988; Upper bound: 2014. Time taken: 3.864 seconds spark-sql> select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10; 16/08/04 01:45:13 WARN Utils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.debug.maxToStringFields' in SparkEnv.conf. 2003 2013 EV 2962008 464264 0.16 2003 2013 B6 1237400 187863 0.15 2006 2011 XE 1615266 230977 0.14 2003 2005 DH 501056 69833 0.14 2001 2013 MQ 4518106 605698 0.13 2003 2013 FL 1692887 212069 0.13 2004 2010 OH 1307404 175258 0.13 2006 2013 YV 1121025 143597 0.13 2003 2006 RU 1007248 126733 0.13 1988 2013 UA 10717383 1327196 0.12 Time taken: 139.628 seconds, Fetched 10 row(s) |
So the response time of the same query is almost 10x faster (on the same server, just one box). But now how was this query translated to MySQL queries, and why it is so much faster? Here is what is happening inside MySQL:
Spark:
|
1 2 |
scala> sqlDF.show() [Stage 4:> (0 + 26) / 26] |
MySQL:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
mysql> select id, info from information_schema.processlist where info is not NULL and info not like '%information_schema%'; +-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | id | info | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | 10948 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2001 AND yearD < 2002) | | 10965 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2007 AND yearD < 2008) | | 10966 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1991 AND yearD < 1992) | | 10967 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1994 AND yearD < 1995) | | 10968 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1998 AND yearD < 1999) | | 10969 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2010 AND yearD < 2011) | | 10970 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2002 AND yearD < 2003) | | 10971 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2006 AND yearD < 2007) | | 10972 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1990 AND yearD < 1991) | | 10953 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2009 AND yearD < 2010) | | 10947 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1993 AND yearD < 1994) | | 10956 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD < 1989 or yearD is null) | | 10951 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2005 AND yearD < 2006) | | 10954 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1996 AND yearD < 1997) | | 10955 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2008 AND yearD < 2009) | | 10961 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1999 AND yearD < 2000) | | 10962 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2011 AND yearD < 2012) | | 10963 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2003 AND yearD < 2004) | | 10964 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1995 AND yearD < 1996) | | 10957 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2004 AND yearD < 2005) | | 10949 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1989 AND yearD < 1990) | | 10950 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1997 AND yearD < 1998) | | 10952 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2013) | | 10958 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 1992 AND yearD < 1993) | | 10960 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2000 AND yearD < 2001) | | 10959 | SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2012 AND yearD < 2013) | +-------+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ 26 rows in set (0.00 sec) |
Spark is running 26 queries in parallel, which is great. As the table is partitioned it only uses one partition per query, but scans the whole partition:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
mysql> explain partitions SELECT `YearD`,`ArrDelayMinutes`,`Carrier` FROM ontime.ontime_part WHERE (((NOT (DayOfWeek IN (6, 7)))) AND ((NOT (OriginState IN ('AK', 'HI', 'PR', 'VI')))) AND ((NOT (DestState IN ('AK', 'HI', 'PR', 'VI'))))) AND (yearD >= 2001 AND yearD < 2002)G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: ontime_part partitions: p2001 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 5814106 Extra: Using where 1 row in set (0.00 sec) |
In this case, as the box has 12 CPU cores / 24 threads, it efficiently executes 26 queries in parallel and the partitioned table helps to avoid contention issues (I wish MySQL could scan partitions in parallel, but it can’t at the time of writing).
Another interesting thing is that Spark can “push down” some of the conditions to MySQL, but only those inside the “where” clause. All group by/order by/aggregations are done inside Spark. It needs to retrieve data from MySQL to satisfy those conditions and will not push down group by/order by/etc to MySQL.
