

NOTE: This blog post contains some mistakes in data. While many of our conclusions are still valid, we’ve updated the evaluation in a new blog post. Please use that post in conjunction with this one.
Vadim Tkachenko and I have been working with Fractal Tree® storage engines (Fractal Tree engines are available in Percona Server for MySQL and MongoDB as TokuDB and PerconaFT, respectively). While doing so, we’ve become interested evaluating database compression methods, to see how to make compression algorithms work even better than they do currently.
In this blog post, I will discuss what we found in our compression research.
Introduction
Before we get to evaluation database compression methods, let’s review what compression properties are most relevant to databases in general. The first thing to consider is compression and decompression performance. Databases tend to be very sensitive to decompression performance, as it is often done in the “foreground” – adding to client response latency. Compression performance, on the other hand, is less critical because it can typically run in the background without adding client latency. It can, however, cause an issue if the database fills its data compression queue and “chokes.” The database workload also affects compression performance demands. If the data is loaded only once and essentially becomes read only, it might make sense to spend extra time compressing it – as long as the better compression ratio is achieved without impact to decompression speed.
The next important thing to consider is the compression block size, which can significantly affect compression ratio and performance. In some cases, the compression block size is fixed. Most InnoDB installations, for example, use a 16KB block size. In MySQL 5.7 it is possible to change block size from 4KB to 64KB, but since this setting applies to the whole MySQL instance it isn’t commonly used. TokuDB and PerconaFT allow a much more flexible compression block size configuration. Larger compression block sizes tend to give a better compression ratio and may be more optimal for sequential scan workloads, but if you’re accessing data in a random fashion you may see significant overhead as the complete block typically must be decompressed.
Of course, compression will also depend on the data you’re compressing, and different algorithms may be more optimal at handling different types of data. Additionally, different data structures in databases may structure data more or less optimally for compression. For example, if a database already implements prefix compression for data in the indexes, indexes are likely to be less compressible with block compression systems.
Let’s examine what choices we have when it comes to the compression algorithm selection and configuration. Typically for a given block size – which is essentially a database configuration setting – you will have a choice to select the compression algorithm (such as zlib), the library version and the compression level.
Comparing different algorithms was tough until lzbench was introduced. Izbench allows for a simple comparison of different compression libraries through a single interface.
For our test, we loaded different kinds of data in an uncompressed InnoDB table and then used it as a source for lzbench:
|
1 |
./lzbench -equicklz,1/zstd,1/snappy/lzma,1/zlib,1/lz4,1/brotli,1 -o3 -b16 data.ibd |
This method is a good way to represent database structures and is likely to be more realistic than testing compression on the source text files.
All results shown here are for “OnTime Air Performance.” We tried a variety of data, and even though the numbers varied the main outcomes are the same. You can see results for our other data types in this document.
The results for compression are heavily CPU dependent. All the data below is single thread compression benchmarks run on an Intel Xeon E5-2643 v2 @ 3.5Ghz.
Below are some of the most interesting results we found.
Comparing Compression Algorithms
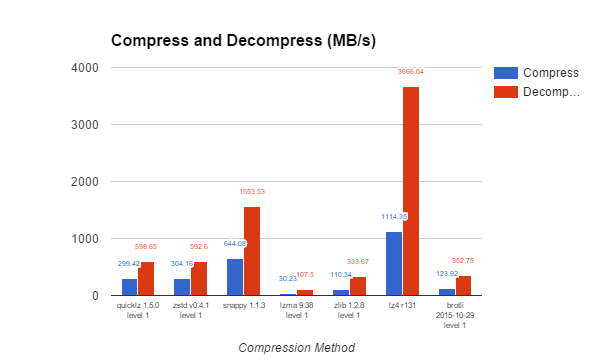
Using a standard 16KB block size and a low level of compression, we can see that there is a huge variety of compression and decompression speed. The results ranged from 30MB per second for LZMA to more than 1GB per second for LZ4 for compression, and 100MB per second and 3.5GB per second for decompression (for the same pair).
Now let’s look at the compression ratios achieved.
