
 Unlike MySQL 5.6, where parallel replication can only be used when replicas have several schemas, MySQL 5.7 replicas can read binlog group commit information coming from the master to replicate transactions in parallel even when a single schema is used. Now the question is: how many replication threads should you use?
Unlike MySQL 5.6, where parallel replication can only be used when replicas have several schemas, MySQL 5.7 replicas can read binlog group commit information coming from the master to replicate transactions in parallel even when a single schema is used. Now the question is: how many replication threads should you use?
Let’s assume we have one master and three slaves, all running MySQL 5.7.
One slave is using regular single-threaded replication (the control slave in the graph below), one is using 20 parallel workers (MTS 20 workers) and the last one is using 100 parallel workers (MTS 100 workers).
As a reminder, here is the settings that need to be adjusted for 5.7 parallel replication:
|
1 2 |
slave_parallel_type = LOGICAL_CLOCK slave_parallel_workers = 20 |
GTID replication is also highly recommended, if you don’t want to face annoying issues.
Now let’s run a simple sysbench workload, inserting records in 25 separate tables in the same database with 100 concurrent threads:
|
1 |
sysbench --mysql-user=root --mysql-db=db1 --test=/usr/share/doc/sysbench/tests/db/insert.lua --max-requests=500000 --num-threads=100 --oltp-tables-count=25 run |
Because we’re using 100 concurrent threads on the master, we can expect that some parallelization is possible. This means that if we see replication lag with the control slave, we’ll probably see less lag with the 20-worker slave and even less with the 100-worker slave.
This is not exactly what we get:
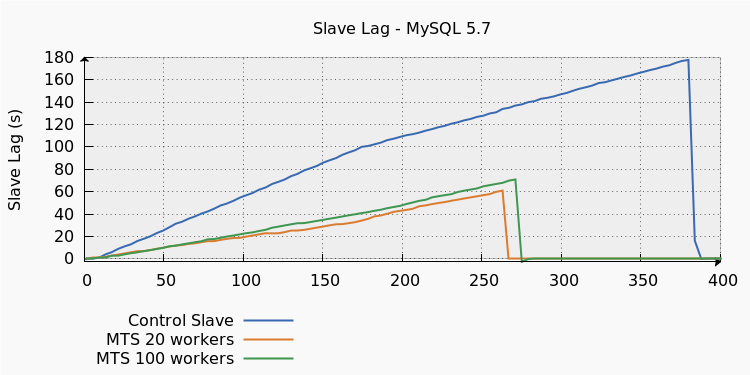
Parallel replication is indeed useful, but the 100-worker slave doesn’t provide any benefits compared to the 20-worker slave. Replication lag is even slightly worse.
What happened?
To have a better understanding of how efficiently the parallel replication threads are used, let’s enable some instrumentation on slaves (in other words, recording executed transactions):
|
1 2 3 4 5 |
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE 'events_transactions%'; UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' WHERE NAME = 'transaction'; |
For better readability of the results, let’s create a new view (tracking how many transactions are executed by each replication thread):
|
1 2 3 4 5 6 |
CREATE VIEW mts_summary_trx AS select performance_schema.events_transactions_summary_by_thread_by_event_name.THREAD_ID AS THREAD_ID, performance_schema.events_transactions_summary_by_thread_by_event_name.COUNT_STAR AS COUNT_STAR from performance_schema.events_transactions_summary_by_thread_by_event_name where performance_schema.events_transactions_summary_by_thread_by_event_name.THREAD_ID in (select performance_schema.replication_applier_status_by_worker.THREAD_ID from performance_schema.replication_applier_status_by_worker); |
Now, after running sysbench again, let’s do some math to see how often each replication thread was run:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
SELECT SUM(count_star) FROM mts_summary_trx INTO @total; SELECT 100*(COUNT_STAR/@total) AS PCT_USAGE FROM mts_summary_trx; +-----------+ | PCT_USAGE | +-----------+ | 39.5845 | | 31.4046 | | 12.0119 | | 5.9081 | | 3.0375 | | 1.6527 | | 1.0550 | | 0.7576 | | 0.6089 | | 0.5208 | | 0.4642 | | 0.4157 | | 0.3832 | | 0.3682 | | 0.3408 | | 0.3247 | | 0.3076 | | 0.2925 | | 0.2866 | | 0.2749 | +-----------+ |
We can see that the workload has a limited potential for parallelism – therefore, it’s not worth configuring more than 3-4 replication threads.
The slight performance degradation with 100 replication threads is probably due to the overhead of the coordinator thread.
Estimating the optimal number of replication threads with MySQL 5.7 parallel replication is quite difficult if you’re just guessing. The performance_schema provides a simple way to understand how the workload is handled by the replication threads.
It also allows you to see if tuning binlog_group_commit_sync_delay provides more throughput on slaves without too much impact on the master’s performance.





Stephane,
You use 25 tables.
Why can slave can do only 4 threads in parallel ?
Vadim,
I was surprised by the result too and I don’t have a good explanation. The workload may be too simple with INSERTs running too fast to get any chance to get committed in parallel on the master.
If I have time, I’ll try to run the same test but with a different workload (like UPDATEs with a secondary key).
Hi Stephane,
Maybe some more tuning is possible to improve performance.
– Tuning
binlog_group_commit_sync_delayandbinlog_group_commit_sync_no_delay_count(and keepingsync_binlog=1) on the master could increase group commits and increase the potential to execute queries in parallel. In MariaDB you can actually see status of how good much group commit is happening by looking atBinlog_commitsandBinlog_group_commits(don’t know yet how to do that in MySQL 5.7).– Having a larger
slave_pending_jobs_size_maxon the slave might increase performance as well, allthough I think that’s not the case in your test.Stéphan, very nice blog post, congrats!
Can you do the same test but having master configured with:
[mysqld]
binlog_group_commit_sync_delay=1000000 (default value)
binlog_group_commit_sync_no_delay_count=20
and then, slaves with:
slave_parallel_type = LOGICAL_CLOCK
slave_parallel_workers = 20
I think the big improvement as well as tested by Vadim before is the writeback cache
https://www.percona.com/blog/2011/07/13/testing-the-group-commit-fix/
Thanks.
How many cores do the slaves have? Looks like 4? This might be the answer to why the config 4 SQL threads on slave is optimal.
See also http://thenoyes.com/littlenoise/?p=525 for another way to glean similar information from the binary log.
Typo: “quite difficult if your just guessing.”, should be “you’re”.