That also means that queries without “where” conditions (for example “select count(*) as cnt, carrier from ontime group by carrier order by cnt desc limit 10”) will have to retrieve all data from MySQL and load it to Spark (as opposed to MySQL will do all group by inside). Running it in Spark might be slower or faster (depending on the amount of data and use of indexes) but it also requires more resources and potentially more memory dedicated for Spark. The above query is translated to 26 queries, each does a “select carrier from ontime_part where (yearD >= N AND yearD < N)”
If we want to avoid sending all data from MySQL to Spark we have the option of creating a temporary table on top of a query (similar to MySQL’s create temporary table as select …). In Scala:
|
1 2 3 4 5 6 7 8 9 10 |
val tableQuery = "(select yeard, count(*) from ontime group by yeard) tmp" val jdbcDFtmp = spark.read.format("jdbc").options( Map("url" -> "jdbc:mysql://localhost:3306/ontime?user=root&password=", "dbtable" -> tableQuery, "fetchSize" -> "10000" )).load() jdbcDFtmp.createOrReplaceTempView("ontime_tmp") |
In Spark SQL:
|
1 2 3 4 5 6 7 8 9 |
CREATE TEMPORARY VIEW ontime_tmp USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:mysql://localhost:3306/ontime?user=root&password=mysql", dbtable "(select yeard, count(*) from ontime_part group by yeard) tmp", fetchSize "1000" ); select * from ontime_tmp; |
Please note:
Another option is to cache the result of the query (or even the whole table) and then use .filter in Scala for faster processing. This requires sufficient memory dedicated for Spark. The good news is we can add additional nodes to Spark and get more memory for Spark cluster.
Spark SQL example:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
CREATE TEMPORARY VIEW ontime_latest USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:mysql://localhost:3306/ontime?user=root&password=", dbtable "ontime.ontime_part partition (p2013, p2014)", fetchSize "1000", partitionColumn "yearD", lowerBound "1988", upperBound "2014", numPartitions "26" ); cache table ontime_latest; spark-sql> cache table ontime_latest; Time taken: 465.076 seconds spark-sql> select count(*) from ontime_latest; 5349447 Time taken: 0.526 seconds, Fetched 1 row(s) spark-sql> select count(*), dayofweek from ontime_latest group by dayofweek; 790896 1 634664 6 795540 3 794667 5 808243 4 743282 7 782155 2 Time taken: 0.541 seconds, Fetched 7 row(s) spark-sql> select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime_latest WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') and (origin='RDU' or dest = 'RDU') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10; 2013 2013 MQ 9339 1734 0.19 2013 2013 B6 3302 516 0.16 2013 2013 EV 9225 1331 0.14 2013 2013 UA 1317 177 0.13 2013 2013 AA 5354 620 0.12 2013 2013 9E 5520 593 0.11 2013 2013 WN 10968 1130 0.1 2013 2013 US 5722 549 0.1 2013 2013 DL 6313 478 0.08 2013 2013 FL 2433 205 0.08 Time taken: 2.036 seconds, Fetched 10 row(s) |
Here we cache partitions p2013 and p2014 in Spark. This retrieves the data from MySQL and loads it in Spark. After that all queries run on the cached data and will be much faster.
With Scala we can cache the result of a query and then use filters to only get the information we need:
|
1 2 3 4 |
val sqlDF = sql("SELECT flightdate, origin, dest, depdelayminutes, arrdelayminutes, carrier, TailNum, Cancelled, Diverted, Distance from ontime") sqlDF.cache().show() scala> sqlDF.filter("flightdate='1988-01-01'").count() res5: Long = 862 |
As Spark can be used in a cluster mode and scale with more and more nodes, reading data from a single MySQL is a bottleneck. We can use MySQL replication slave servers or Percona XtraDB Cluster (PXC) nodes as a Spark datasource. To test it out, I’ve provisioned Percona XtraDB Cluster with three nodes on AWS (I’ve used m4.2xlarge Ubuntu instances) and also started Apache Spark on each node:
All the Spark worker nodes use the memory configuration option:
|
1 2 |
cat conf/spark-env.sh export SPARK_WORKER_MEMORY=24g |
Then I can start spark-sql (also need to have connector/J JAR file copied to all nodes):
|
1 |
$ ./bin/spark-sql --driver-memory 4G --master spark://pxc1:7077 |
When creating a table, I still use localhost to connect to MySQL (url “jdbc:mysql://localhost:3306/ontime?user=root&password=xxx”). As Spark worker nodes are running on the same instance as Percona Cluster nodes, it will use the local connection. Then running a Spark SQL will evenly distribute all 26 MySQL queries among the three MySQL nodes.