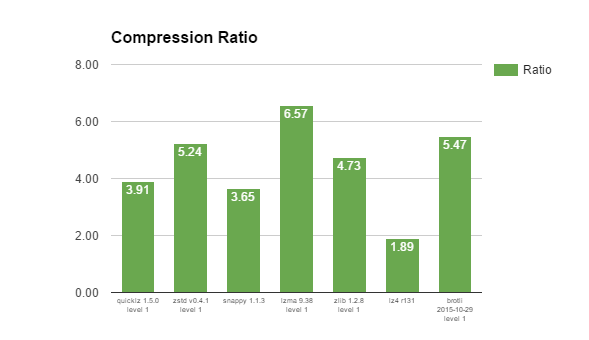
You can see a large variety of outcomes for this data set as well, with ratios ranging from 1.89:1 (LZ4) to 6.57:1 (LZMA). Notice how the fastest and slowest compression libraries achieve the worst and best compression: better compression generally comes at disproportionately more CPU usage. Achieving 3.5 times more compression (LZMA) requires spending 37 times more CPU resources. This ratio, though, is not at all fixed: for example, Brotli provides 2.9 times better compression at 9 times higher CPU cost while Snappy manages to provide 1.9 times better compression than LZ4 with only 1.7 times more CPU cost.
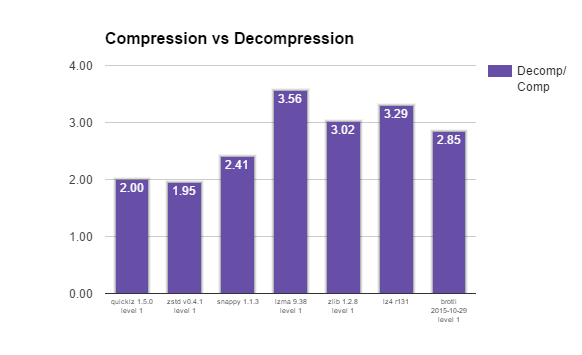
Another interesting compression algorithm property is how much faster decompression is than compression. It is interesting to see there is not as large a variance between compression algorithms, which implies that the default compression level is chosen in such a way that compression is 2 to 3.5 times slower than decompression.
Block Size Impact on Compression
Now let’s look at how the compression block size affects compression and decompression performance.
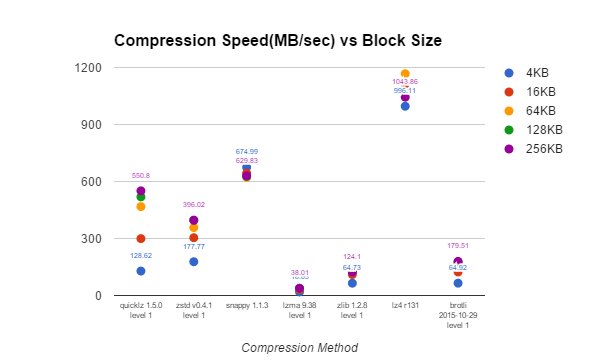
| On-Time Performance Data Compression Speed vs Block Size (MB/sec) | ||||||
| Compression Method | 4KB | 16KB | 64KB | 128KB | 256KB | 256KB/4KB |
| quicklz 1.5.0 level 1 | 128.62 | 299.42 | 467.9 | 518.97 | 550.8 | 4.28 |
| zstd v0.4.1 level 1 | 177.77 | 304.16 | 357.38 | 396.65 | 396.02 | 2.23 |
| snappy 1.1.3 | 674.99 | 644.08 | 622.24 | 626.79 | 629.83 | 0.93 |
| lzma 9.38 level 1 | 18.65 | 30.23 | 36.43 | 37.44 | 38.01 | 2.04 |
| zlib 1.2.8 level 1 | 64.73 | 110.34 | 128.85 | 124.74 | 124.1 | 1.92 |
| lz4 r131 | 996.11 | 1114.35 | 1167.11 | 1067.69 | 1043.86 | 1.05 |
| brotli 2015-10-29 level 1 | 64.92 | 123.92 | 170.52 | 177.1 | 179.51 | 2.77 |
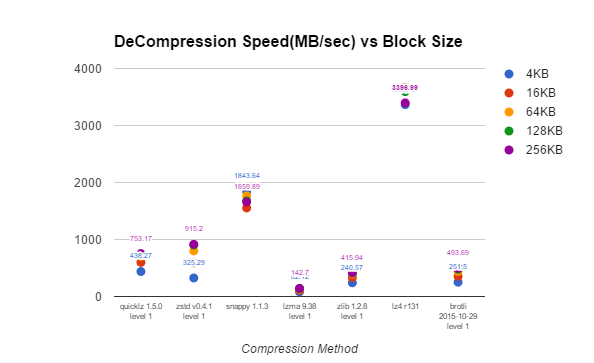
| On-Time Performance Data Compression Speed vs Block Size (MB/sec) | ||||||
| Compression Method | 4KB | 16KB | 64KB | 128KB | 256KB | 256KB/4KB |
| quicklz 1.5.0 level 1 | 128.62 | 299.42 | 467.9 | 518.97 | 550.8 | 4.28 |
| zstd v0.4.1 level 1 | 177.77 | 304.16 | 357.38 | 396.65 | 396.02 | 2.23 |
| snappy 1.1.3 | 674.99 | 644.08 | 622.24 | 626.79 | 629.83 | 0.93 |
| lzma 9.38 level 1 | 18.65 | 30.23 | 36.43 | 37.44 | 38.01 | 2.04 |
| zlib 1.2.8 level 1 | 64.73 | 110.34 | 128.85 | 124.74 | 124.1 | 1.92 |
