
 This blog examines MySQL 5.7’s primary key lookup results, and determines if MySQL 5.7 is really faster than its early versions.
This blog examines MySQL 5.7’s primary key lookup results, and determines if MySQL 5.7 is really faster than its early versions.
MySQL 5.7 was released some time ago, and now that the dust has settled it’s a good time to review its performance improvements.
I’m not doing this just to satisfy my own curiosity! Many customers still running MySQL 5.6 (or even MySQL 5.5) often ask “How much performance gain we can expect by switching to 5.7? Or will it actually be a performance hit, especially after Peter’s report here: https://www.percona.com/blog/2013/02/18/is-mysql-5-6-slower-than-mysql-5-5/?”
To determine the answer, we’ll look at some statistics. There are a variety workloads to consider, and we will start with the simplest one: MySQL primary key lookup for data that fits into memory. This workload does not involve transactions and is fully CPU-bound.
The full results, scripts and configurations can be found on our GitHub page.
For this test, my server is a 56-logical-thread system (2 sockets / 14 cores each / 2 hyper-threads each) powered by “Intel(R) Xeon(R) E5-2683 v3 @ 2.00GHz” CPUs.
These are the primary results:
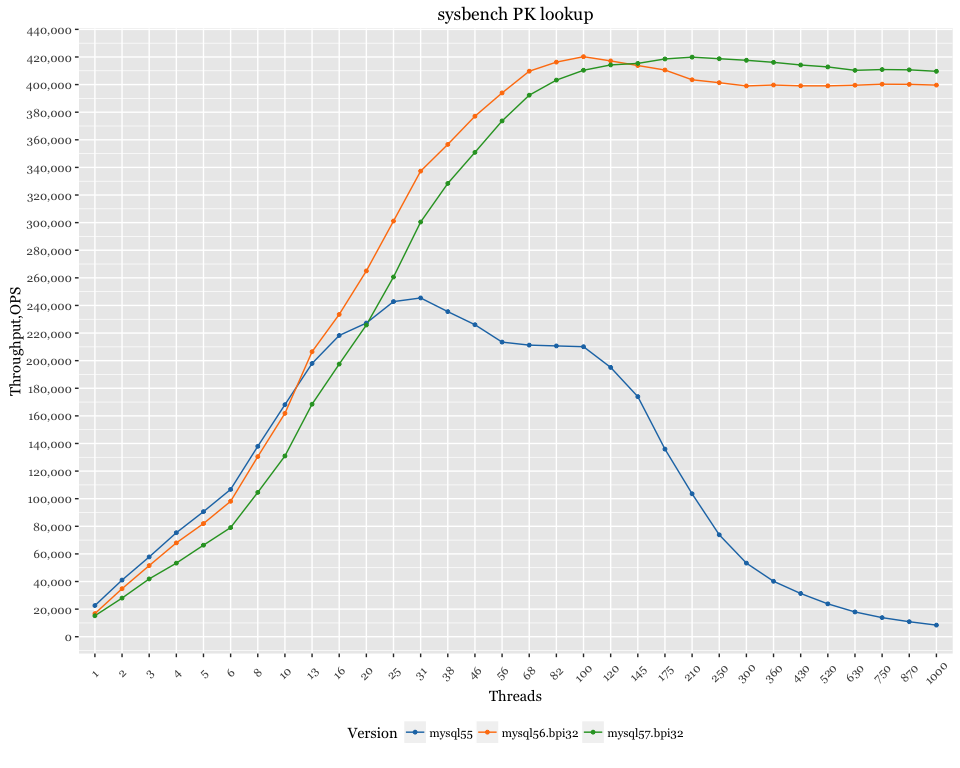
Up to 20 threads, MySQL 5.5 clearly outperforms MySQL 5.7. After 20 threads, however, it hits scalability issues and starts struggling with throughput. MySQL 5.6 is a different story – it outperforms 5.7 up to 120 threads. After that 120 threads, MySQL 5.7 again scales much better, and it can maintain throughput to all 1000 threads.
The above results are on a system where the client and server use the same server. To verify the results, I also ran the test on a system configuration where the client and server are located on different servers, connected via 10GB network.