Alternatively we can run Spark cluster on a separate host and connect it to the HA Proxy, which in turn will load balance selects across multiple Percona XtraDB Cluster nodes.
Finally, here is the query response time test on the three AWS Percona XtraDB Cluster nodes:
Query 1: select min(yearD), max(yearD) as max_year, Carrier, count(*) as cnt, sum(if(ArrDelayMinutes>30, 1, 0)) as flights_delayed, round(sum(if(ArrDelayMinutes>30, 1, 0))/count(*),2) as rate FROM ontime_part WHERE DayOfWeek not in (6,7) and OriginState not in ('AK', 'HI', 'PR', 'VI') and DestState not in ('AK', 'HI', 'PR', 'VI') GROUP by carrier HAVING cnt > 1000 and max_year > '1990' ORDER by rate DESC, cnt desc LIMIT 10;
| Query / Index type | MySQL Time | Spark Time (3 nodes) | Times Improvement |
| No covered index (partitioned) | 19 min 16.58 sec | 192.17 sec | 6.02 |
| Covered index (partitioned) | 2 min 10.81 sec | 48.38 sec | 2.7 |
Query 2: select dayofweek, count(*) from ontime_part group by dayofweek;
| Query / Index type | MySQL Time | Spark Time (3 nodes) | Times Improvement |
| No covered index (partitoned) | 19 min 15.21 sec | 195.058 sec | 5.92 |
| Covered index (partitioned) | 1 min 10.38 sec | 27.323 sec | 2.58 |
Now, this looks really good, but it can be better. With three nodes @ m4.2xlarge we will have 8*3 = 24 cores total (although they are shared between Spark and MySQL). We can expect 10x improvement, especially without a covered index.
However, on m4.2xlarge the amount of RAM did not allow me to run MySQL out of memory, so all reads were from EBS non-provisioned IOPS, which only gave me ~120MB/sec. I’ve redone the test on a set of three dedicated servers:
The test was running completely off RAM:
Query 1 (from the above)
| Query / Index type | MySQL Time | Spark Time (3 nodes) | Times Improvement |
| No covered index (partitoned) | 3 min 13.94 sec | 14.255 sec | 13.61 |
| Covered index (partitioned) | 2 min 2.11 sec | 9.035 sec | 13.52 |
Query 2: select dayofweek, count(*) from ontime_part group by dayofweek;
| Query / Index type | MySQL Time | Spark Time (3 nodes) | Times Improvement |
| No covered index (partitoned) | 2 min 0.36 sec | 7.055 sec | 17.06 |
| Covered index (partitioned) | 1 min 6.85 sec | 4.514 sec | 14.81 |
With this amount of cores and running out of RAM we actually do not have enough concurrency as the table only have 26 partitions. I’ve tried the unpartitioned table with ID primary key and use 128 partitions.
I’ve used partitioned table (partition by year) in my tests to help reduce MySQL level contention. At the same time the “partitionColumn” option in Spark does not require that MySQL table is partitioned. For example, if a table has a primary key, we can use this CREATE VIEW in Spark :
|
1 2 3 4 5 6 7 8 |
CREATE OR REPLACE TEMPORARY VIEW ontime USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:mysql://127.0.0.1:3306/ontime?user=root&password=", dbtable "ontime.ontime", fetchSize "1000", partitionColumn "id", lowerBound "1", upperBound "162668934", numPartitions "128" ); |
Assuming we have enough MySQL servers (i.e., nodes or slaves), we can increase the number of partitions and that can improve the parallelism (as opposed to only 26 partitions when running one partition by year). Actually, the above test gives us even better response time: 6.44 seconds for query 1.
For faster queries (those that use indexes or can efficiently use an index) it does not make sense to use Spark. Retrieving data from MySQL and loading it into Spark is not free. This overhead can be significant for faster queries. For example, a query like this select count(*) from ontime_part where YearD = 2013 and DayOfWeek = 7 and OriginState = 'NC' and DestState = 'NC'; will only scan 1300 rows and will return instant (0.00 seconds reported by MySQL).
An even better example is this: select max(id) from ontime_part. In MySQL, the query will use the index and all calculations will be done inside MySQL. Spark, on the other hand, will have to retrieve all IDs (select id from ontime_part) from MySQL and calculate maximum. That took 24.267 seconds.