| lz4 r131 | 996.11 | 1114.35 | 1167.11 | 1067.69 | 1043.86 | 1.05 |
| brotli 2015-10-29 level 1 | 64.92 | 123.92 | 170.52 | 177.1 | 179.51 | 2.77 |
If we look at compression and decompression speed versus block size, we can see that there is a difference both for compression and decompression, and that it depends a lot on the compression algorithm. QuickLZ, using these settings, compresses 4.3 times faster with 256KB blocks rather than 4KB blocks. It is interesting that LZ4, which I would consider a “similar” fast compression algorithm, is not at all similar, demonstrating only minimal changes in compression and decompression performance with increased block size.
Snappy is perhaps the most curious compression algorithm of them all. It has lower performance when compressing and decompressing larger blocks.
Let’s examine how compression ratio varies with different block sizes.
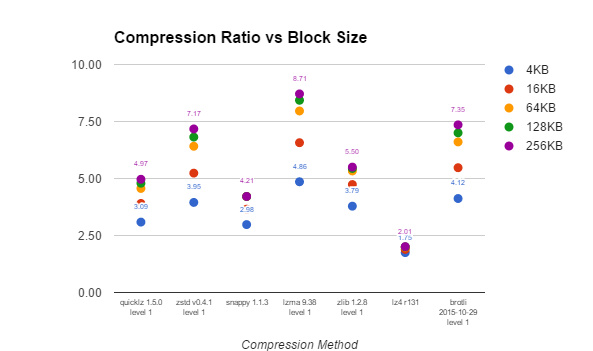
| On-Time Performance Data DeCompression Ratio vs Block Size | ||||||
| Compression Method | 4KB | 16KB | 64KB | 128KB | 256KB | 256KB/4KB |
| quicklz 1.5.0 level 1 | 3.09 | 3.91 | 4.56 | 4.79 | 4.97 | 1.61 |
| zstd v0.4.1 level 1 | 3.95 | 5.24 | 6.41 | 6.82 | 7.17 | 1.82 |
| snappy 1.1.3 | 2.98 | 3.65 | 4.21 | 4.21 | 4.21 | 1.41 |
| lzma 9.38 level 1 | 4.86 | 6.57 | 7.96 | 8.43 | 8.71 | 1.79 |
| zlib 1.2.8 level 1 | 3.79 | 4.73 | 5.33 | 5.44 | 5.50 | 1.45 |
| lz4 r131 | 1.75 | 1.89 | 1.99 | 2.00 | 2.01 | 1.15 |
| brotli 2015-10-29 level 1 | 4.12 | 5.47 | 6.61 | 7.00 | 7.35 | 1.78 |
We can see all the compression libraries perform better with larger block sizes, though how much better varies. LZ4 only benefits a little from larger blocks, with only a 15% better compression ratio between 4KB to 256KB, while Zstd, Brotli and LZMA all get about an 80% better compression ratio with large block sizes. This is another area where I would expect results to be data dependent. With highly repetitive data, gains are likely to be more significant with larger block sizes.
Compression library gains from larger block sizes decrease as the base block sizes increase. For example most compression libraries are able to get at least a 20% better compression ratio going from 4KB to 16KB block size, however going from 64KB to 256KB only allows for a 4-6% better compression ratio – at least for this data set.