Here results are the results from that setup: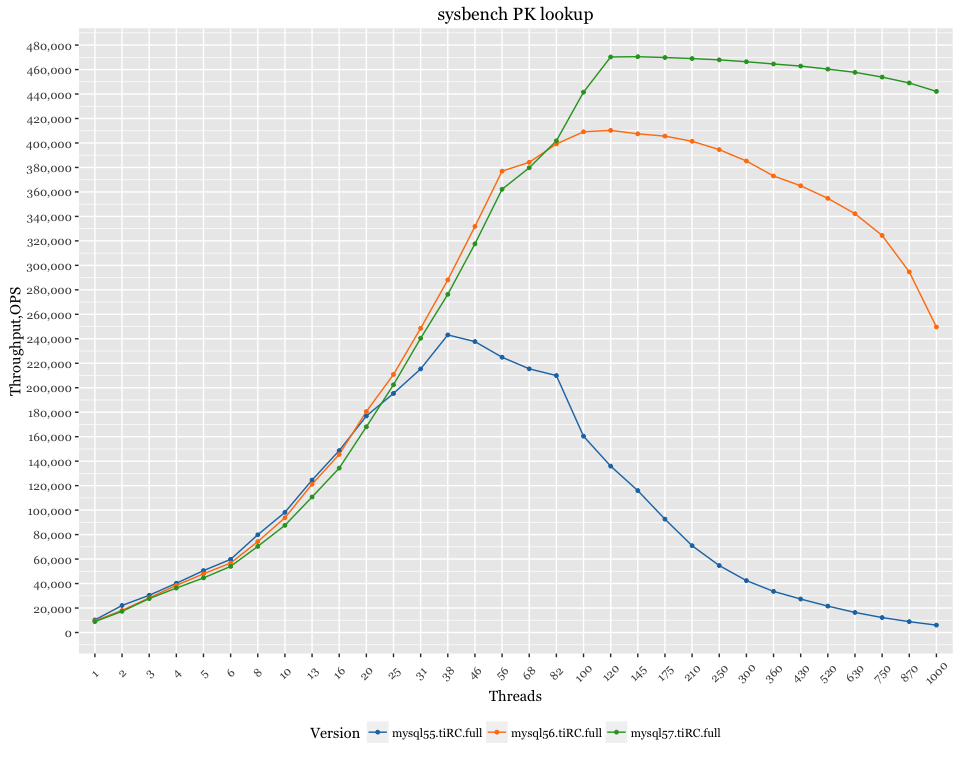
In this case, we pushed more load on the server (since the client does not share resources with MySQL), and we can see that MySQL 5.7 outperformed MySQL 5.6 after 68 threads (with MySQL 5.6 showing scalability problems even sooner).
There is another way to improve MySQL 5.6 results on large numbers of threads: good old innodb-thread-concurrency. Let’s see the MySQL 5.6 results after setting innodb-thread-concurrency=64:
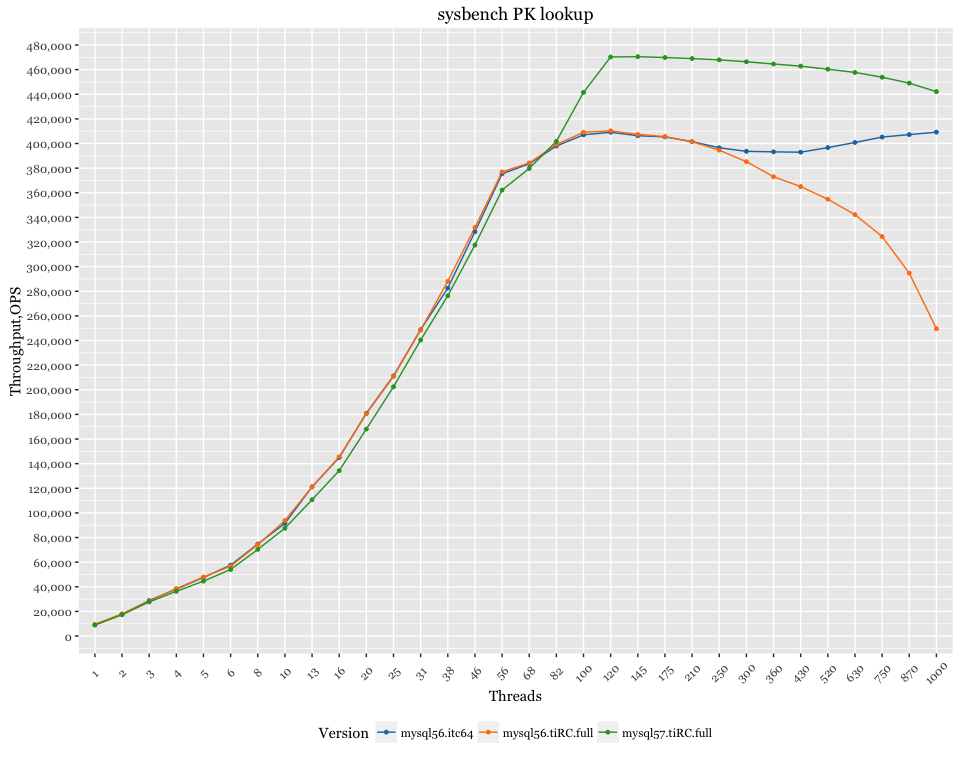
We can see that using innodb-thread-concurrency improves MySQL 5.6 results when getting into hundreds of threads.
While investigating ways to improve overall throughput, I found disabling PERFORMANCE_SCHEMA during MySQL startup is a good option. The numbers got better after doing so. Below are the numbers for 5.6 and 5.7 with PERFORMANCE_SCHEMA disabled.
For MySQL 5.6: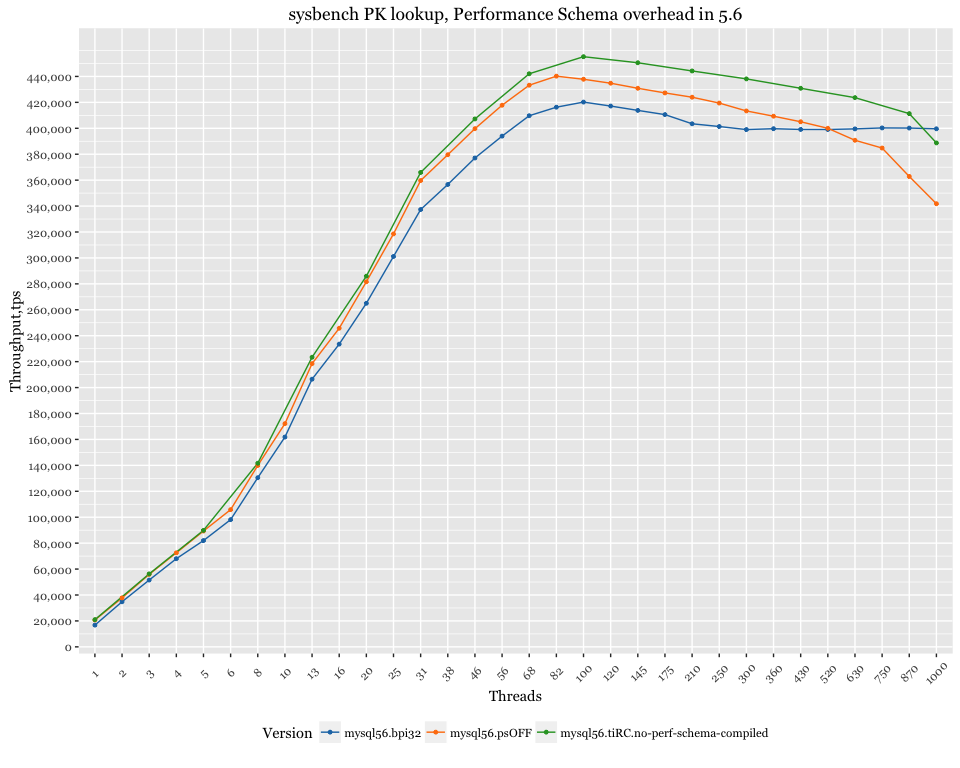