Using Apache Spark as an additional engine level on top of MySQL can help to speed up the slow reporting queries and add much-needed scalability for the long running select queries. In addition, Spark can help with query caching for frequent queries.
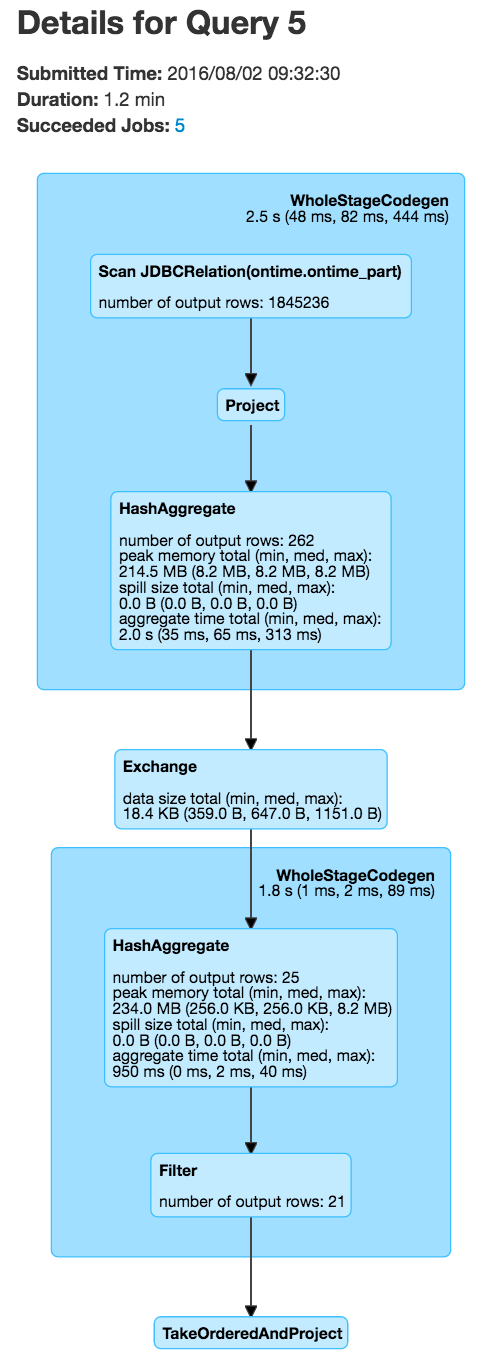
Spark Web GUI provides lots of ways of monitoring Spark jobs. For example, it shows the “job” progress:

And SQL visual explain details:





Or you could use Shard-Query and just talk over the wire to your MySQL server using MySQL proxy or by using the stored procedure execution method. No need for an extra JDBC layer if, for example, you have a GO or PHP app.
Shard-Query also adds support for scale-out (sharding), window functions, and more.
I would awesome, and helpful, to see this post repeated in similar detail using shard-query.
Good Article. It is helpful for MySQL db optimization.
I am happy about this article and using this technology, but I would like to make a comment as to how it can be used in the right context and the right use case:
1) If you had a report that only needed to be run once a year, bi-year, quarterly, monthly or even weekly, then waiting 19 minutes is not so bad Vs setting up a new server with a new technology and maintaining that.
2) If you need the report more frequently, then updating an intermediate or summary table once a day, a couple of times a day or hourly, would be more cost, time and resource effective.
3) If the data is too big for that AND you have sharded your data across a few servers – lets say, a server per destination/continent – then this technology is absolutely amazing and exactly what you would need.
Jonathan, thank you for your comment, I totally agree here!
I loaded the airline data using the scripts posted on 9/14/16.
The tables we have different row counts?