Compression Level Impact
Now let’s review what the compression level does to compression performance and ratios.
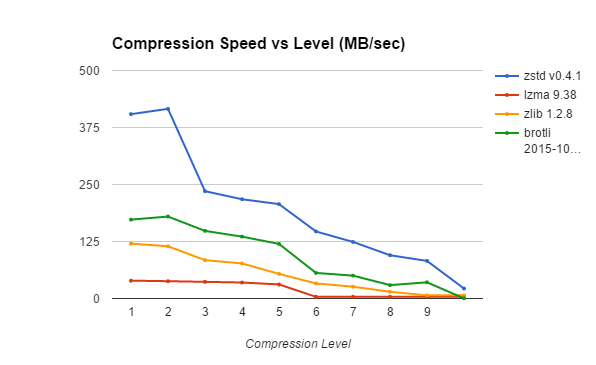
| Compression Method | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Max |
| zstd v0.4.1 | 404.25 | 415.92 | 235.32 | 217.69 | 207.01 | 146.96 | 124.08 | 94.93 | 82.43 | 21.87 |
| lzma 9.38 | 39.1 | 37.96 | 36.52 | 35.07 | 30.85 | 3.69 | 3.69 | 3.69 | 3.69 | 3.69 |
| zlib 1.2.8 | 120.25 | 114.52 | 84.14 | 76.91 | 53.97 | 33.06 | 25.94 | 14.77 | 6.92 | 6.92 |
| brotli 2015-10-29 | 172.97 | 179.71 | 148.3 | 135.66 | 119.74 | 56.08 | 50.13 | 29.4 | 35.46 | 0.39 |
Note. Not every compression algorithm provides level selection, so we’re only looking at the ZSTD, LZMA, ZLIB and BROTLI compression libraries. Also, not every library provides ten compression levels. If more than ten levels were available, the first nine and the maximum compression level were tested. If less than ten levels were available (like LZMA), the result for the maximum compression level was used to fill the gaps.
As you might expect, higher compression levels generally mean slower compression. For most compression libraries, the difference between the fastest and slowest compression level is 10-20 times – with the exception of Brotli where the highest compression level means really slow compression (more than 400 times slower than fastest compression).
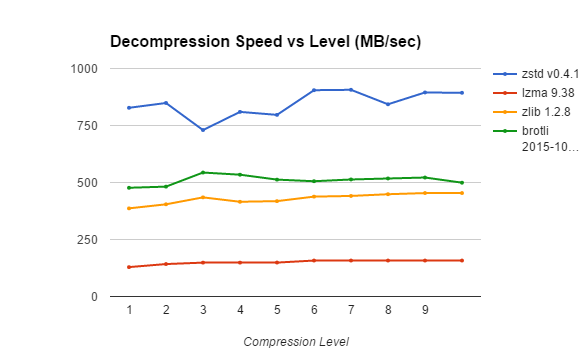
| Compression Method | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Max |
| zstd v0.4.1 | 827.61 | 848.71 | 729.93 | 809.72 | 796.61 | 904.85 | 906.55 | 843.01 | 894.91 | 893.31 |
| lzma 9.38 | 128.91 | 142.28 | 148.57 | 148.72 | 148.75 | 157.67 | 157.67 | 157.67 | 157.67 | 157.67 |
| zlib 1.2.8 | 386.59 | 404.28 | 434.77 | 415.5 | 418.28 | 438.07 | 441.02 | 448.56 | 453.64 | 453.64 |
| brotli 2015-10-29 | 476.89 | 481.89 | 543.69 | 534.24 | 512.68 | 505.55 | 513.24 | 517.55 | 521.84 | 499.26 |
This is where things get really interesting. With a higher compression level, decompression speed doesn’t change much – if anything becomes higher. If you think about it, it makes sense: during the compression phase we’re searching for patterns in data and building some sort of dictionary, and extensive pattern searches can be very slow. Decompression, however, just restores the data using the same dictionary and doesn’t need much time finding data patterns. The smaller the compressed data size is, the better the performance should be.
Let’s examine the compression ratio.