For MySQL 5.7: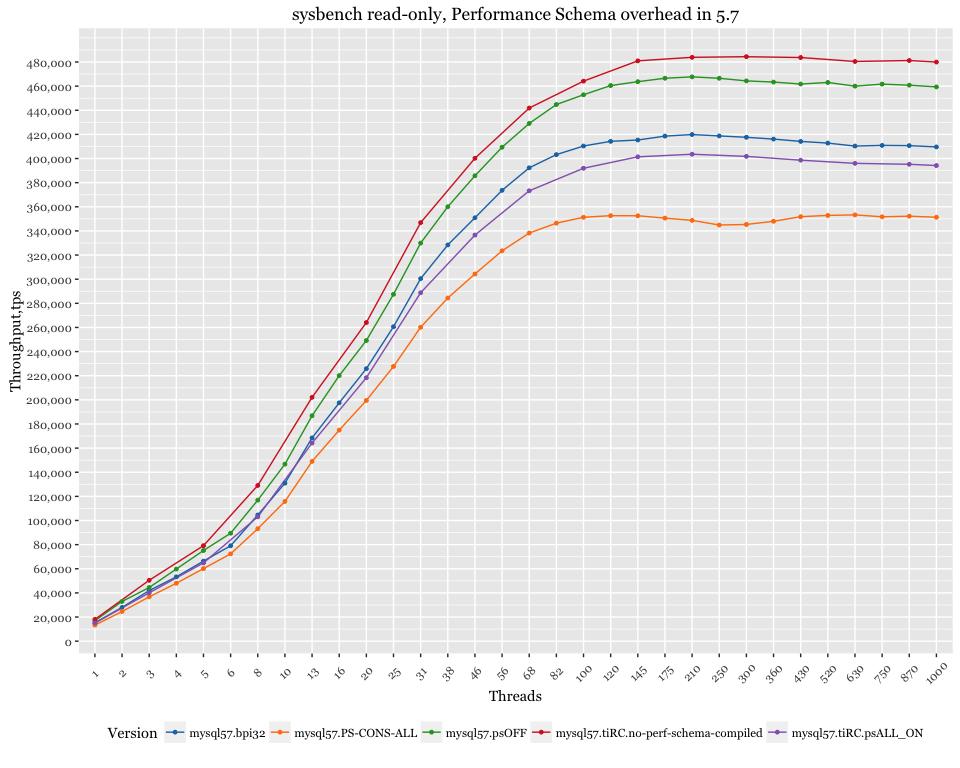
For MySQL 5.7, PERFORMANCE_SCHEMA’s overhead is quite visible.
Conclusions
I can say that Oracle clearly did a good job with MySQL 5.7, but they focused on primary keys lookups. They wanted to report 1.6M QPS.
I was not able to get to 1.6M; the best I could achieve was 470K QPS (with a disabled PERFORMANCE_SCHEMA). Full disclosure: I used sysbench 0.5 with LUA scripts and no prepared statements during this test. Oracle used the older sysbench 0.4 (with prepared statements), and their system had 144-logical threads.
MySQL 5.7, however, continues their tradition of slowness in low threads ranges. MySQL 5.6 was slower than MySQL 5.5, and MySQL 5.7 slower than MySQL 5.6.
PRIMARY KEY lookups aren’t the only workload type – there are many cases, some much more interesting! I will show the performance metrics for other workloads in upcoming posts.





With regards to PERFORMANCE_SCHEMA, I like to put it a different way. The overhead of around 10% is perfectly acceptable for production workloads. The amount of operational insight you get from P_S is well worth the cost.
SuperQ. Ok, I will not call it overhead, I will call it “measurement tax” from now.
Who is working on reducing the overhead from PS?
Who is working to improve low-concurrency performance?
I do not understand how the X axis is reported. the scale is move one ‘block’ from 1 to 2 and in the end one block is from 870 to 1000. That graph is tricky…
Pix,
X axis is “number of threads” used for user load. this is –num-thread in sysbench.
The scale for this axis is not linear, that’s probably why it is confusing.
Would be interested to see what kind of results you see using the same setup but utilizing either the handlersocket and/or memcache sockets. After all, the whole purpose is to measure PK lookups and that’s what they’re built for.