For example:
Your query:
mysql> select count(*) FROM ontime;
+———–+
| count(*) |
+———–+
| 152657276 |
+———–+
Mine:
SQL> select count(*) from ontime;
COUNT(*)
———-
163841725
Elapsed: 00:00:00.02
Your query:
mysql> select count(*) FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’) and DestState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’);
+———–+
| count(*) |
+———–+
| 108776741 |
+———–+
Mine:
SQL> select count(*) FROM ontime WHERE DayOfWeek not in (6,7) and OriginState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’) and DestState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’);
COUNT(*)
———-
116642066
For example in Q1 – Just partitioning, no indexes, IMDB, DOP=4, cold cache with no warming, left of limit clause to see the actual rows so we can compare values
SQL> select min(yeard) min_year,
max(yeard) max_year,
Carrier,
count(*) as cnt,
sum(case
when ArrDelayMinutes > 30 THEN 1
else 0
end
)as flights_delayed,
round(sum(case
when ArrDelayMinutes > 30 THEN 1
else 0
end
)/count(*), 2) as rate
FROM ontime
WHERE DayOfWeek not in (6,7) and OriginState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’)
and DestState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’)
GROUP by Carrier
HAVING count(*) > 1000
and max(yeard) > 1990
ORDER by rate DESC, count(*) desc
/
MIN_YEAR MAX_YEAR CA CNT FLIGHTS_DELAYED RATE
———- ———- — ———- ————— ———-
2015 2015 NK 82151 15476 .19
2003 2015 EV 3989473 617177 .15
2003 2015 B6 1597104 239929 .15
2001 2015 MQ 5047969 689042 .14
2006 2011 XE 1615266 230977 .14
2003 2005 DH 501056 69833 .14
2004 2010 OH 1307404 175258 .13
2006 2013 YV 1136242 145135 .13
2003 2006 RU 1007248 126733 .13
1987 2015 UA 11033601 1375462 .12
2003 2014 FL 1766874 219155 .12
2003 2006 TZ 136735 16496 .12
1987 2015 AA 13019769 1476071 .11
1987 2011 CO 6441970 720484 .11
1987 2001 TW 2563283 271861 .11
2007 2013 9E 998404 105391 .11
2005 2015 F9 673387 77295 .11
2012 2015 VX 170041 19156 .11
1987 2015 DL 15247116 1460094 .1
1988 2015 US 11345314 1086779 .1
1987 2009 NW 7430117 709326 .1
2003 2015 OO 5317133 552988 .1
1987 2015 WN 17958919 1690362 .09
1987 2005 HP 2467155 219645 .09
1987 2015 AS 1839322 160592 .09
1987 1991 PA 215108 20258 .09
1991 1991 ML 51867 3608 .07
2001 2008 AQ 4408 198 .04
28 rows selected.
Elapsed: 00:00:02.76
Query 2:
SQL> select dayofweek, count(*) from ontime group by dayofweek;
DAYOFWEEK COUNT(*)
———- ———-
2 23889775
4 24085159
7 22813815
6 20792612
5 24113594
1 24146309
3 24000461
7 rows selected.
Elapsed: 00:00:00.72
Hardware: 2011 Macbook Pro laptop running Oracle 12c on VirtualBox VM – 4 core, 10GB RAM, single SSD. I plan on loading this dataset up on S7 Server to see what kind of DAX offloading/benefits you will receive with SparkSQL – advertised is 9X gains.
As you can see Oracle 12.2 in-memory parallel query is much faster! Small laptop destroying many larger server configurations with sparksql.
On sparc, 12.2, I’m getting 180-220B rows second per core by leveraging the DAX database accelerators. The good news is the DAX API natively supports Spark so it fully offloads to the offloading gpu’s. So you could use the sparc chips to run faster mysql/ sparksql by 10x over Intel.
Otherwise, just leverage big data sql and create in memory external table of the files on hdfs or perform smartscan on hdfs or nosql tables. Use regular sql/jdbc and a single security model for all your data in different polyglot systems.
Yes, I have also wrote about Clickhouse recently which is also pretty fast and run on a single node.
When Spark loads data from a table does the load happen on a single node in the cluster or should the query work be spread across several nodes depending on the size of the results? I have read references regarding MySQL saying that data is loaded on a single node and then parallized? I am interested from an Oracle side but I think this is a general question. I get executor failures when trying to load a full large table which is approx the size of RAM on a single node in the cluster. Any help appreciated!
Unfortunately Spark and MySQL does not love each other. Spark 1.6 cannot process by default large MySQL files that does not fit in memory. You have to set fetchsize to Integer.MIN_VALUE. It will force fetchsize to 1, any slowly but steady can deal with MySQL large tables.