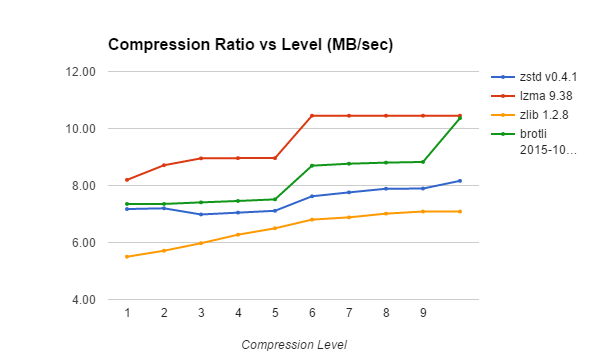
| Compression Method | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | Max |
| zstd v0.4.1 | 7.17 | 7.20 | 6.98 | 7.05 | 7.11 | 7.62 | 7.76 | 7.89 | 7.89 | 8.16 |
| lzma 9.38 | 8.20 | 8.71 | 8.95 | 8.96 | 8.96 | 10.45 | 10.45 | 10.45 | 10.45 | 10.45 |
| zlib 1.2.8 | 5.50 | 5.71 | 5.97 | 6.27 | 6.50 | 6.80 | 6.88 | 7.01 | 7.09 | 7.09 |
| brotli 2015-10-29 | 7.35 | 7.35 | 7.41 | 7.46 | 7.51 | 8.70 | 8.76 | 8.80 | 8.83 | 10.36 |
As we can see, higher compression levels indeed improve the compression ratio most of the time. The ZSTD library seems to be some strange exception where a higher level of compression does not always mean a better ratio. We can also see that BROTLI’s extremely slow compression mode can really produce a significant boost to compression, getting it to the level of compression LZMA achieves – quite an accomplishment.
Different compression levels don’t have the same effect on compression ratios as different compression methods do. While we saw a 3.5 times compression rate difference between LZ4 and LZMA, the highest compression rate difference between the fastest and slowest mode is 1.4x for Brotli – with 20-30% improvement in compression ratio more likely.
An important point, however, is that the compression ratio improvement from higher compression levels comes at no decompression slowdown – in contrast to using a more complicated compression algorithm to achieve better compression.
In practice, this means having control over the compression level is very important, especially for workloads where data is written once and read frequently. In that case, you could choose a higher compression leves rather than change and recompress the data frequently. Another factor is that the compression level is very easy to change dynamically, unlike the compression algorithm. In theory, a database engine could dynamically choose the compression level based on the workload – a higher compression level can be used if there are a lot of CPU resources available, and a lower compression level can be used if the system can’t keep up with compressing data.
Records
It is interesting to note a few records generated from all of these tests. Among all the methods tried, the lowest compression ratio was LZ4 with a 4KB block size, providing a 1.75 compression ratio. The highest ration was LZMA with a 256K block size, providing a maximum compression ratio of 10.45.
LZ4 is fastest both in compression and decompression, showing the best compression speed of 1167MB per second with a 64KB block size, and a decompression speed of 3666MB per second with a 16KB block size.
LZMA appears to generally be the slowest compression and decompression, compressing at 0.88MB per second with a 16KB block size and the maximum compression level. It decompresses at 82MB per second with a 4KB block size. Only Brotli at the highest compression level compressed data slower (at 0.39MB per second).
Looking at these we see three orders of magnitude difference in compression performance, and 50 times in decompression performance. This demonstrates how the right compression algorithms choices and settings can make or break compression for your application.
Recommendations
Data and Details
Raw results, data sources and additional details for our evaluation of database compression methods are available in Google Docs.




Hi Peter
im dealing with a MySQL 5.7.11 on Windows Server 2008 64 bit and having trouble with punch hole support on Windows. innodb_page_size is 32k and the NTFS filesystem have been formatted with 2Kb blocks. While creating the table , a warning is displayed that the FS doesnt support hole puching. I’ve tried to enable disk compression on the volume, but the issue persists. Are there any step by step guide on how to do this on Windows? IM going to try with 1Kb NTFS blocks since 16Kb is the default
Thanks!!
By the way, excellent article. Its really nice to think about that we could trade off some CPU usage in order to speed up databases in general, while saving some money on storage size, since SSD still is a price sensitive matter. Even LZ4 seems to me a possibility to be enabled by default. No serious database today doesnt count compression as its most basic toolset
The only thing i feel lacking today is more flexibilization with incremental batch load. It should be an option to load data into separate pages (even reading original data) without touching the original pages and then just at the end flush the whole change into logs (ideallly compressed)