
In this blog post, we’ll discuss how to use multi-threaded LRU flushing to prevent bottlenecks in MySQL.
In the previous post, we saw that InnoDB 5.7 performs a lot of single-page LRU flushes, which in turn are serialized by the shared doublewrite buffer. Based on our 5.6 experience we have decided to attack the single-page flush issue first.
Let’s start with describing a single-page flush. If the working set of a database instance is bigger than the available buffer pool, existing data pages will have to be evicted or flushed (and then evicted) to make room for queries reading in new pages. InnoDB tries to anticipate this by maintaining a list of free pages per buffer pool instance; these are the pages that can be immediately used for placing the newly-read data pages. The target length of the free page list is governed by the innodb_lru_scan_depth parameter, and the cleaner threads are tasked with refilling this list by performing LRU batch flushing. If for some reason the free page demand exceeds the cleaner thread flushing capability, the server might find itself with an empty free list. In an attempt to not stall the query thread asking for a free page, it will then execute a single-page LRU flush ( buf_LRU_get_free_block calling buf_flush_single_page_from_LRU in the source code), which is performed in the context of the query thread itself.
The problem with this flushing mode is that it will iterate over the LRU list of a buffer pool instance, while holding the buffer pool mutex in InnoDB (or the finer-grained LRU list mutex in XtraDB). Thus, a server whose cleaner threads are not able to keep up with the LRU flushing demand will have further increased mutex pressure – which can further contribute to the cleaner thread troubles. Finally, once the single-page flusher finds a page to flush it might have trouble in getting a free doublewrite buffer slot (as shown previously). That suggested to us that single-page LRU flushes are never a good idea. The flame graph below demonstrates this:

Note how a big part of the server run time is attributed to a flame rooted at JOIN::optimize, whose run time in turn is almost fully taken by buf_dblwr_write_single_page in two branches.
The easiest way not to avoid a single-page flush is, well, simply not to do it! Wait until a cleaner thread finally provides some free pages for the query thread to use. This is what we did in XtraDB 5.6 with the innodb_empty_free_list_algorithm server option (which has a “backoff” default). This is also present in XtraDB 5.7, and resolves the issues of increased contentions for the buffer pool (LRU list) mutex and doublewrite buffer single-page flush slots. This approach handles the the empty free page list better.
Even with this strategy it’s still a bad situation to be in, as it causes query stalls when page cleaner threads aren’t able to keep up with the free page demand. To understand why this happens, let’s look into a simplified scheme of InnoDB 5.7 multi-threaded LRU flushing:
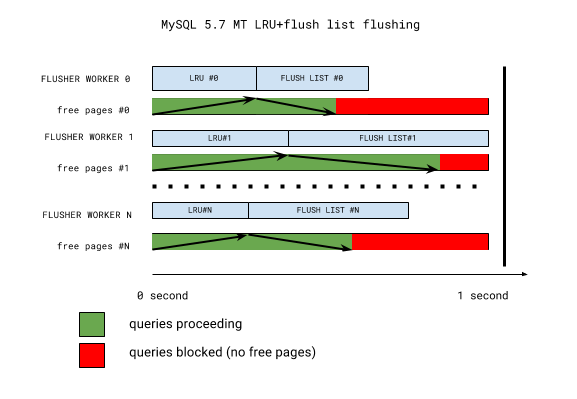
The key takeaway from the picture is that LRU batch flushing does not necessarily happen when it’s needed the most. All buffer pool instances have their LRU lists flushed first (for free pages), and flush lists flushed second (for checkpoint age and buffer pool dirty page percentage targets). If the flush list flush is in progress, LRU flushing will have to wait until the next iteration. Further, all flushing is synchronized once per second-long iteration by the coordinator thread waiting for everything to complete. This one second mark may well become a thirty or more second mark if one of the workers is stalled (with the telltale sign: “InnoDB: page_cleaner: 1000ms intended loop took 49812ms”) in the server error log. So if we have a very hot buffer pool instance, everything else will have to wait for it. And it’s long been known that buffer pool instances are not used uniformly (some are hotter and some are colder).
A fix should:
We developed a design based on the above criteria, where each buffer pool instance has its own private LRU flusher thread. That thread monitors the free list length of its instance, flushes, and sleeps until the next free list length check. The sleep time is adjusted depending on the free list length: thus a hot instance LRU flusher may not sleep at all in order to keep up with the demand, while a cold instance flusher might only wake up once per second for a short check.
The LRU flushing scheme now looks as follows:
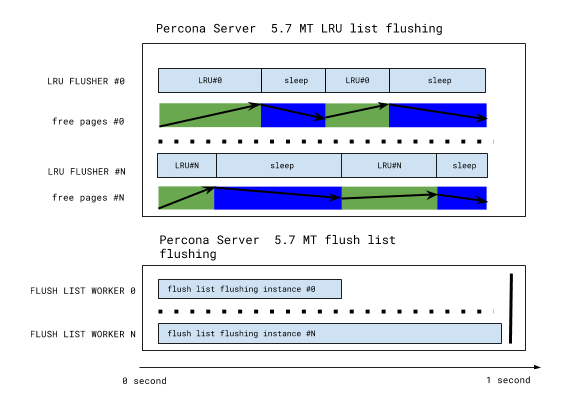
This has been implemented in the Percona Server 5.7.10-3 RC release, and this design the simplified the code as well. LRU flushing heuristics are simple, and any LRU flushing is now removed from the legacy cleaner coordinator/worker threads – enabling more efficient flush list flushing as well. LRU flusher threads are the only threads that can flush a given buffer pool instance, enabling further simplification: for example, InnoDB recovery writer threads simply disappear.
Are we done then? No. With the single-page flushes and single-page flush doublewrite bottleneck gone, we hit the doublewrite buffer again. We’ll cover that in the next post.