Now, Spark 2 decide to check foe negative parameters, so it does not allow Integer.MIN_VALUE, so it just does not work.
Hello Alexander Can you tell me probably that how much RAM need to use for some ammount of Data for example i have 18 GB RAM machine and i need to work with 5 GB data / 3 caror 50 lacs Raws will it be possible?
Can you tell me that how much RAM is succifient for how much data ?
Thanks
I updated the results to reflect Oracle 12.2 with the latest airline data pulled (1987-2017) on a new Macbook Pro with 9 other Pluggable Databases running. I created a Pluggable database called Kraken.
–Used External Table Preprocessor so I can parallel unzip, load into in-memory, query.
SQL> conn airline/airline@kraken
Connected.
SQL> set timing on
SQL> select count(*) from ontime;
COUNT(*)
———-
173277113
Elapsed: 00:00:00.15
Query1
SQL> select min(yeard) min_year,
max(yeard) max_year,
Carrier,
count(*) as cnt,
sum(case
when ArrDelayMinutes > 30 THEN 1
else 0
end
)as flights_delayed,
round(sum(case
when ArrDelayMinutes > 30 THEN 1
else 0
end
)/count(*), 2) as rate
FROM ontime
WHERE DayOfWeek not in (6,7) and OriginState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’)
and DestState not in (‘AK’, ‘HI’, ‘PR’, ‘VI’)
GROUP by Carrier
HAVING count(*) > 1000
and max(yeard) > 1990
ORDER by rate DESC, count(*) desc
/
MIN_YEAR MAX_YEAR CA CNT FLIGHTS_DELAYED RATE
———- ———- — ———- ————— ———-
2015 2017 NK 252352 42433 .17
2003 2017 B6 1916168 297666 .16
2003 2017 EV 4548031 689699 .15
2001 2015 MQ 5047969 689042 .14
2006 2011 XE 1615266 230977 .14
2003 2005 DH 501056 69833 .14
2004 2010 OH 1307404 175258 .13
2006 2013 YV 1136242 145135 .13
2003 2006 RU 1007248 126733 .13
2012 2017 VX 253244 33336 .13
1987 2017 UA 11695349 1457354 .12
2003 2014 FL 1766874 219155 .12
2005 2017 F9 788494 94298 .12
2003 2006 TZ 136735 16496 .12
1987 2017 AA 14095227 1604675 .11
1987 2011 CO 6441970 720484 .11
2003 2017 OO 6107403 645357 .11
1987 2001 TW 2563283 271861 .11
2007 2013 9E 998404 105391 .11
1987 2017 WN 19575287 1868474 .1
1987 2017 DL 16372845 1558507 .1
1988 2015 US 11345314 1086779 .1
1987 2009 NW 7430117 709326 .1
1987 2005 HP 2467155 219645 .09
1987 2017 AS 1986491 172876 .09
1987 1991 PA 215108 20258 .09
1991 1991 ML 51867 3608 .07
2001 2008 AQ 4408 198 .04
28 rows selected.
Elapsed: 00:00:00.84
Query2
SQL> select DayOfWeek, count(*) from ontime group by DayOfWeek;
DAYOFWEEK COUNT(*)
———- ———-
6 21935781
1 25545423
4 25491699
5 25522447
7 24132802
3 25388310
2 25260651
7 rows selected.
Elapsed: 00:00:00.23
I’m working on a sharded 12.2 (3 node) DB to see next.
Very nice article sir… please sir can you give similar tutorial for spark where realtime time data is to be calculated ,sorted and ready for user to view, for example in fatancy sport application where there are so many teams being created and for those team score needs to be updated on the basis of realtime match information…i am assumng that before calculation all the data can be loaded in the memory of spark and then update operation can be perform which will be realtime. but i cannot find update for spark-sql
Anand, if I understood you correctly, you are looking for updates. Usually Apache Spark is used for select queries only. Massively parallel updates are tricky. I may write about it in the near future.
Sur I think that can be achieved via transformation mean transforming one dataframe into another and deleting the old one….Pls go to https://gamechanger.dream11.in/blog/leaderboard-dream11/ they have uses spark for point calculation on realtime basis….
Paul, a single MySQL query will always got to 1 MySQL node. Multiple queries can go to different nodes.